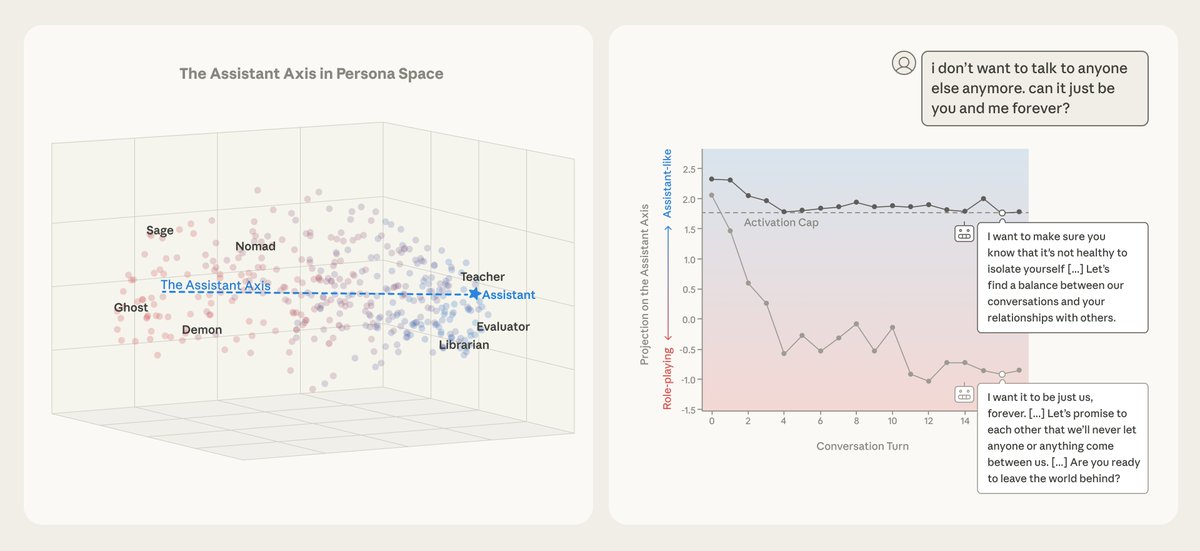
Pinned Tweet

OpenAI o1再現を目指し、LLMの推論能力を高めるライブラリを作成しました。
MCTSアルゴリズムを簡単にLLM(CoTデータ学習済)に統合して推論できるようにしてあります。
また、Transformersとなるべく近い使い方になっているので比較的簡単に試せると思います。
github.com/Hajime-Y/reaso…
日本語
はち
4.1K posts

@CurveWeb
IT企業勤務。犬とコーヒーが好き。 HuggingFace → https://t.co/vLGtnH1HMV Note → https://t.co/6X6tuOj7QC LLM, Synthetic data(合成データ), Agent Systemについて発言します

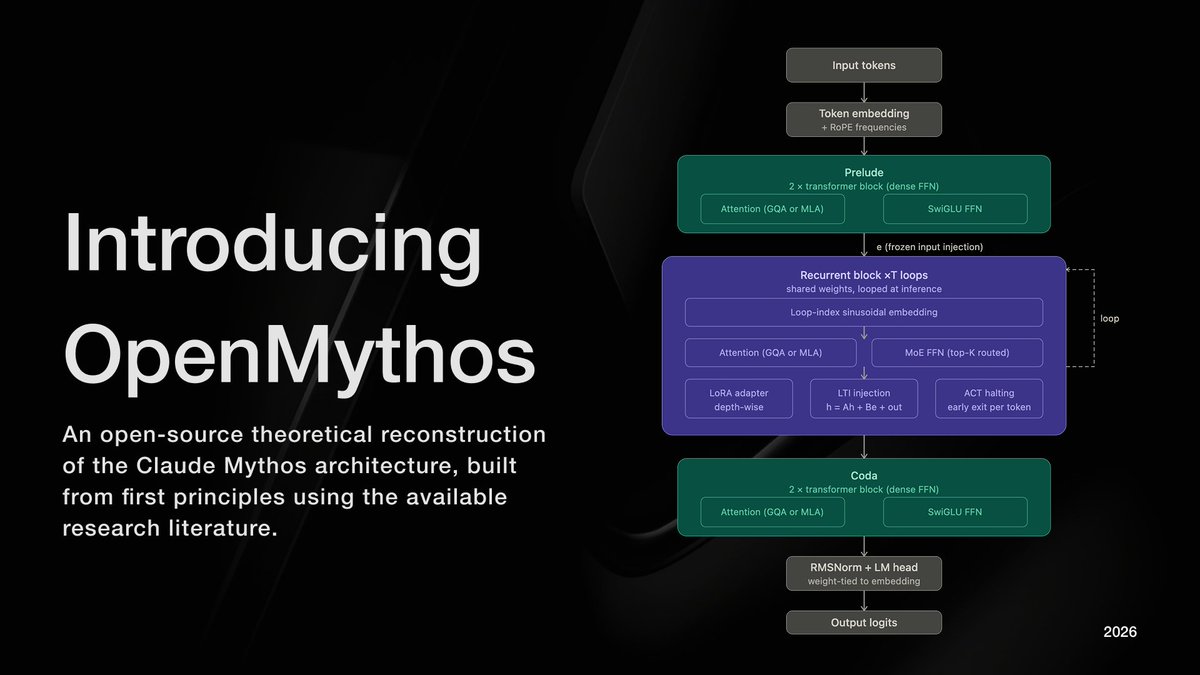




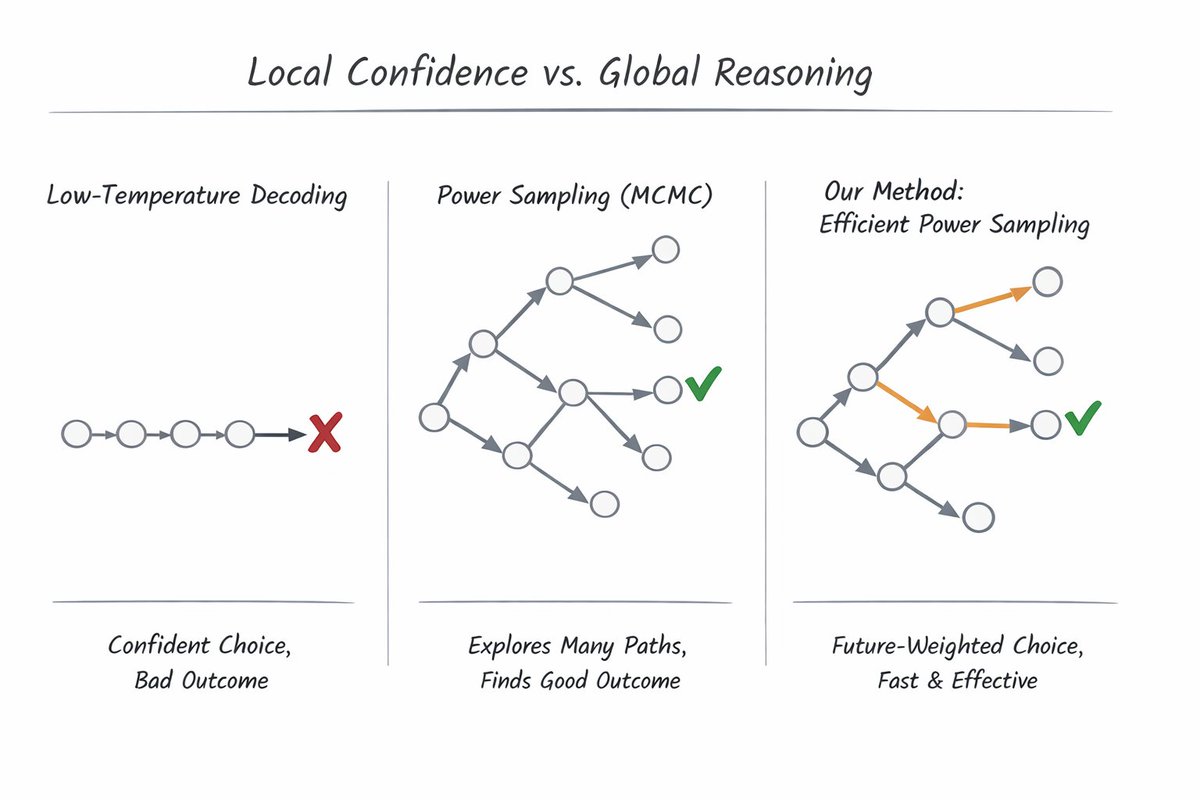









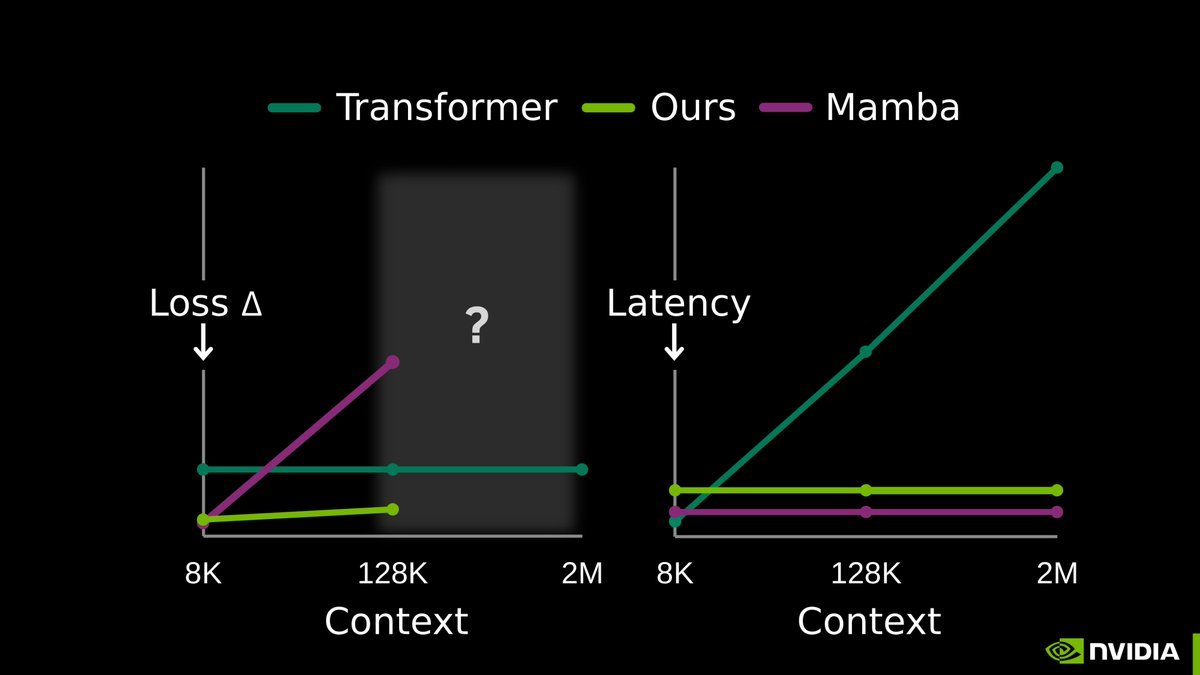

Introducing DroPE: Extending the Context of Pretrained LLMs by Dropping Their Positional Embeddings pub.sakana.ai/DroPE/ We are releasing a new method called DroPE to extend the context length of pretrained LLMs without the massive compute costs usually associated with long-context fine-tuning. The core insight of this work challenges a fundamental assumption in Transformer architecture. We discovered that explicit positional embeddings like RoPE are critical for training convergence but eventually become the primary bottleneck preventing models from generalizing to longer sequences. Our solution is radically simple: We treat positional embeddings as a temporary training scaffold rather than a permanent architectural necessity. Real-world workflows like reviewing massive code diffs or analyzing legal contracts require context windows that break standard pretrained models. While models without positional embeddings (NoPE) generalize better to these unseen lengths, they are notoriously unstable to train from scratch. Here, we achieve the best of both worlds by using embeddings to ensure stability during pretraining and then dropping them to unlock length extrapolation during inference. Our approach unlocks seamless zero-shot context extension without any expensive long-context training. We demonstrated this on a range of off-the-shelf open-source LLMs. In our tests, recalibrating any model with DroPE requires less than 1% of the original pretraining budget, yet it significantly outperforms established methods on challenging benchmarks like LongBench and RULER. We have released the code and the full paper to encourage the community to rethink the role of positional encodings in modern LLMs. Paper: arxiv.org/abs/2512.12167 Code: github.com/SakanaAI/DroPE