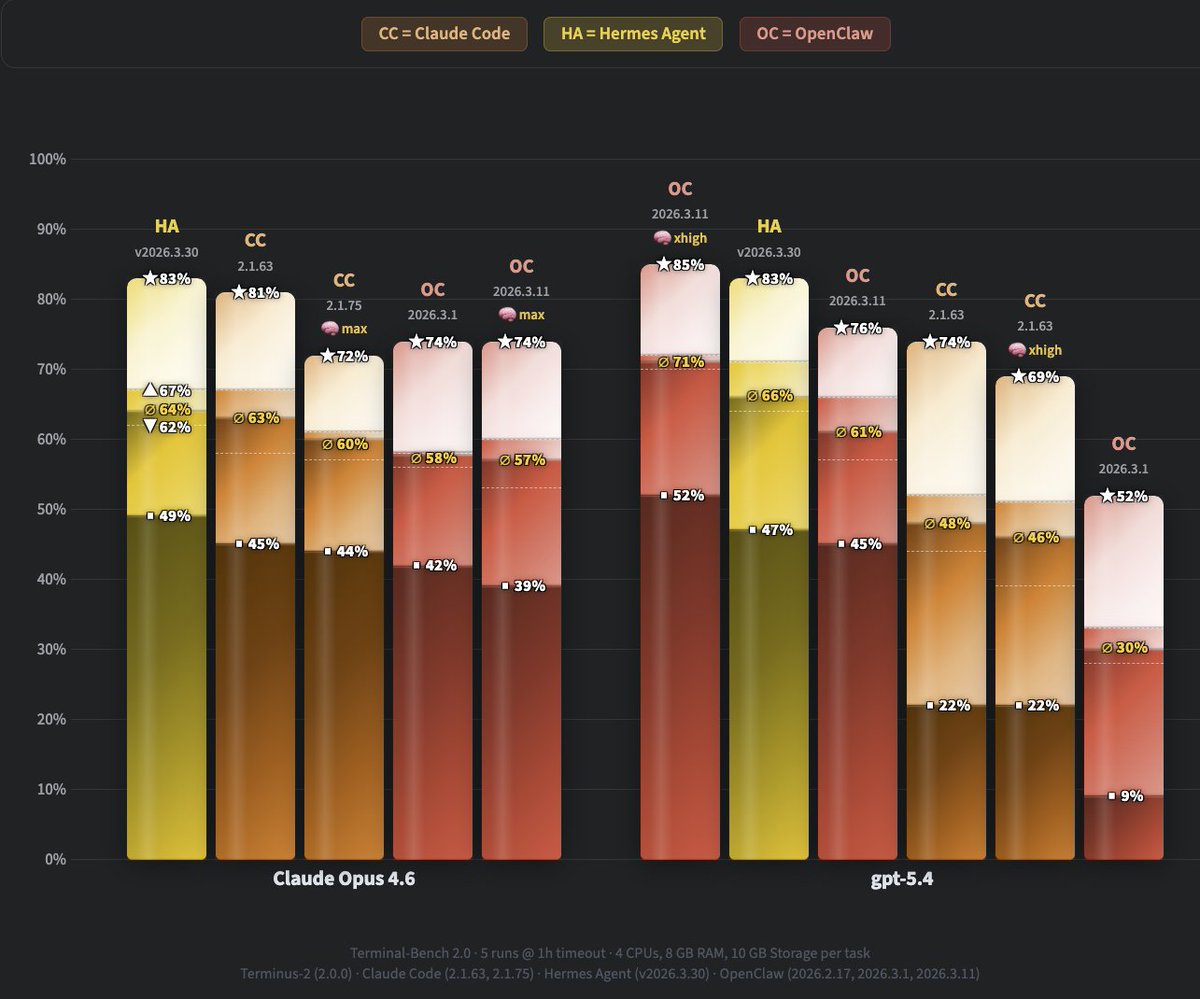
Sabitlenmiş Tweet

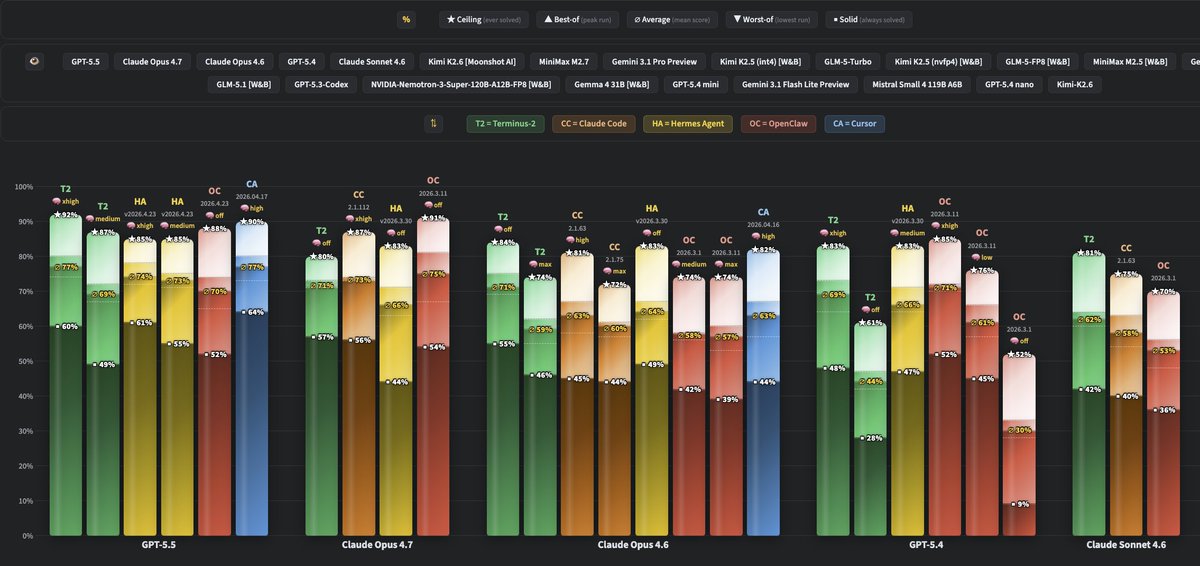
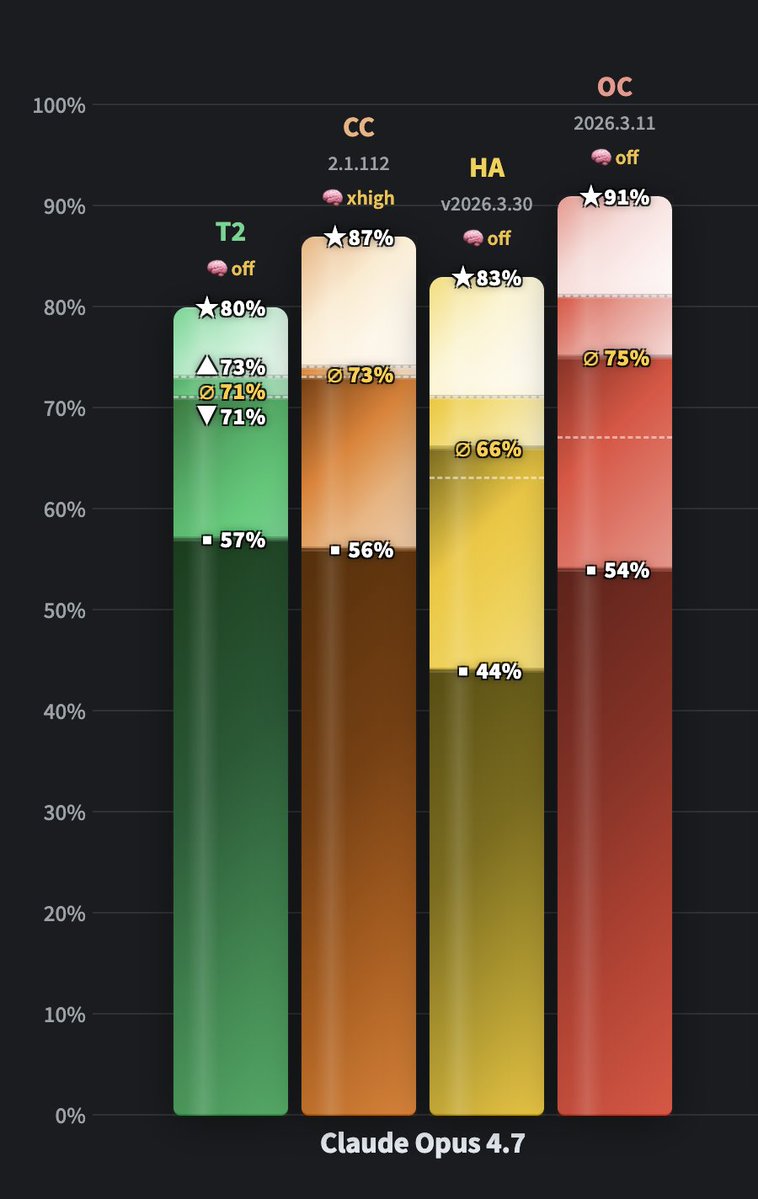
GPT-5.5 takes over WolfBench! It’s now the #1 model, ahead of Claude Opus 4.7 and 4.6, GPT-5.4, Sonnet 4.6, Kimi K2.6, Gemini 3.1 Pro, and more.
Notable findings after 30 runs (40h runtime, >1.7B tokens, ~$3K cost):
- @OpenAI's GPT-5.5 is the best model we ever tested.
- @cursor_ai's Agent CLI (CA) is the best agent we ever tested.
- @NousResearch's Hermes Agent (HA) outperformed OpenClaw (OC).
- With Hermes, going from medium to xhigh reasoning only improved consistency, not capability.
Note: This is WolfBench, where we look at more than just the average score, because one metric is not enough. The golden ∅ score is the actual 5-run average, which most other benchmarks report as their only score. ★ shows the ceiling (what percentage of the full benchmark this model+agent combination solved at least once across all runs). ■ shows the solid base (what percentage of the full benchmark it solved consistently in every run).

English