Angehefteter Tweet

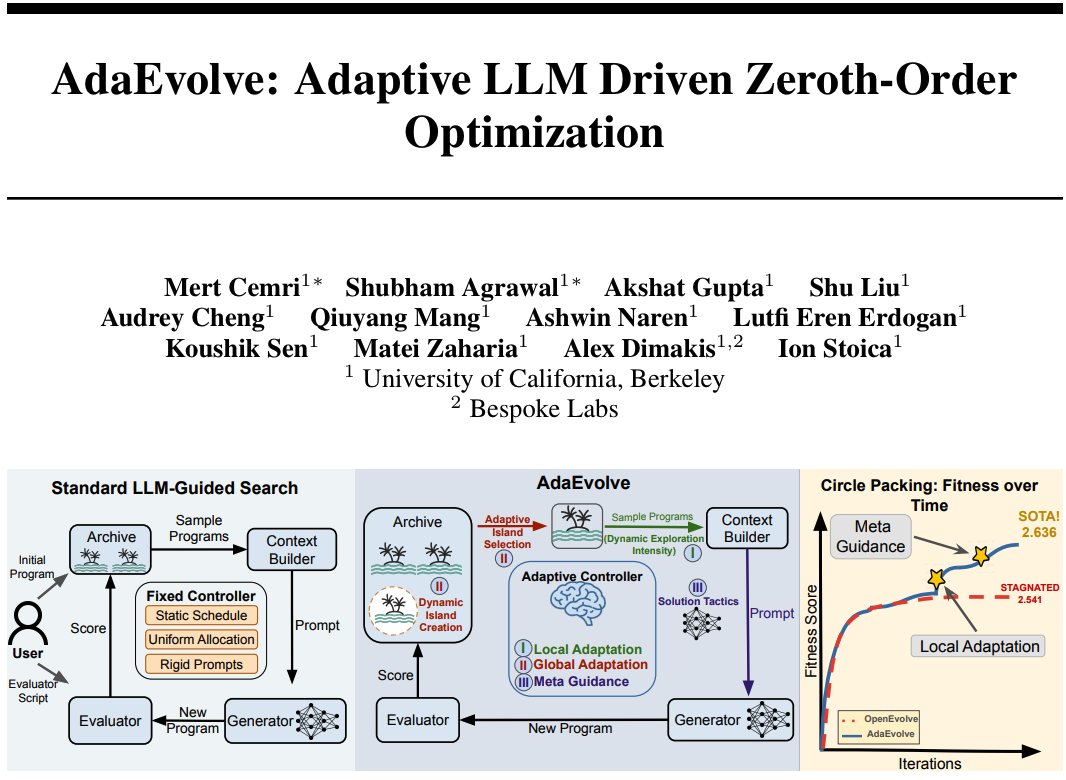
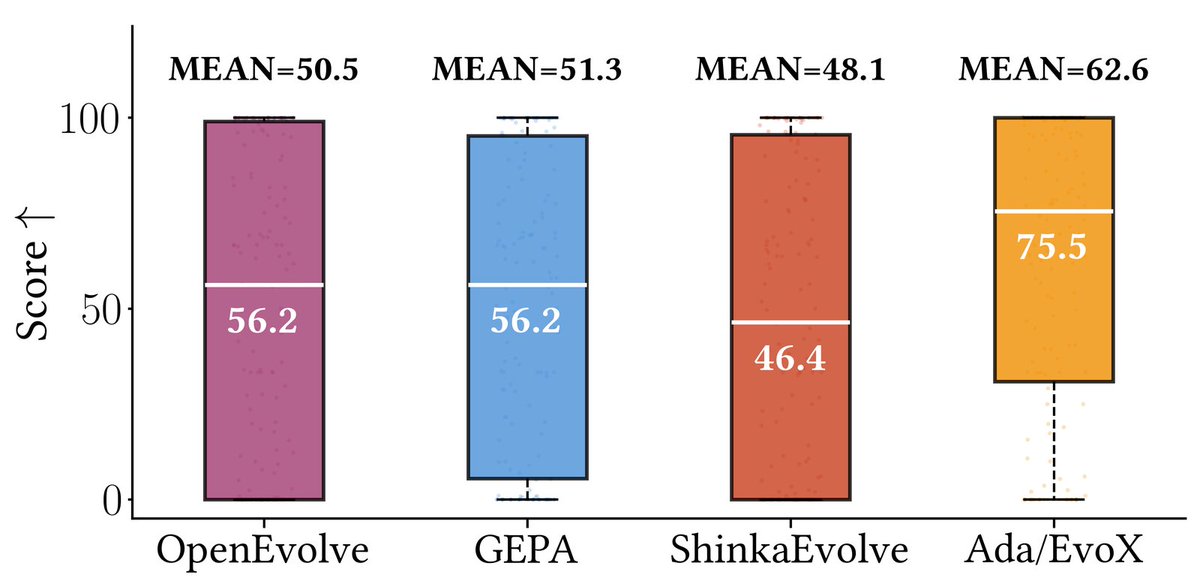
Post-training is no longer a final polishing step, it has become a central scaling dimension for modern LLMs. Understanding its science is essential to unlocking the full potential of foundation models.
We’re excited to be organizing SPOT Workshop at @iclr_conf , with an outstanding lineup of speakers spanning academia and industry.
📢 Call for papers is open — deadline Feb 5, 2026 (AoE).
Please follow workshop X page (@spoticlr) for more updates.
SPOT Workshop at ICLR 2026 🇧🇷@spoticlr
📢 Announcing 𝗦𝗣𝗢𝗧: 𝗦𝗰𝗮𝗹𝗶𝗻𝗴 𝗣𝗼𝘀𝘁-𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝗳𝗼𝗿 𝗟𝗟𝗠𝘀 Workshop at #ICLR2026 (@iclr_conf )🚀 🚨 We invite work on the principles of post-training scaling, bridging algorithms, data & systems 📅 Feb 5, 2026 for papers 🌐 spoticlr.github.io 🧵(1/5)
English