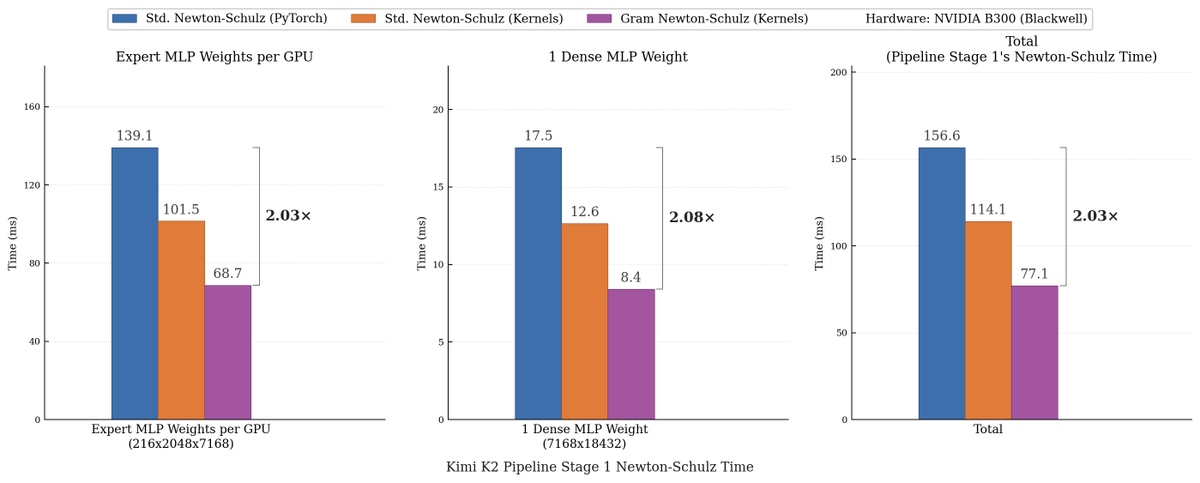
Sabitlenmiş Tweet

🚀SonicMoE🚀now runs at peak throughput on NVIDIA Blackwell GPUs 😃
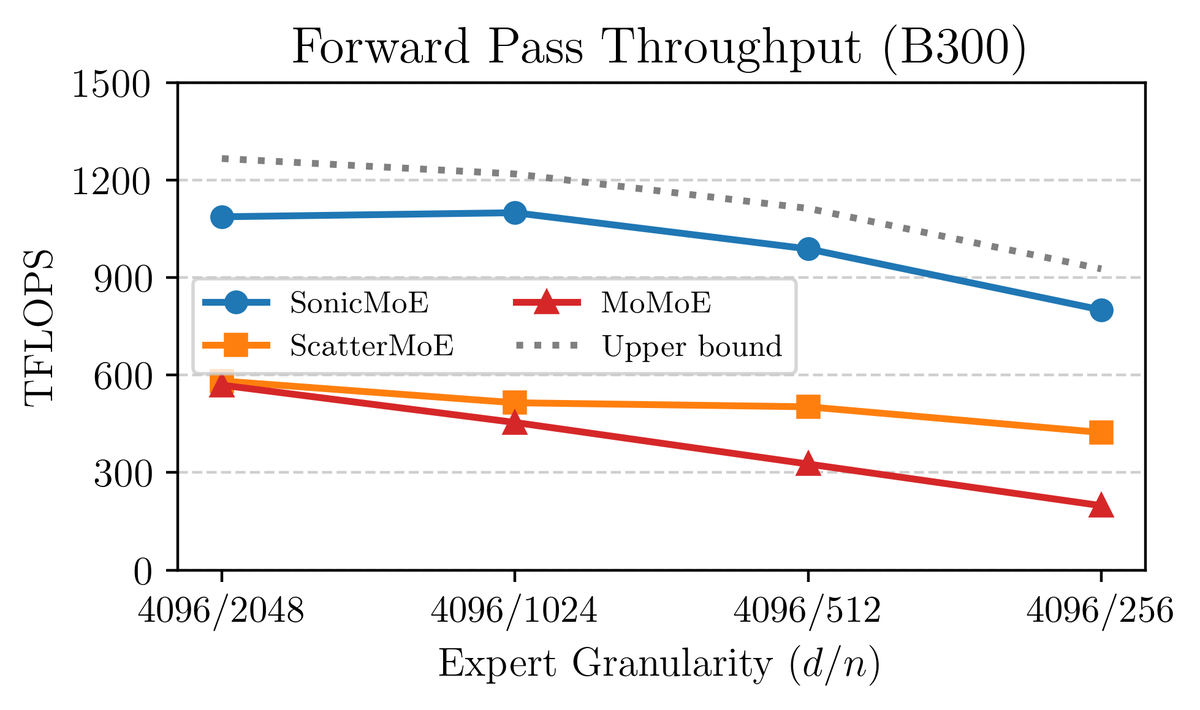
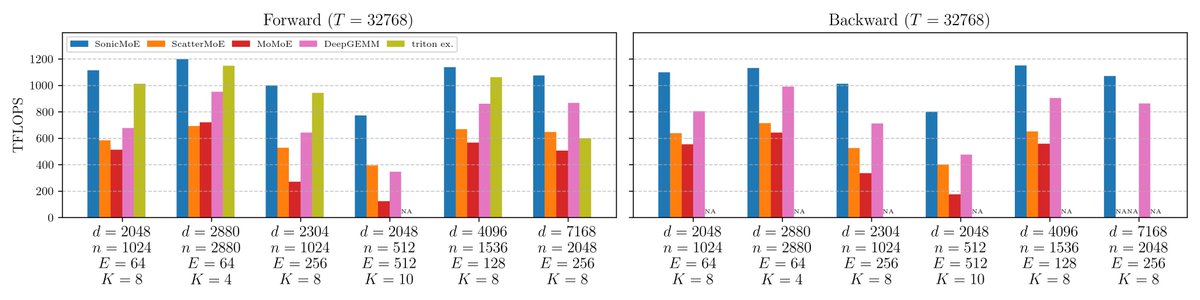
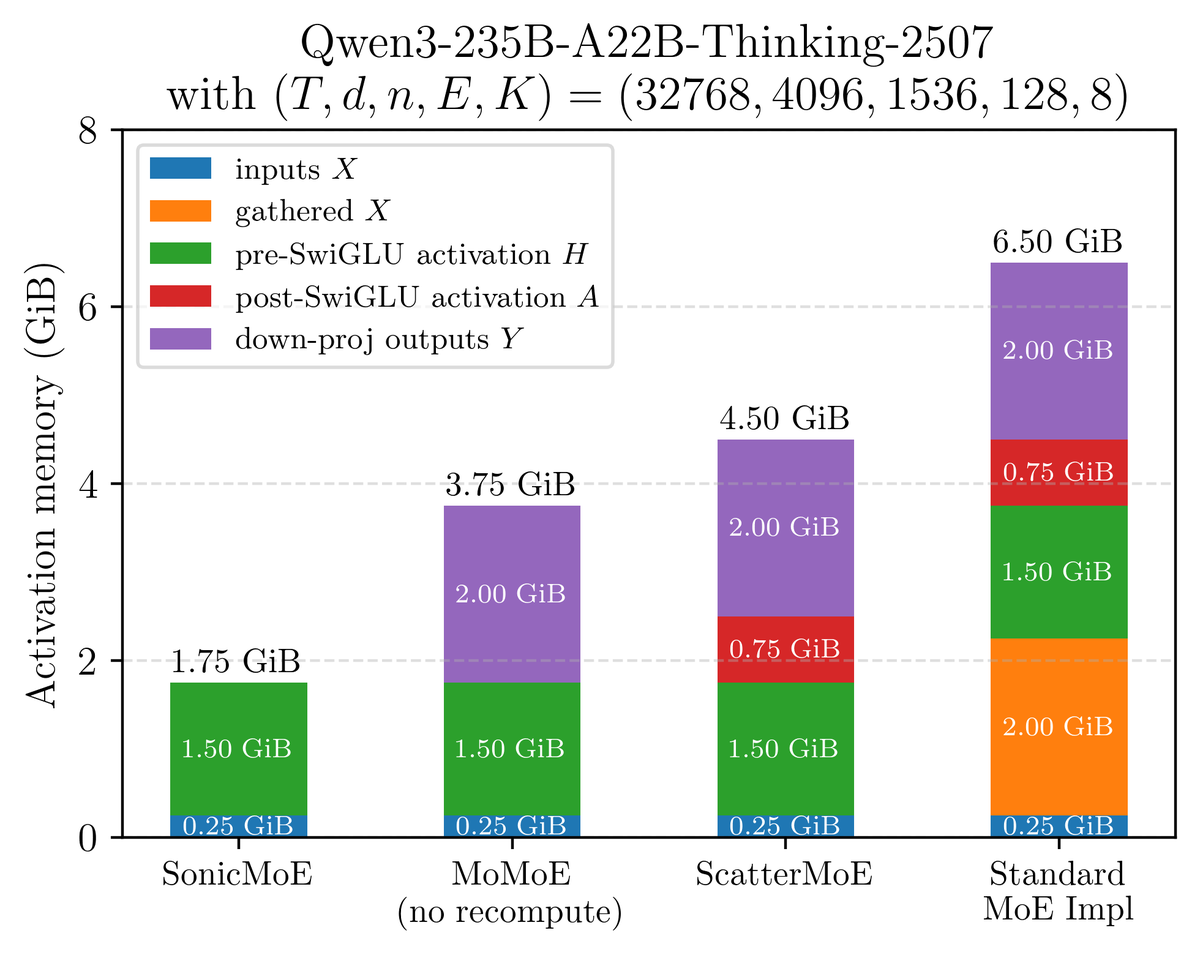
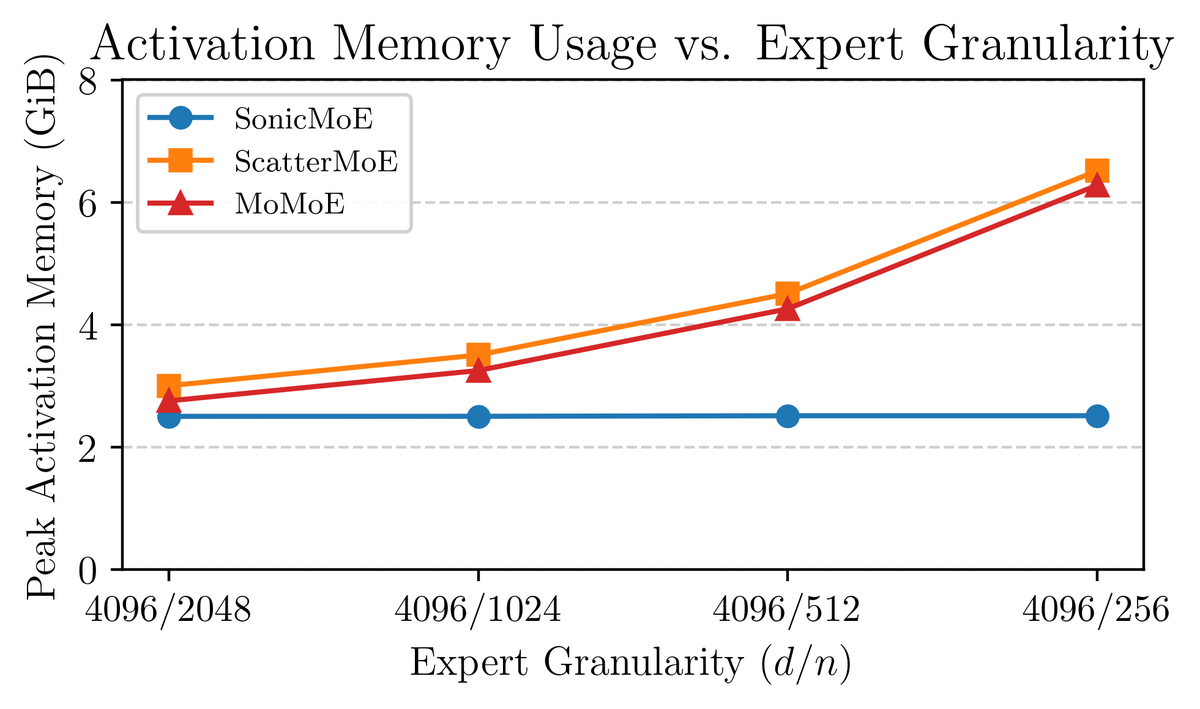
54% & 35% higher fwd/bwd TFLOPS than the DeepGEMM baseline and 21% higher fwd TFLOPS than the triton official example. SonicMoE still maintains its minimum activation memory footprint: the same as a dense model with equal activated parameters and independent of expert granularity. We wrote a blogpost on how we leveraged Blackwell features and the software abstraction on QuACK:
Work with @MayankMish98, @XinleC295, @istoica05, @tri_dao

English