Sabitlenmiş Tweet

Very excited about this line of research of fast-slow learning,
1) potential to solve a lot of issues with current RL (eg. entropy collapse, sparse rewards)
2) an intuitive way of incorporating rich feedback with RL
3) provides a way to transfer knowledge of text-only based learning into the model
4) a great candidate for model-harness co-evolution, seeing a lot discussion on X lately about future models developing their own harness.
5) most importantly, can imagine these kinds of algorithms to be more suitable candidates for discovery that requires both extreme exploration but at the same time improving the underlying model capabilities.
and much more ...
Kusha Sareen@KushaSareen
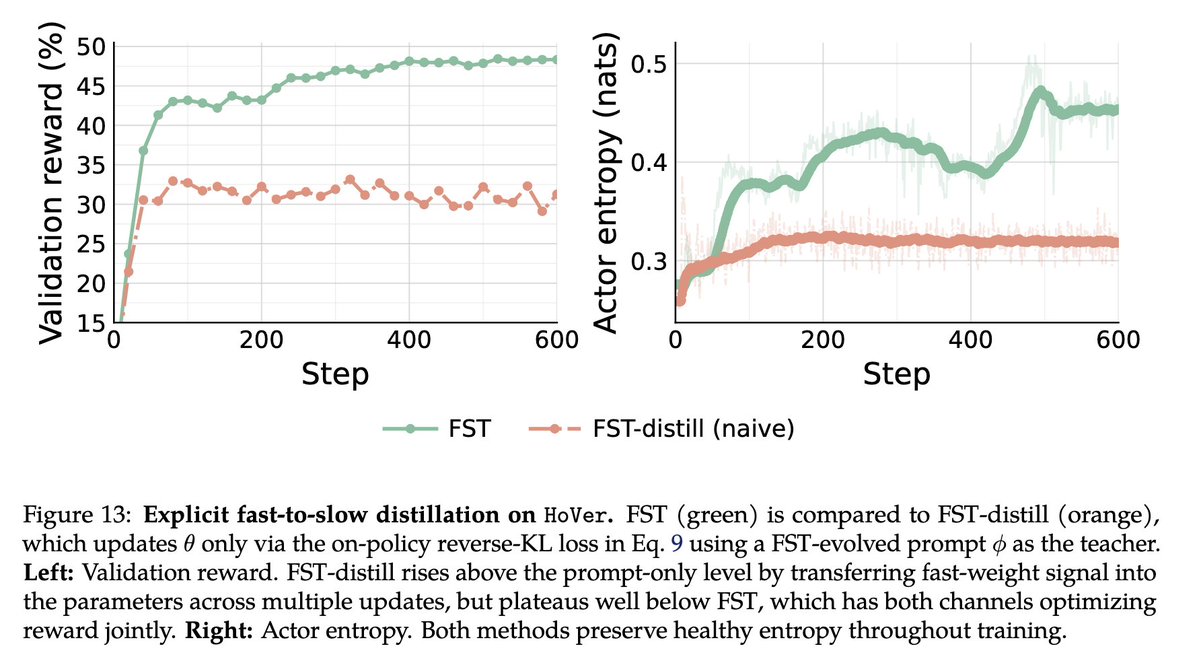
Can LLMs adapt continually without losing base skills? Fast-Slow Training (FST) pairs "slow" weights with "fast" context. FST vs. RL: • 3x more sample-efficient • Higher performance ceiling • Less KL drift (better plasticity) • Continual learning: succeeds where RL stalls
English