
Miha
4.9K posts

Miha
@mihar
Building things ⋅ @linear ⋅ @coinbase ⋅ YCS11
Austin, TX ⋅ Ljubljana Beigetreten Mart 2008
647 Folgt2K Follower

When I'm out and about in the world, people recognize me from IG or YouTube at a 20:1 ratio to X.
Outside of SF, an X user in the wild is a rare sighting which is strange given how much surface area X seems to occupy.
The X paradox: where is everyone?
English

@localghost SETI@home but with iPhones sitting in chargers all night long….
English

"The ANE delivers 6.6 TFLOPS per watt, roughly 80x more efficient than an Nvidia A100."
Wow.
anand iyer@ai
Karpathy's llama2.c showed you could train a real transformer in pure C with no frameworks. A solo researcher (and Claude Code) just took that same model, Stories 110M, Llama2 architecture, trained on real text and ran it on Apple's M4 Neural Engine (ANE) for less than a watt. He reverse-engineered the undocumented private APIs, bypassed CoreML, and found Apple's abstraction layer was hiding 2-4x of the chip's real throughput. The ANE delivers 6.6 TFLOPS per watt, roughly 80x more efficient than an Nvidia A100. The real implication here is inference: there are hundreds of millions of Apple devices with one of the most efficient AI accelerators ever shipped in consumer hardware, and Apple's own software stack is the thing standing between developers and its actual performance. h/t @maderix
English
Miha retweetet

"We used to debate using tabs vs spaces in code we'd type out"

English
@LeaderBriefs @openclaw @steipete yeah memory works sloppy at best, crons can be good
maybe it's fixed now but it would compact and lose context, or would post from cron and i reply and it would have no idea what i'm talking about...
ymmw
English



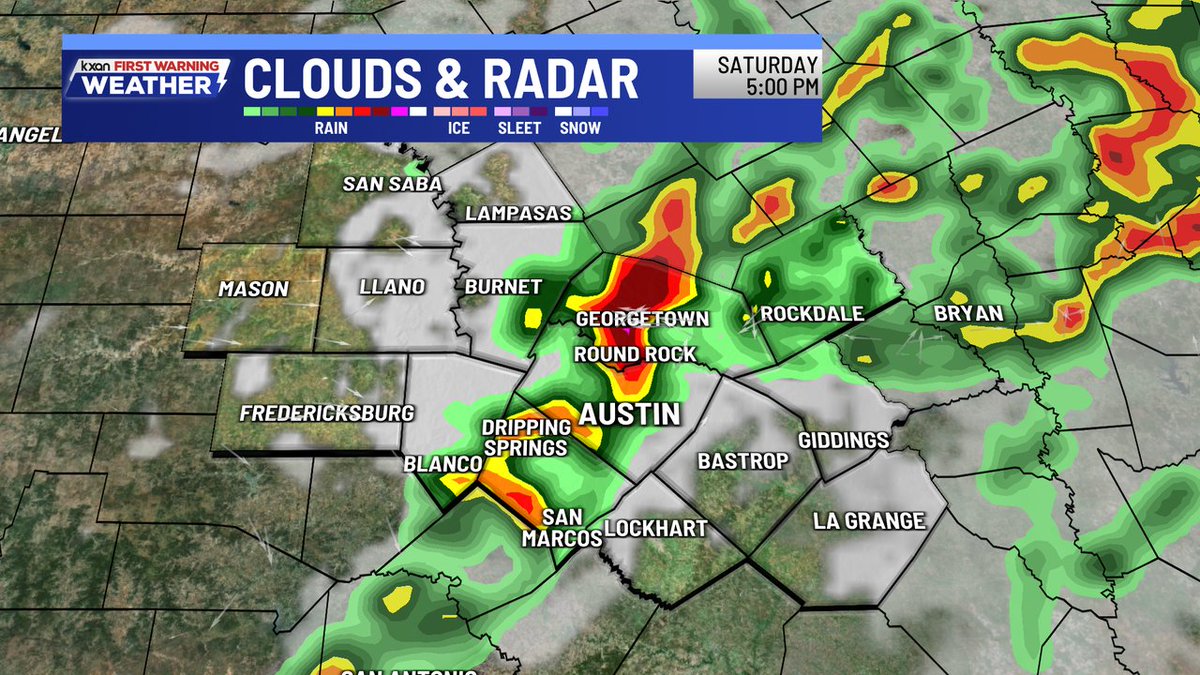
STORMS: Widespread showers are expected tomorrow morning, followed by isolated strong to severe thunderstorms during the late afternoon and evening hours. Large hail, gusty winds, and an isolated tornado are possible.
English

Wretched clouds of Mountain Cedar today off Ashe Junipers! This video between Medina & Vanderpool in Bandera County
Typically Cedar season tapers off through February. This season, we’re getting 2 peaks. Yay….. 🤧
🎥 Rob Walker
@natwxdesk
English

This CEDAR is absolutely awful. 😞 😭
Make it stop, @averytomascowx
English













Austin, Texas — I’m hosting a Claude Code and OpenClaw power users coworking session / meetup / demo day on Friday
It is 9-11:30A near downtown at an awesome space with breakout rooms etc
If you use Claude Code for hours every day, you should apply to come
It is free but I am limiting to power users so we have good collabs
Reply or tag your friends in Austin and I will DM with more info
English