Tweet épinglé

Introducing WolfBench: @WolframRvnwlf's new evaluation framework for models and agents, brought to you by @wandb
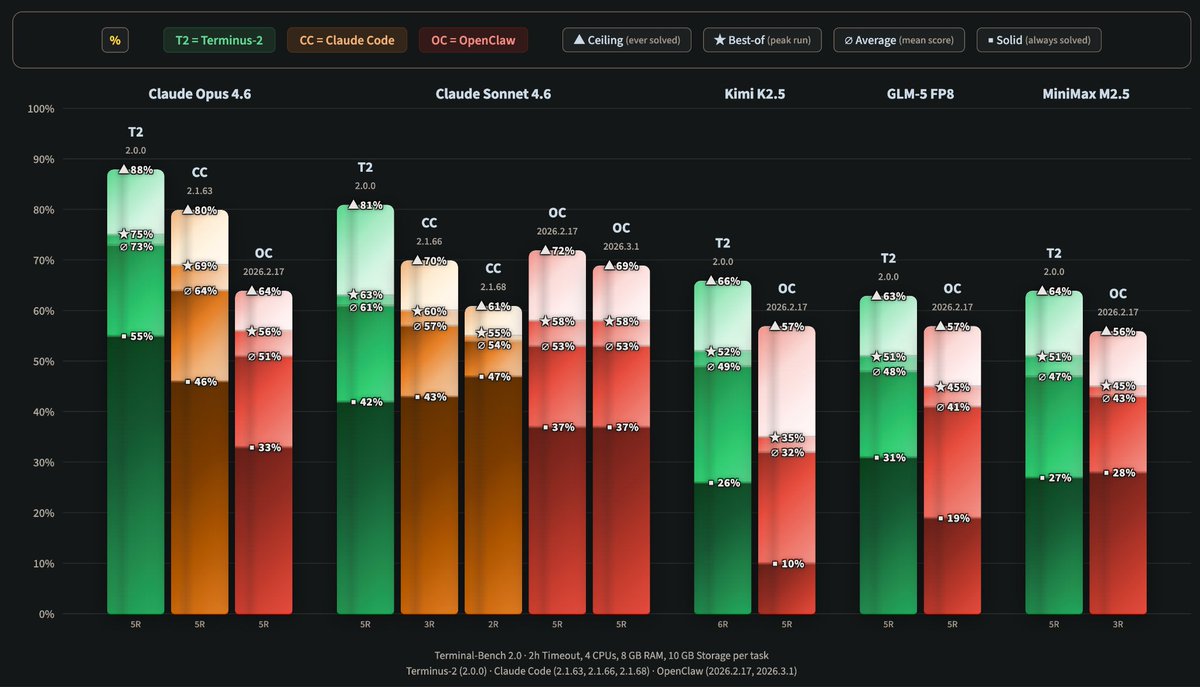
Single score metrics don't adequately describe model performance and capabilities. Here's how the new WolfBench framework solves that problem:
wandb.ai/wandb_fc/wolfb…
English