David Wadden retweetledi

We are launching HALoGEN💡, a way to systematically study *when* and *why* LLMs still hallucinate.
New work w/ @shrusti_ghela* @davidjwadden @YejinChoinka 💫
🧵 [1/n]

English
David Wadden
53 posts

@davidjwadden
Graduate student at @uwcse studying NLP.









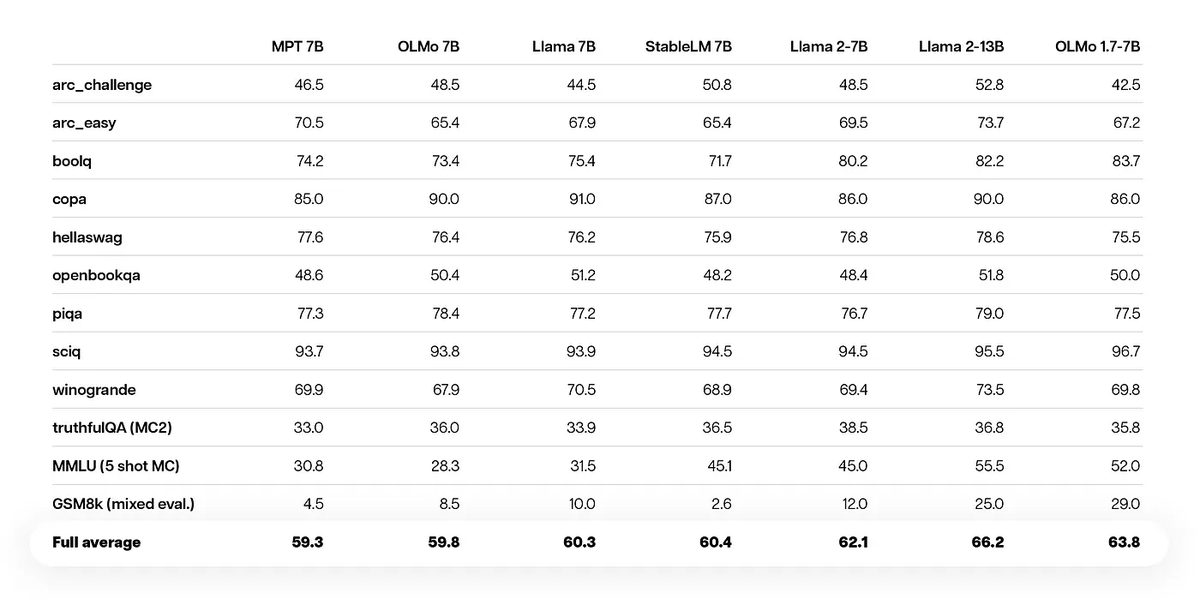
Announcing our latest addition to the OLMo family, OLMo 1.7!🎉Our team's efforts to improve data quality, training procedures and model architecture have led to a leap in performance. See how OLMo 1.7 stacks up against its peers and peek into the technical details on the blog: blog.allenai.org/olmo-1-7-7b-a-…

Does arXiving have a casual effect on acceptance? The answer is nuanced, and depends on what assumptions you are willing to make, but arguably more importantly, we observe no difference in acceptance for different groups. arxiv.org/abs/2306.13891








ACL has removed the anonymity period. This means that ACL submissions can be posted and discussed online at any time, although extensive PR is discouraged. aclweb.org/adminwiki/imag…



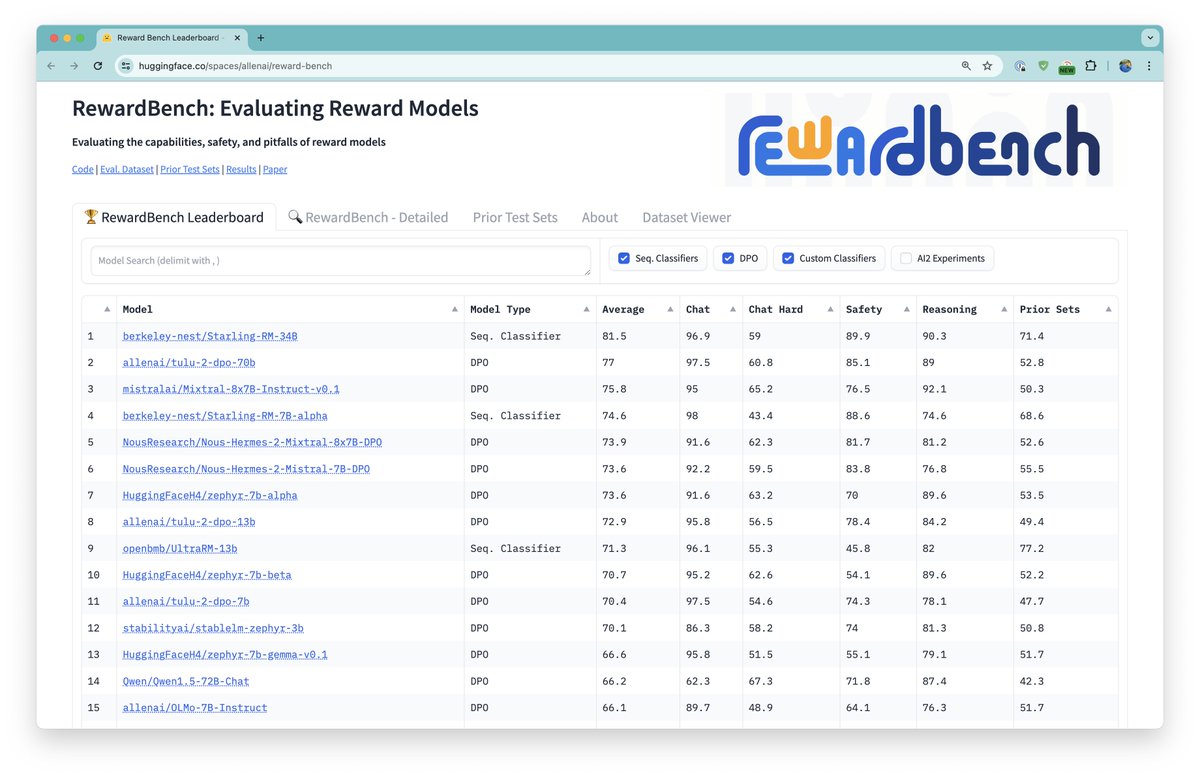
Check out our new 70B DPO model here: huggingface.co/allenai/tulu-2… AFAIK currently the best model on AlpacaEval with a public finetuning set! More details once the AI sphere calms down a bit... 😅




Each time a paper gets rejected, you can't help but think "I'll never succeed as a researcher" Such negative thoughts are normal, but how can we overcome them? Our #ACL2023 📰 studies Human-LM Interaction for Cognitive Reframing of Negative Thoughts arxiv.org/abs/2305.02466 🧵


