Suresh
6K posts


Suresh
@_Suresh2
MSc Software Engineering @ Chongqing University ’26 | Researching AI x Software Engineering (AI for SE & SE for AI) | 🇵🇰➡️🇨🇳







GLM-5.1 is now on BytePlus ModelArk Coding Plan. Starting at just $10/month, ModelArk Coding Plan offers a highly cost-efficient way to access GLM-5.1 alongside other advanced coding models. GLM-5.1 is Z.AI's latest flagship model, MIT-licensed, open-weight, and built for long-horizon agentic coding. GLM-5.1 ranks among the world's top-tier models across leading coding benchmarks, including SWE-Bench Pro. What you get with ModelArk Coding Plan: → Multiple advanced coding models in one subscription: GLM-5.1, Kimi-K2.5, Dola-Seed-2.0-pro, DeepSeek-V3.2, and more. Switch freely or let Auto mode match the best model to the task. → Works with the tools you already use: Claude Code, Cursor, Cline, Codex CLI, Kilo Code, Roo Code, OpenCode, and OpenClaw → No throttling. Backed by ByteDance's infrastructure. → Activated on purchase. Ready to use immediately. Also new this month: Dreamina Seedance 2.0 is now available on BytePlus, the official API platform for Seedance models. Learn more: byteplus.com/en/product/see… Refer friends and earn 10% vouchers on every order with no cap. Your friends get 10% off their first subscription too. Get started for $10/month → tinyurl.com/4zvkf9kc #BytePlus #ModelArk #GLM #AIEngineering #DevTools #AIAgent


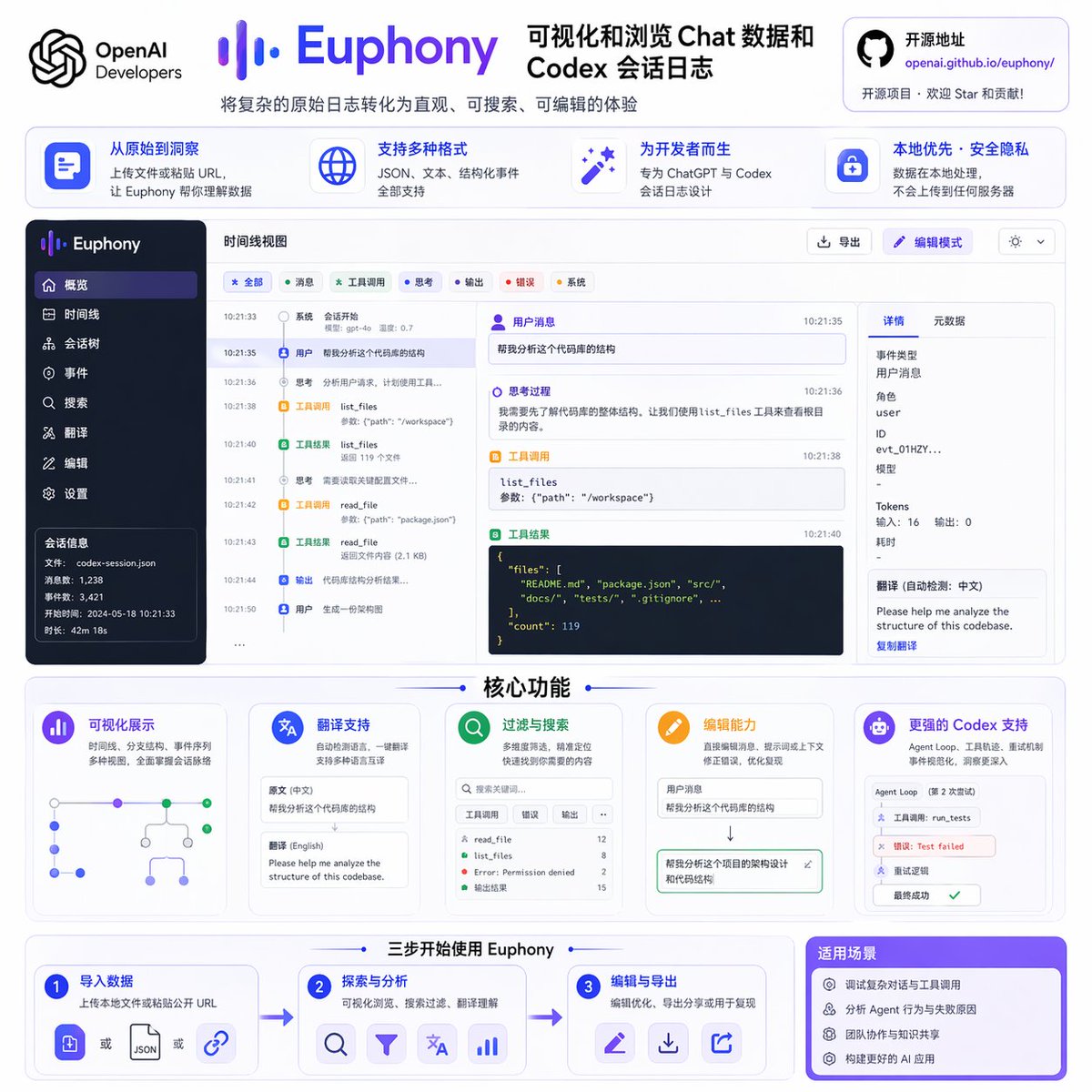
Introducing Euphony, an open-source tool for visualizing chat data and Codex session logs. Paste in a public URL or upload a local file, and Euphony turns the raw data into an easy-to-browse view. It supports translation, filtering, editing, and more.


🚨New preprint! We find evidence of LLMs enabling people to file lawsuits without lawyers (filing "pro se") at historically unprecedented rates in federal courts.👇 1/n

What happens when you combine voice, vision, and reasoning on-device? 🤔 Gemma 4 + a vision-language agent (VLA) running on NVIDIA Jetson Orin Nano shows how compact hardware can now handle real-world AI tasks using today’s open models—no cloud required. Get started: nvda.ws/4cU1ebL











We set out to replicate Kimi's 193 tok/s Qwen3.5-0.8B on M3 Max. Our baseline is already 178 tok/s, beating LMStudio (160) and llama.cpp (140) out of the box, but with tinygrad's custom kernel feature Claude cranked it to 195.7!




