7th
411 posts


7th
@fw7th
ml • mechE • plus ultra and things of that nature
Konohakagure Beigetreten Ağustos 2024
37 Folgt41 Follower
@laurathesimp The answer is simply; balls of steel. Something you don't seem to possess
English



what the actual fuck is he talking about
Shubham Saboo@Saboo_Shubham_
“OpenClaw is the iPhone of tokens” — Nvidia CEO on Lex Podcast
English





@realcryobyte @schteppe Forgot to add "make no mistaes, I give you the power of 4 senior develops",
rookie mistake
English


@wildmindai what kind of algorithm is used for gazing, it seems about like temporal averaging or optical flow
English

NVIDIA says: no more "brute force every pixel" of video understanding.
AutoGaze- identifies and removes redundant video patches before they enter a Vision Transformer.
Now we can processes 4K long-video in real-time.
Works with SigLIP2 and NVILA.
autogaze.github.io
English
@probnstat What kind of data?
And what are the inductive biases of deep net?
What's our measure of performance?
I think further questions would need to be asked no?
English

ML interview drill:
You’re given a dataset with 1M samples, 100 features.
A complex model (deep net) gives worse test performance than logistic regression.
What’s the MOST likely reason?
A) Underfitting
B) Overfitting
C) Bad optimization
D) Data leakage
Reply with your answer!
Bonus:
Name 2 concrete steps you’d take to improve the deep model.
English

i miss the pre agentic AI era, now every repo is filled with slop PRs(even major ones like vllm/sglang).
by the time you read the issue and trace the data flow, theres already a slop PR with 999 lines of code.
it must really suck for the repo maintainers.
English
@dogecahedron say i had 3 rows and 2 cols, I would store stride=2 (row major), then "append" subsequent rows, but how do you scale it to n-D?
English

nice going cpu first is a good decision.
its honestly easy to go from 2D to N-D just for each 1d buffer you store the View as a list of dim+stride. a stride tells you how many steps you take in the buffer for each step along a tensor dimension. in your case stride=1 for the columns and then stride = NColumns for the rows. but this pattern generalizes to more dimensions
English
@dogecahedron lemme my understanding; stride will allow me to traverse along one dim, and then subsequent rows/cols along that same dim so I store it as a contiguous array in memory?
English
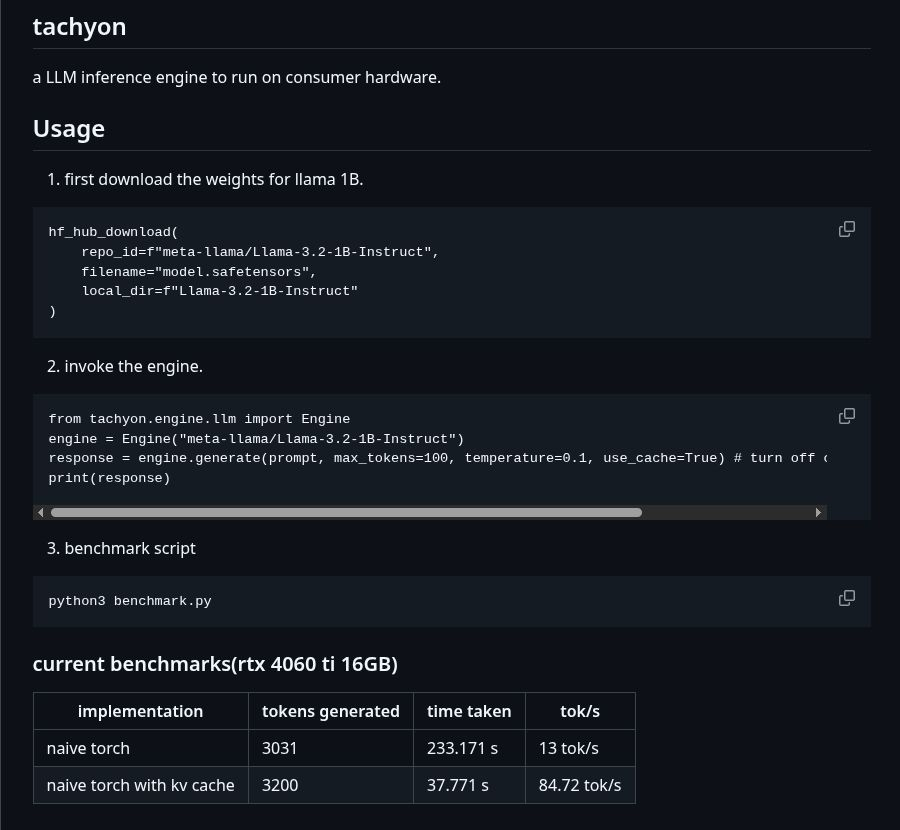
day 16 of ml systems and gpu programming
im building tachyon - a lightweight LLM inference engine to run on consumer hardware. im treating this a playground for ideas i read up and implement them into making it an actual inference engine. the library itself is quite readable, the concepts spelled out and everything benchmarked to reproduce.
currently it has a llama 3.2 1B instruct model running at 84.7 tokens/sec with kv caching on a rtx 4060. it takes only 3 lines to run!
English