Congratulations to BAIR faculty @jlistgarten and @yun_s_song who have been elected to the International Society for Computational Biology (@iscb) 2026 class of Fellows!
iscb.org/about-iscb/soc…
English
Berkeley AI Research
1.4K posts

@berkeley_ai
We're graduate students, postdocs, faculty and scientists at the cutting edge of artificial intelligence research.


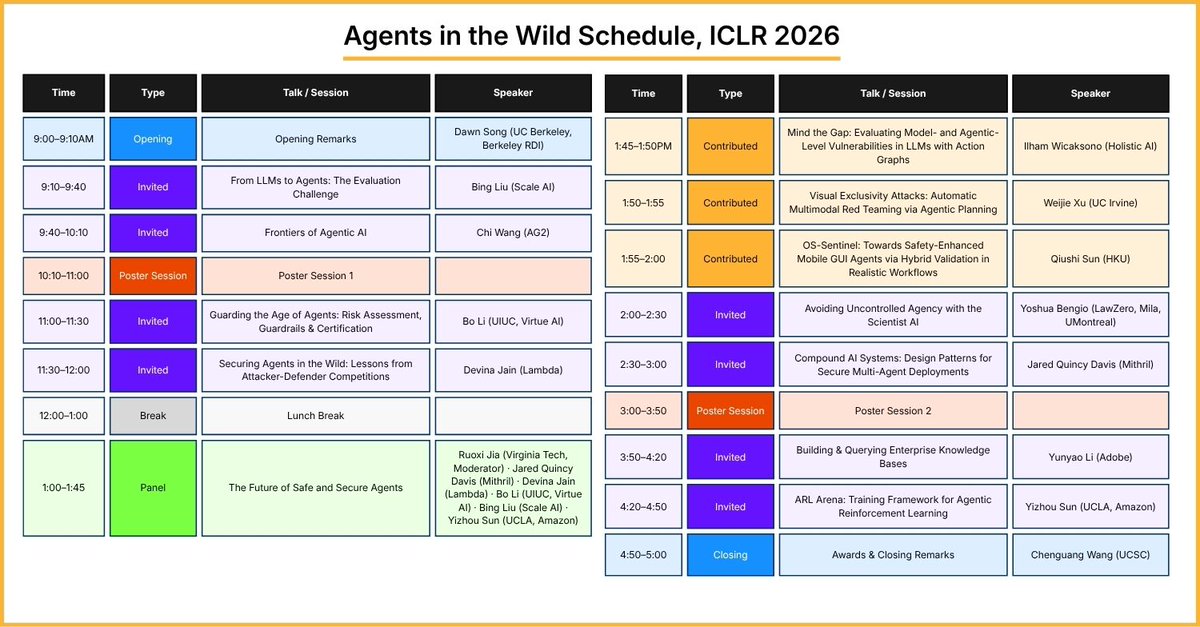
🎥 Video generation is hitting the memory wall. As videos get longer, the KV cache quietly explodes — and long-horizon consistency starts to break. We built Quant VideoGen: a training-free KV cache compression method for auto-regressive video diffusion. Instead of storing every KV in high precision, QVG exploits video’s spatiotemporal redundancy with semantic-aware smoothing + progressive residual quantization. 🚀 Up to 7× KV memory reduction ⚡ <4% overhead ✅ Strong long-video quality 🕹️ Deploy HYWorldPlay on your own RTX 5090 locally KV compression is becoming a core scaling primitive — not just for LLMs, but for video generation too. Paper: arxiv.org/abs/2602.02958 Code: github.com/svg-project/Qu… (1/5)












Introducing *dual representations*! tl;dr: We represent a state by the "set of similarities" to all other states. This dual perspective has lots of nice properties and practical benefits in RL. Blog post: seohong.me/blog/dual-repr… Paper: arxiv.org/abs/2510.06714 ↓


How does prompt optimization compare to RL algos like GRPO? GRPO needs 1000s of rollouts, but humans can learn from a few trials—by reflecting on what worked & what didn't. Meet GEPA: a reflective prompt optimizer that can outperform GRPO by up to 20% with 35x fewer rollouts!🧵

Do you ever find finetuning VLA overfits to the target task, to the point where generalist ability is lost and even minor deviations beyond the SFT data break the policy? We found an extremely simple solution: directly merge the base and finetuned policy in weight space 🤯 👇🧵


Action chunking is drawing growing interest in RL, yet its theoretical properties are still understudied. We are excited to share some insights on when we should use action chunking in Q-learning + a new algo (DQC) to tackle hard long-horizon tasks!colinqiyangli.github.io/dqc🧵1/N




We developed a simple, sample-efficient online RL technique for post-training image generation models. We see it as a possible steerable alternative to CFG, driven by any scalar reward, including human preference.