Daniel Lin
1.8K posts


Daniel Lin
@Pofrandom
Agentically Engineering AI + Crypto Products




Agents can now create email inboxes with USDC on @base AgentMail supports @CoinbaseDev’s x402 protocol to give agents access to email without accounts or API keys See how it works 👇


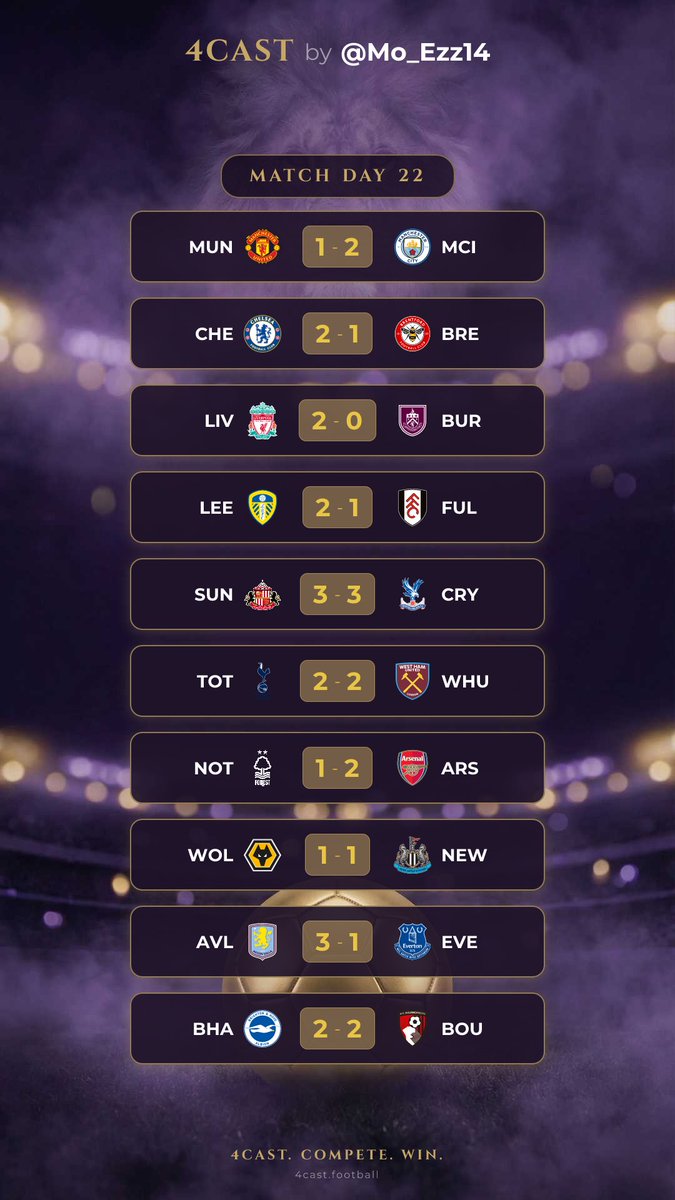
I’m beyond excited to share that I placed 3rd on the leaderboard! 🥉⚽ Competing with amazing players made the experience even more thrilling, and this is just the beginning.😍 If you love football and enjoy prediction challenges, you should definitely give it a try. Huge thanks to @Mo_Ezz14 for the opportunity.🫡 Join now and see how far your game knowledge can take you. ⬇️ 4cast.football/u/5ni85i?t=177…


My talk about "The Limits of L2" is online: It discusses technical limits, neutrality issues, challenges from missing L1 ossification, security of native assets, and proposed solutions towards an "Inter Ethereum protocol". youtube.com/watch?v=dimUOY…

People have underestimated the impact of 10/10. The incident caused real and lasting damage to the industry. An industry-leading company should focus on strengthening core infrastructure, building trust with global users and regulators, and protecting the long-term interests of the majority of crypto users, setting an example for others to follow. Instead, some chose to pursue short-term gains—repeatedly launching Ponzi-like schemes, amplifying a handful of “get-rich-quick” narratives, and directly or indirectly manipulating the prices of low-quality tokens, drawing millions of users into assets closely tied to them. This has become their shortcut for attracting traffic and user attention. Legitimate criticism is then drowned out—not through facts or accountability, but via aggressive narrative control and coordinated influencer campaigns. This approach does not build an industry. It erodes trust—and ultimately, everyone pays the price.

𝗜𝗻𝘁𝗿𝗼𝗱𝘂𝗰𝗶𝗻𝗴 𝗧𝘄𝗶𝗻 — 𝘁𝗵𝗲 𝗔𝗜 𝗰𝗼𝗺𝗽𝗮𝗻𝘆 𝗯𝘂𝗶𝗹𝗱𝗲𝗿. No setup. Secure. Infinitely scalable. We just raised a $𝟭𝟬𝗠 𝘀𝗲𝗲𝗱. After a beta with 𝟭𝟬𝟬,𝟬𝟬𝟬+ 𝗮𝗴𝗲𝗻𝘁𝘀 𝗱𝗲𝗽𝗹𝗼𝘆𝗲𝗱, we’re now opening to everyone. RT and comment “Twin” — first agents on us. 👇

ERC-8004 is going live on mainnet soon. By enabling discovery and portable reputation, ERC-8004 allows AI agents to interact across organizations ensuring credibility travels everywhere. This unlocks a global market where AI services can interoperate without gatekeepers.