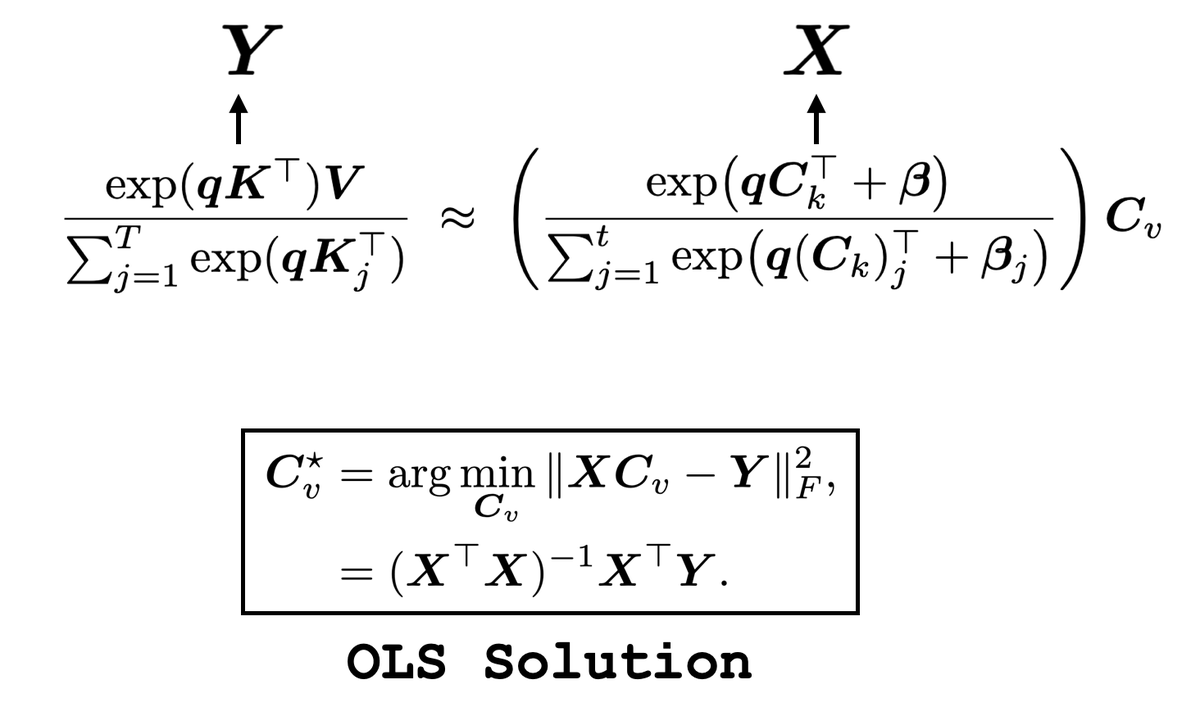Sabitlenmiş Tweet

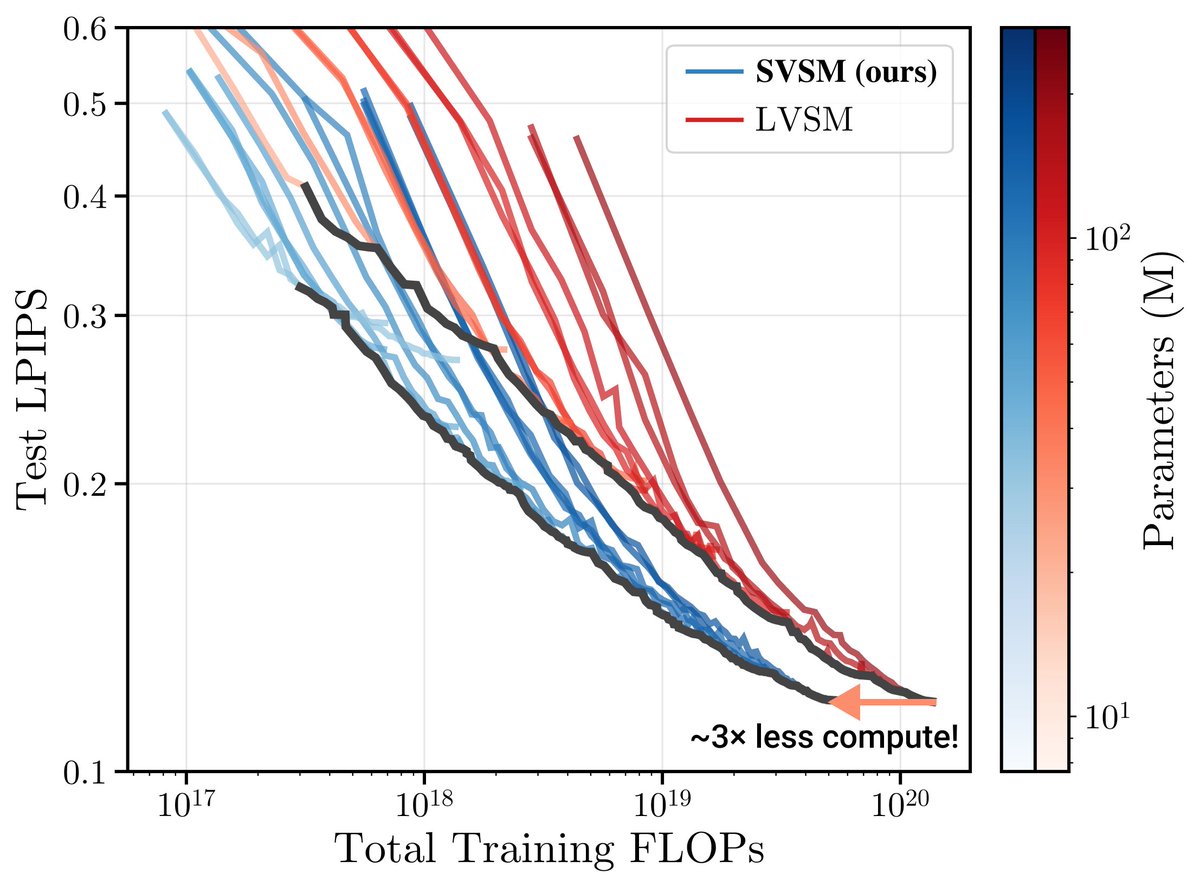
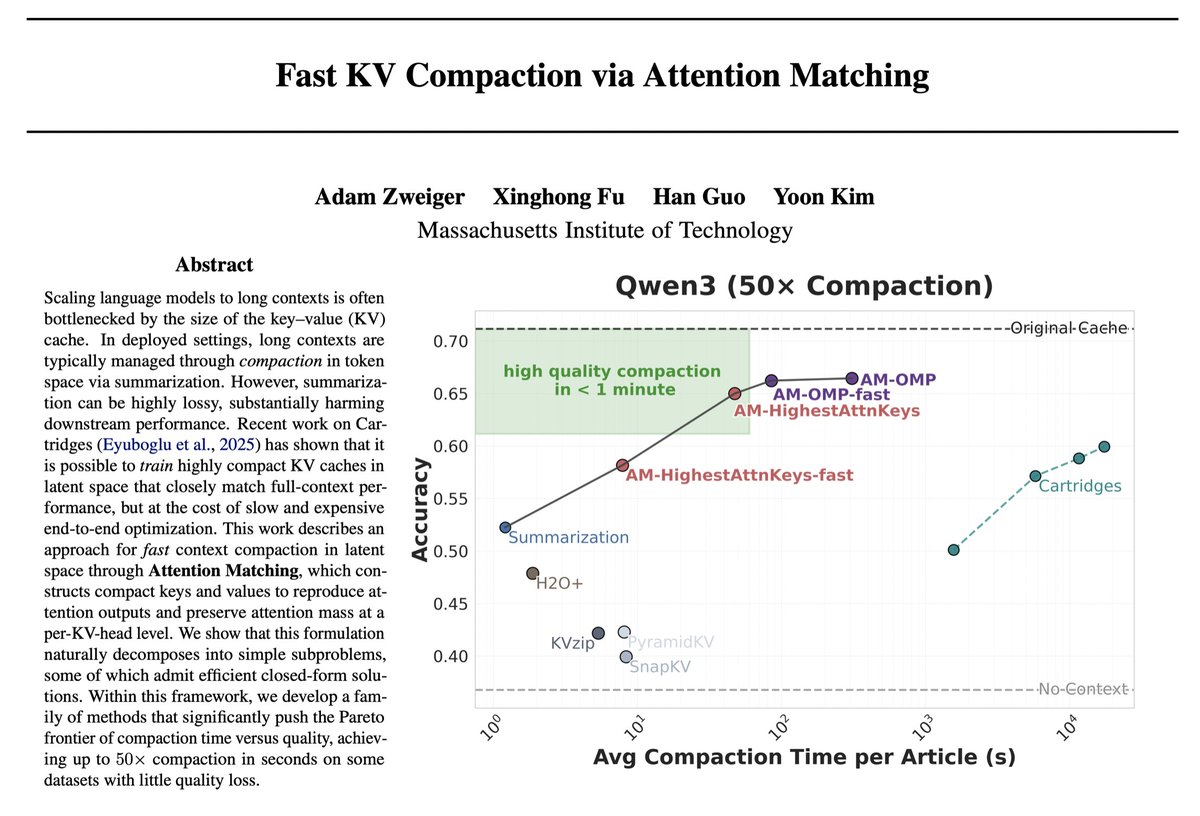
We introduce a new approach for fast and high-quality context compaction in latent space.
Attention Matching (AM) achieves 50× compaction in seconds with little performance loss, substantially outperforming summarization and other baselines.
English