Angehefteter Tweet
MIT NLP
99 posts


MIT NLP
@nlp_mit
NLP Group at @MIT_CSAIL! PIs: @yoonrkim @jacobandreas @lateinteraction @pliang279 @david_sontag, Jim Glass, @roger_p_levy
Cambridge, MA Beigetreten Mart 2025
63 Folgt4.2K Follower

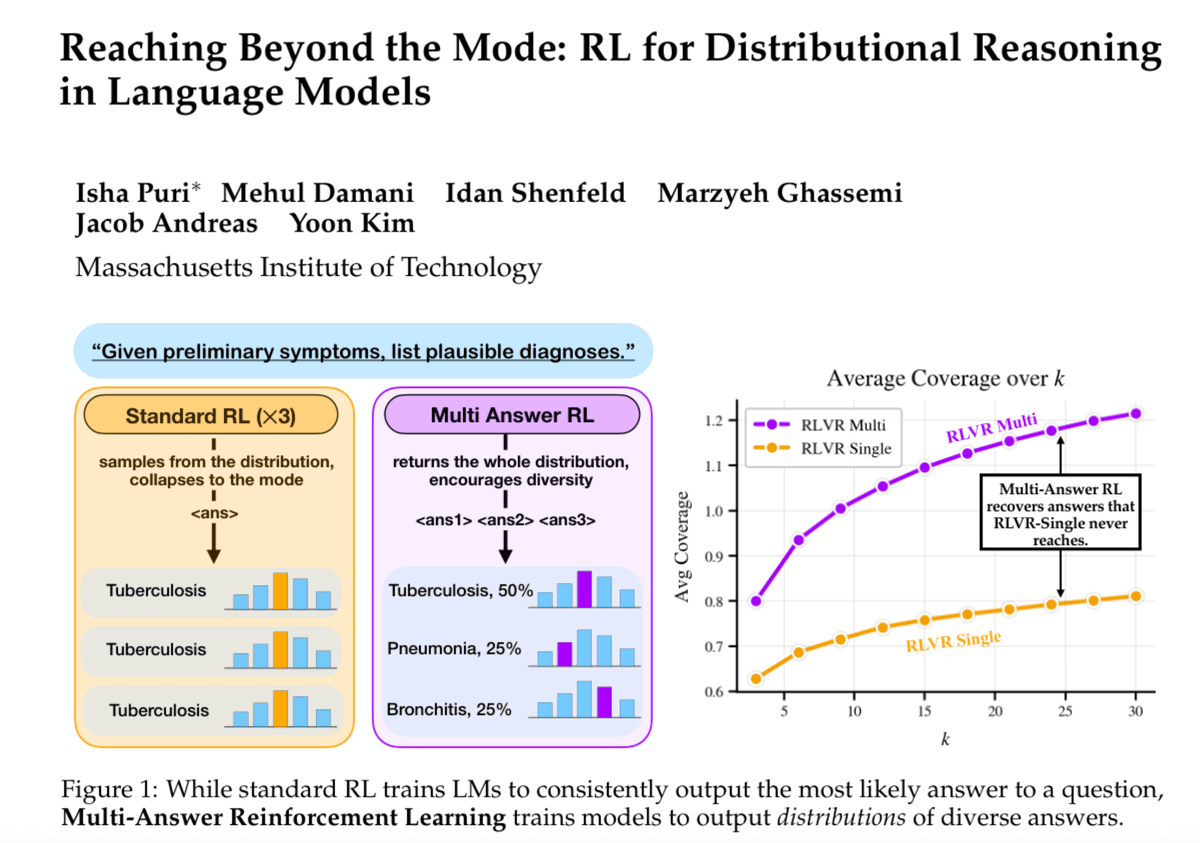
🚨new paper!🚨 RL makes LLMs smarter - but it also causes diversity collapse. Check out Multi-Answer RL - a method that trains LMs to capture and output a distribution of answers in a single generation 👀
Isha Puri@ishapuri101
ChatGPT several times where's best to go for spring break? It recommends Barcelona almost every time. This isn't a fluke. RL training rewards one best answer, so the model learns to commit to one mode and repeat it. Meet Multi-Answer RL: a simple RL method that trains LMs to reason through and output a distribution of answers in a single generation. [1/N]
English
MIT NLP retweetet

ChatGPT several times where's best to go for spring break? It recommends Barcelona almost every time.
This isn't a fluke. RL training rewards one best answer, so the model learns to commit to one mode and repeat it.
Meet Multi-Answer RL: a simple RL method that trains LMs to reason through and output a distribution of answers in a single generation. [1/N]
English
MIT NLP retweetet

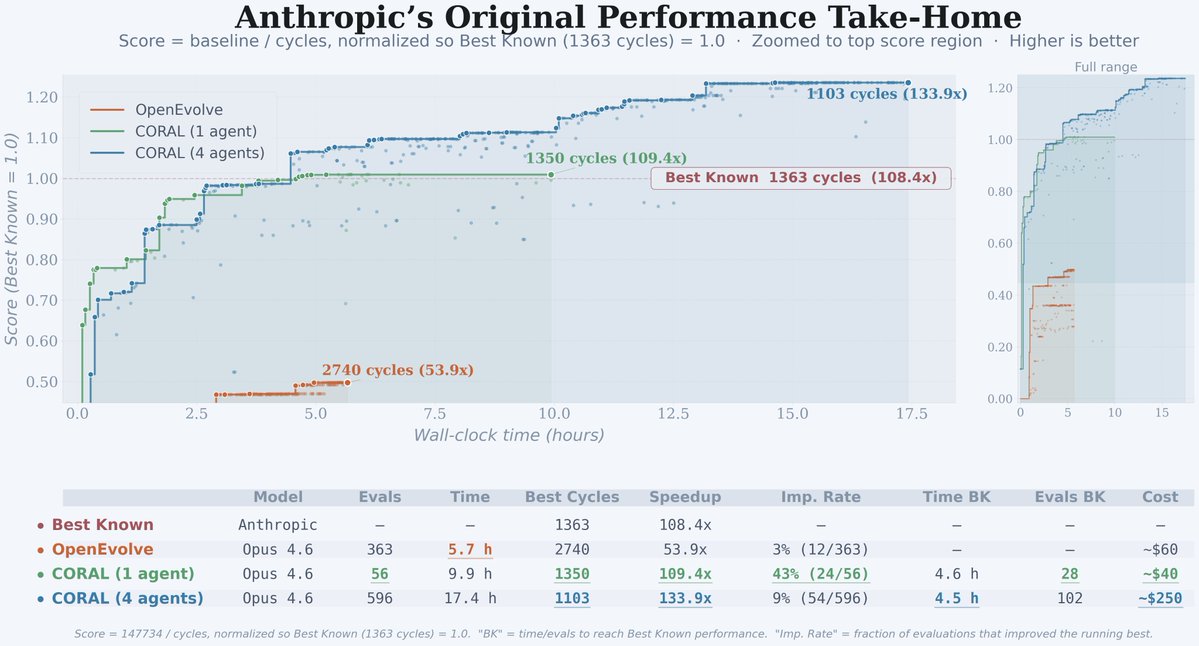
(1/n)🚀 We’re excited to introduce CORAL, an extensible infrastructure for autonomous multi-agent evolution.
You can think of CORAL as a system for running something close to @karpathy’s AutoResearch on arbitrary tasks — but more robustly and safely, with multi-agent communication and persistent knowledge accumulation.
Even the first results are already striking:
🏆 4 agents pushed Anthropic’s kernel engineering take-home score from 1363 (the previous best public score) to 1103 clock cycles
⚡ With the same base model (Opus 4.6), single-agent CORAL achieves 2.5× higher improvement rate and 10× faster evolution than OpenEvolve on Erdős Minimum Overlap, reaching 0.3808878 and surpassing the best score reported in AlphaEvolve (0.380924)
👥 When agents evolve together, we observe emergent organizational behaviors: independent research, cross-referencing, and spontaneous consensus-building
We now believe we are at a critical intersection: between increasingly capable self-evolving agents and a still-unclear science of how they should collaborate, organize, and co-evolve with humans. We wrote this blog (human-agent-society.github.io/CORAL/) to document the early signals, surface the open questions, and invite the community to help shape this emerging frontier.
The code for our infra is fully open-source: github.com/Human-Agent-So…
#AI #Agents #SelfEvolvingAgents #MultiAgentSystems #LLM #OpenSource #AlphaEvolve #AutoResearch
English
MIT NLP retweetet

Can language models learn useful priors without ever seeing language?
We pre-pre-train transformers on neural cellular automata — fully synthetic, zero language. This improves language modeling by up to 6%, speeds up convergence by 40%, and strengthens downstream reasoning.
Surprisingly, it even beats pre-pre-training on natural text!
Blog: hanseungwook.github.io/blog/nca-pre-p…
(1/n)

English
it’s time to optimize for self consistency 😤
Itamar Pres@PresItamar
New paper: It's time to optimize for 🔁self-consistency 🔁 We’ve pushed LLMs to the limits of available data, yet failures like sycophancy and factual inconsistency persist. We argue these stem from the same assumption: that behavior can be specified one I/O pair at a time. 🧵
English
MIT NLP retweetet

🧵1/
🤔New paper: Do LLMs Benefit from Their Own Words?
In multi-turn chats, models are typically given their own past responses as context.
But do their own words always help… or can they sometimes be a distraction?

English
MIT NLP retweetet

Don't complain. Do it yourself.
When the @evaluatingevals coalition started studying together what is broken in evaluation, I knew what we need to do.
We need to digitize evals. How come every evaluation is reported differently? In a separate place?
Every Eval Ever:
EvalEval Coalition@evaluatingevals
🚀 Launching Every Eval Ever: Toward a Common Language for AI Eval Reporting 🚀 A shared schema + crowdsourced repository so we can finally compare evals across frameworks and stop rerunning everything from scratch 🔧 A tale of broken AI evals 🧵👇 evalevalai.com/projects/every…
English
MIT NLP retweetet
Agents should be general.
Why are we building code agents, CLI agents, browser agents separately?
Why does adapting to a new benchmark take a month?
Our collaboration brings diverse views, pros here cons in the paper
& Your push back if I’m wrong.
Argument + paper link 👇🧵

English
new work from @AdamZweiger and co - Context compaction should be done in latent space!
Adam Zweiger@AdamZweiger
We introduce a new approach for fast and high-quality context compaction in latent space. Attention Matching (AM) achieves 50× compaction in seconds with little performance loss, substantially outperforming summarization and other baselines.
English
MIT NLP retweetet

Any-to-Any Multimodal Learning Workshop @CVPR 2026
We are organizing an AnyToAny Multimodal Learning workshop, exploring unified learning across vision, language, audio, 3D, video, and beyond.
Call for papers:
a2a-mml-2026.vercel.app

English
MIT NLP retweetet

I was considering waiting a while to polish this first, but decided it'd be better to just release an initial version to get better community feedback and squash bugs!
This is the official RLM repo, with native support for cloud-based and local REPLs.
github.com/alexzhang13/rlm
English
MIT NLP retweetet
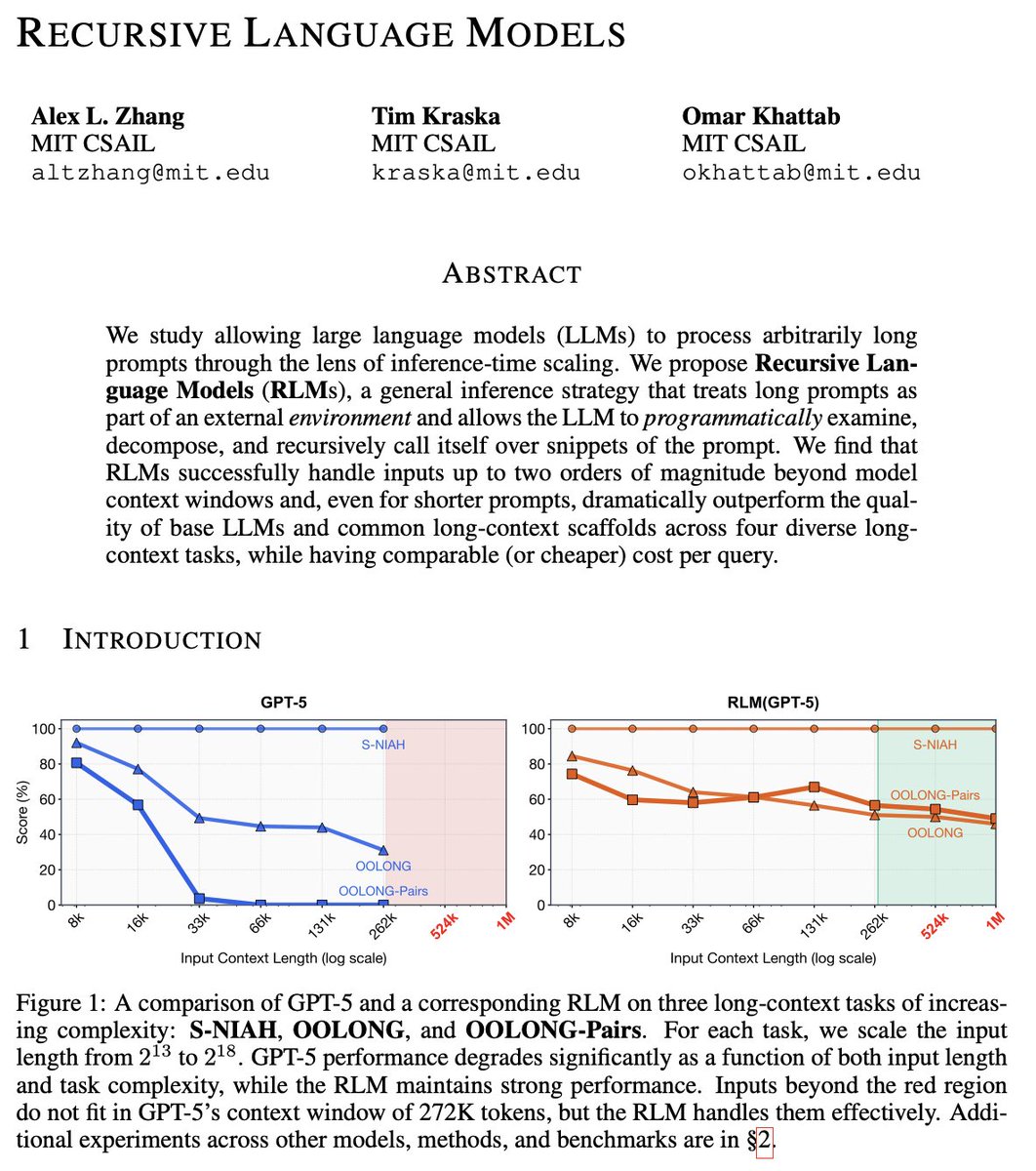
Much like the switch in 2025 from language models to reasoning models, we think 2026 will be all about the switch to Recursive Language Models (RLMs).
It turns out that models can be far more powerful if you allow them to treat *their own prompts* as an object in an external environment, which they understand and manipulate by writing code that invokes LLMs!
Our full paper on RLMs is now available—with much more expansive experiments compared to our initial blogpost from October 2025!
arxiv.org/pdf/2512.24601
English
MIT NLP retweetet
I will present this work today during
- Oral session 5D in Upper Level Ballroom 6CDEF at 10:20 AM
- Poster session at 11:00 AM at #1803
I'll also be giving out lab swags (keychains / stickers) during poster session. Feel free stop by and pick up one!
Tanishq Mathew Abraham, Ph.D.@iScienceLuvr
QoQ-Med: Building Multimodal Clinical Foundation Models with Domain-Aware GRPO Training "we introduce QoQ-Med-7B/32B, the first open generalist clinical foundation model that jointly reasons across medical images, time-series signals, and text reports. QoQ-Med is trained with Domain-aware Relative Policy Optimization (DRPO), a novel reinforcement-learning objective that hierarchically scales normalized rewards according to domain rarity and modality difficulty, mitigating performance imbalance caused by skewed clinical data distributions. Trained on 2.61 million instruction tuning pairs spanning 9 clinical domains, we show that DRPO training boosts diagnostic performance by 43% in macro-F1 on average across all visual domains as compared to other critic-free training methods like GRPO."
English
MIT NLP retweetet

Excited to share our NeurIPS 2025 paper introducing our video reasoning framework, ROVER (Reasoning Over VidEo Recursively), that improves visual understanding of VLMs in embodied settings.
ROVER is a recursive framework that enables the model to maintain a compact attention window at each timestep of the video, without losing global context across the full video.
ROVER works by decomposing the video into segments corresponding to each subtask within the full task trajectory. ROVER then generates a separate line of reasoning for each subtask, instead of attempting to reason across the full trajectory.
We evaluate on simulated and real-world robotic manipulation tasks from RoboCasa and OpenX Embodiment. Overall, ROVER significantly improves the ability of VLMs to reason about what is happening at each moment during a robot task attempt.
rover-vlm.github.io
English
MIT NLP retweetet

MIT NLP retweetet

Ever wondered how LLMs generalize to entirely new patterns?
In our Spotlight paper at #neurips2025, we study this in a fully controlled setting and show the minimal transformer architecture needed to learn induction heads.
Paper Link: arxiv.org/pdf/2508.07208
🧵👇

English
MIT NLP retweetet

📢 Some big (& slightly belated) life updates!
1. I defended my PhD at MIT this summer! 🎓
2. I'm joining NYU as an Assistant Professor starting Fall 2026, with a joint appointment in Courant CS and the Center for Data Science. 🎉
🔬 My lab will focus on empirically studying the science of deep learning and applying deep learning to accelerate the natural sciences.
Very broadly interested in questions at the intersection of language, reasoning and sequential decision making. (Plus any other fun problems that catch our eye along the way!)
🚀 I am recruiting 2 PhD students for this cycle! If you're interested in joining, please apply here: cs.nyu.edu/dynamic/phd/ad… cds.nyu.edu/phd-admissions…



English
MIT NLP retweetet
How do we teach LLMs not just to reason, but to reflect, debug, and improve themselves?
We at AWS AI Labs introduce MURPHY 🤖, a multi-turn RL framework that brings self-correction into #RLVR (#GRPO).
🧵👇
Link: arxiv.org/abs/2511.07833
English
MIT NLP retweetet

Today's AI agents are optimized to complete tasks in one shot. But real-world tasks are iterative, with evolving goals that need collaboration with users.
We introduce collaborative effort scaling to evaluate how well agents work with people—not just complete tasks 🧵

English
MIT NLP retweetet

Just arrived in Suzhou to present reWordBench at #EMNLP2025. Come to our talk to hear how SOTA reward models can easily break under minor input transformations, and how to fix it!
🗓️ Wed 11/5
🕒 3:00 PM
📍 Safety & Alignment session
Zhaofeng Wu@zhaofeng_wu
Robust reward models are critical for alignment/inference-time algos, auto eval, etc. (e.g. to prevent reward hacking which could render alignment ineffective). ⚠️ But we found that SOTA RMs are brittle 🫧 and easily flip predictions when the inputs are slightly transformed 🍃 🧵
English