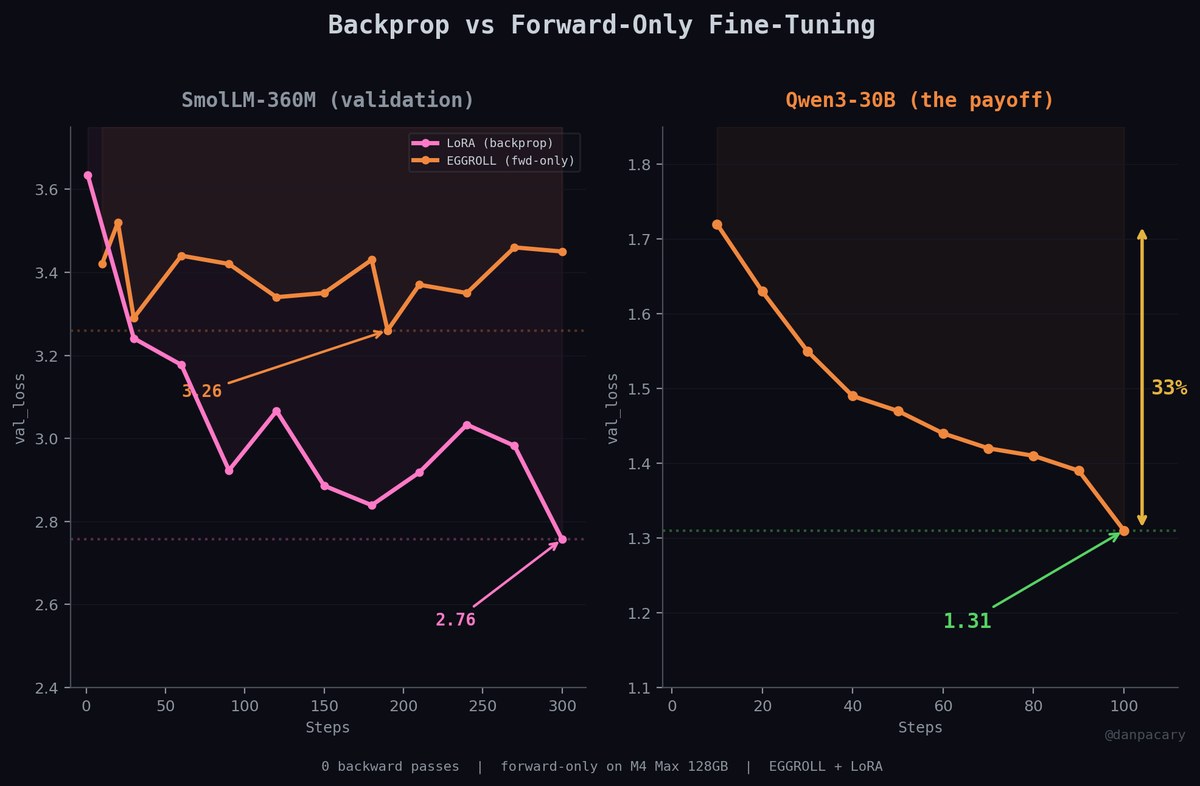
@yule_gan Perhaps it’s because pretraining creates a set of experts sufficiently close to the model in weight space such that a random perturbation can move the model onto the an expert? This paper has more details: arxiv.org/html/2603.1222…
English