Angehefteter Tweet

Yesterday I demo-ed Secureflow at @TheBarnWaterloo . To my surprise, it was well received and I received a lot of positive feedback!
Check out Secureflow 👇
codepathfinder.dev/blog/introduci…

Waterloo, Ontario 🇨🇦 English
Shivasurya
4.2K posts

@sshivasurya
senior software engineer | security + AI | @UWaterloo @Dropbox @Zoho alum | building https://t.co/bMnGeuZ1tX | 🍁 🇨🇦
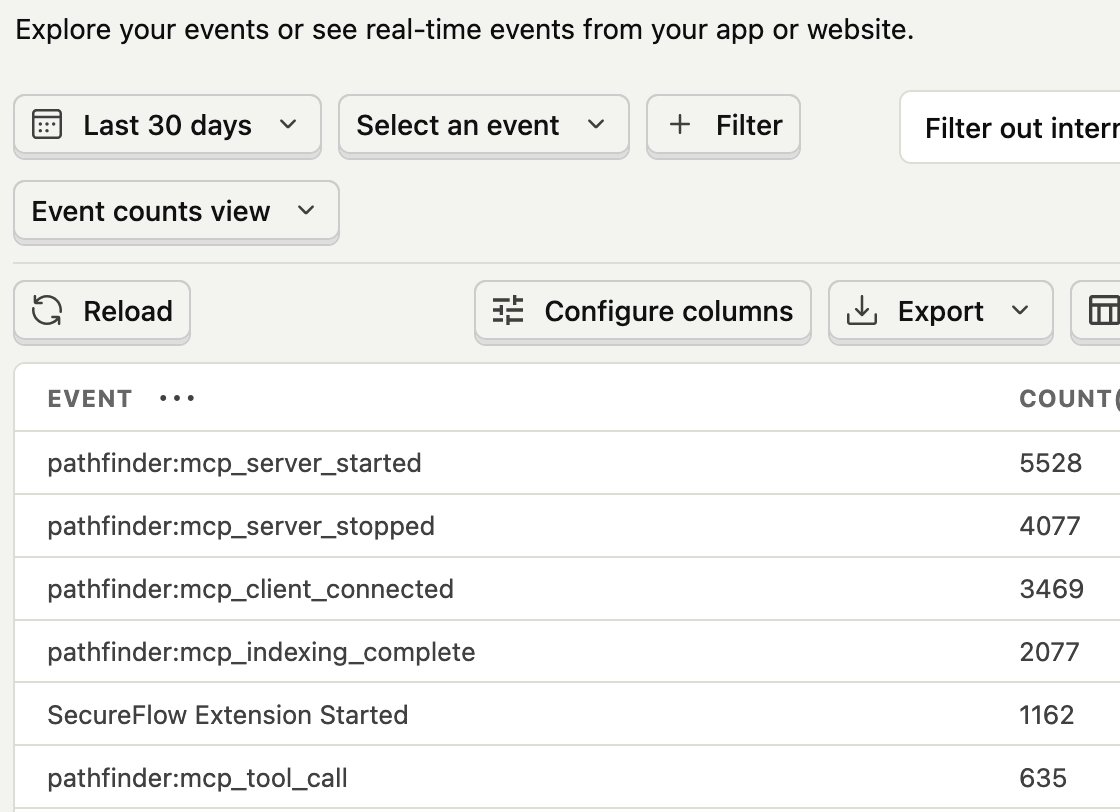
LSPs are built for humans typing in IDEs. Pathfinder MCP is built for agents querying codebases. Demoed it tonight at @TheBarnWaterloo despite the storm. Check it out here: codepathfinder.dev/mcp Thanks @shriji for the pic 📸


What's your AI adoption level? (according to Steve Yegge)

A small thank you to everyone using Claude: We’re doubling usage outside our peak hours for the next two weeks.












claude code has a hidden setting that makes it 600x faster and almost nobody knows about it by default it uses text grep to find functions. it doesn't understand your code at all. that's why it takes 30-60 seconds and sometimes returns the wrong file there's a flag called ENABLE_LSP_TOOL that connects it to language servers. same tech that powers vscode's ctrl+click to jump straight to the definition after enabling it: > "add a stripe webhook to my payments page" - claude finds your existing payment logic in 50ms instead of grepping through hundreds of files > "fix the auth bug on my dashboard" - traces the actual call hierarchy instead of guessing which file handles auth > after every edit it auto-catches type errors immediately instead of you finding them 10 prompts later also saves tokens because claude stops wasting context searching for the wrong files 2 minute setup and it works for 11 languages





