Tweet épinglé

devnulling
3.2K posts




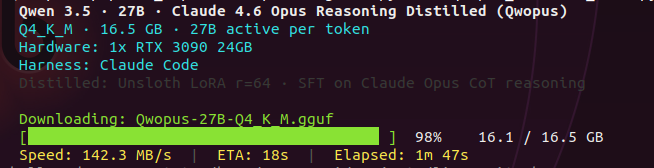
been daily driving qwen 3.5 27B dense. haven't even finished testing it properly and now claude opus reasoning gets distilled into the same base. things are dropping faster than i can benchmark. might pull this and test with claude code and opencode. first thing to check: does the jinja template bug carry over? the one that silently kills thinking mode when you use agent tools. if your server logs show thinking = 0, your model isn't reasoning and the server won't tell you. claude level reasoning on a single 3090. locally. we'll see.
first impressions of qwen 3.5 27B dense on a single RTX 3090. 35 tok/s. from 4K all the way to 300K+ context. no speed drop. hermes 4.3 started at 35 and degraded to 15 as context filled. qwen dense holds. MoE held 112 flat. 3x faster but only 3B of 35B active per token. architecture tradeoff. Q4_K_M on 16.7GB. native context 262K. pushed past training limit to 376K before VRAM ceiling on 24GB. tried q8 KV cache at 262K, speed collapsed to 11 tok/s. q4_0 KV is the sweet spot. flash attention mandatory. built in reasoning mode. the model thinks step by step before it answers. full chain of thought surviving Q4 quant. 1,799+ token thinking chains with self correction loops. on a single consumer GPU. gave it one prompt: "build a realtime particle galaxy simulation in one HTML file." 3,340 tokens. 95 seconds. one shot. ran on first load. full reasoning and coding in the video below. optimal config if you want to skip the hours of testing: llama-server -ngl 99 -c 262144 -fa on --cache-type-k q4_0 --cache-type-v q4_0 this is just the warmup. octopus invaders is next: 10 files, 3,400+ lines, zero steering. the prompt hermes quit at 22%. already more impressed than expected. full results coming soon.
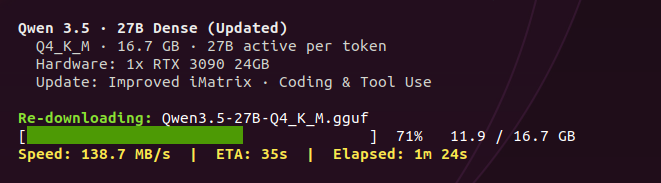
We're releasing our final update to Qwen3.5 GGUFs for improved performance. - Qwen3.5 GGUFs now use our new iMatrix data for better chat, coding & tool use. - New improved quant algorithm - Re-download 35B, 27B, 122B GGUFs: huggingface.co/collections/un… Guide: unsloth.ai/docs/models/qw…
i've been wanting to run this comparison for weeks. dense vs MoE. same param count. same GPU. completely different architecture. here's what caught my eye. hermes 4.3. 36B dense. 93.8% on MATH-500. 512K context. every single parameter active on every forward pass. no routing. no sparsity. pure dense transformer. qwen 3.5 is 35 billion parameters but only activates 3 billion per token. 256 experts, 8 routed + 1 shared per question. the rest sit idle. both fit on a single RTX 3090. i've been benchmarking qwen 3.5. 112 tok/s at 262K context. built a space shooter game, particle sim, full CLI tools with it. now i want to see what happens when the GPU has to process 12x more active parameters on every single token. downloading hermes right now. same GPU. same benchmarks. same prompts. dense vs MoE head to head on consumer hardware. which architecture wins on a single consumer GPU? place your bets. nobody's done this comparison yet. first results today.
testing Qwen3.5-35B-A3B latest optimized version by UnslothAI on a single RTX 3090. one detailed prompt. zero handholding. watch a 3B model scaffold an entire multifile game project autonomously. the setup: > model: Qwen3.5-35B-A3B (80B total, only 3B active per token) > quant: UD-Q4_K_XL by Unsloth (MXFP4 layers removed in latest update) > speed: 112 tok/s generation, ~130 tok/s prefill > context: 262K tokens > flags: -ngl 99 -c 262144 -np 1 --cache-type-k q8_0 --cache-type-v q8_0 > engine: llama.cpp > agent: Claude Code talk to localhost:8080 (llama.cpp now has native Anthropic API endpoint. no LiteLLM needed) q8_0 KV cache cuts VRAM usage in half vs f16 at 262K. -np 1 is default but worth noting. parallel slots multiply KV cache and at 262K that's an instant OOM. the prompt was more detailed than this but you get the idea: build a space shooter with parallax backgrounds, particle systems, procedural audio, 4 enemy types, boss fights, power-up system, and ship upgrades. 8 JavaScript modules. no libraries. game's called Octopus Invaders. gameplay footage dropping next.



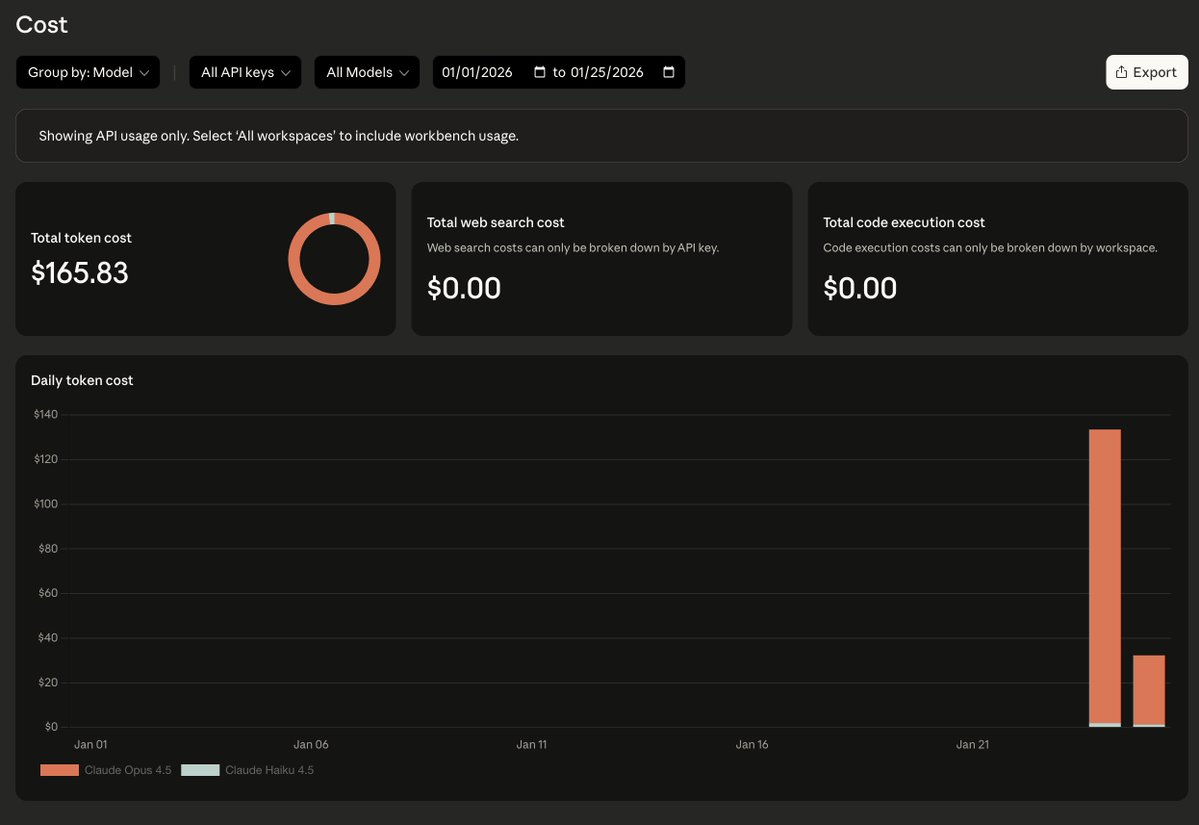



Heading into the new year stoked — with help from a friend with solid DSP experience, the FPV DSP-based detection is working, and early this morning the wide energy-scan front end came together for fast sweeps + targeted confirmation. Still evolving, but the momentum is real. 🐉





