Benjamin F Spector retweetledi

megakernels remain underrated. if you haven’t dug into them before go look them up! flappy seems to be hinting at some really powerful training megakernel stuff which is sick
ex: fully contained training megakernel could be great for automated research
Flapping Airplanes@flappyairplanes
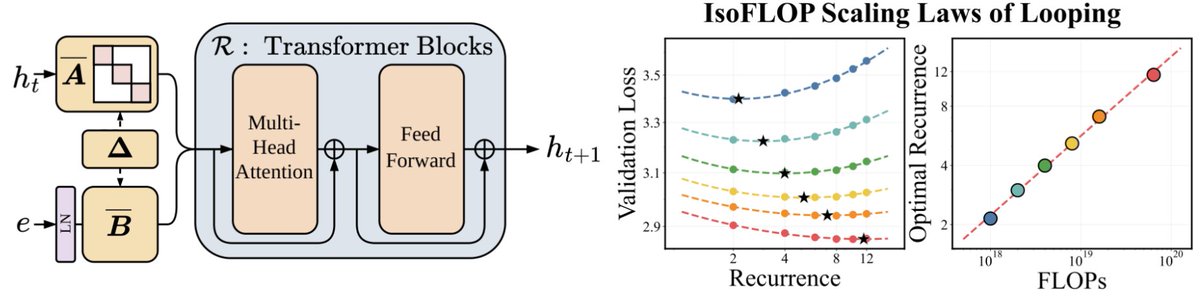
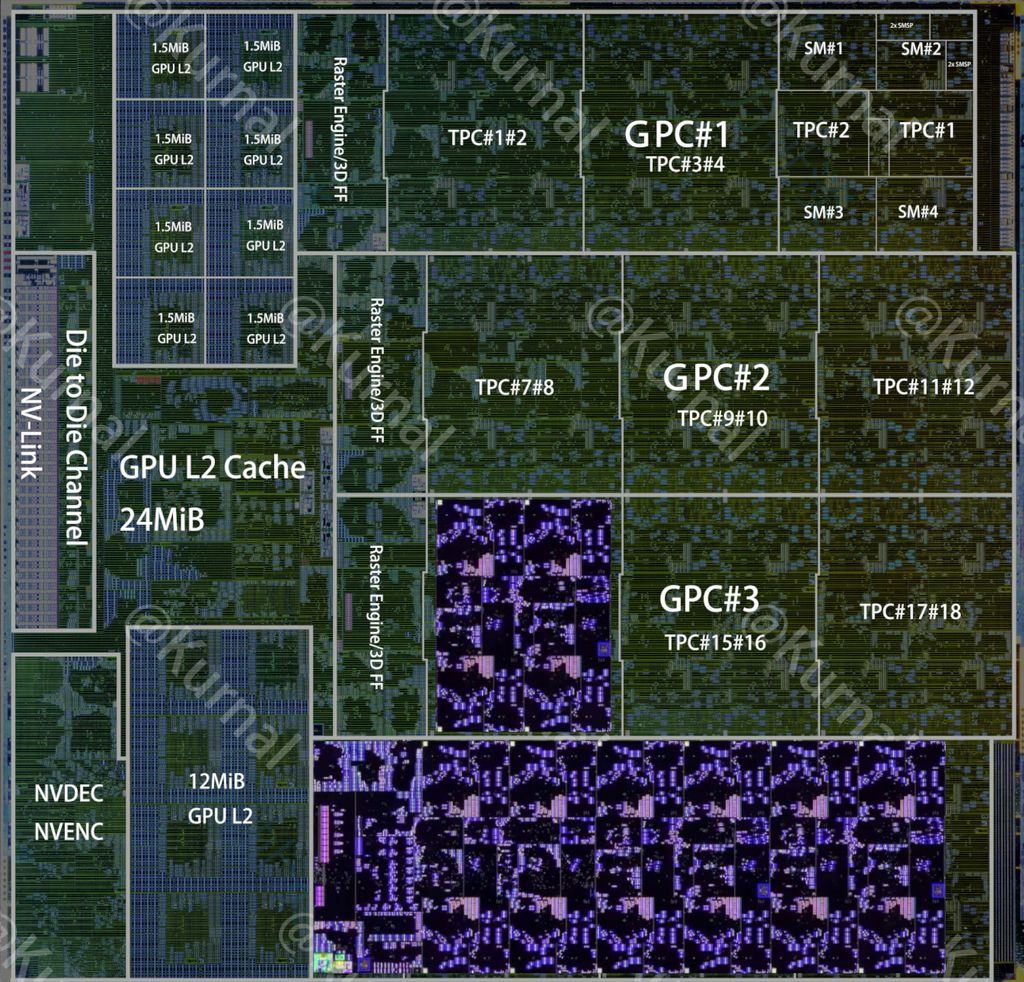
(4/5) One thing we’ve built is a “kittens” virtual machine that takes over the whole GPU and allows new kinds of co-optimization. We can go past the traditional sequential kernel model – for example, fusing entire training runs into a single kernel and even weirder stuff.
English