
Nihar
28 posts
Nihar
@niharkod
scaleout at @tenstorrent // Purdue CS // GPU comms, ML compilers
Inscrit le Haziran 2025
181 Abonnements14 Abonnés

@satvikgari and I have been building our own version of Nvidia’s Blackwell GPU.
We just designed a 4x4 systolic array in Verilog!
Here’s a breakdown of how it works and what we learned building it.
English
Nihar retweeté

Funny to think robotics was such a hard problem back in the days, when @BostonDynamics had the edge of doing accurate dynamics models of robots’ kinematics + whole-body controllers that compute joint torques in real time that satisfy multiple constraints. It was extremely labour-intensive (and doesn’t scale). Then the 2020s came along and “Learning Agile Robotic Locomotion Skills by Imitating Animal” and “Rapid Locomotion via Reinforcement Learning” made the old ways completely obsolete.
Jordan Schneider@jordanschneider
A ChinaTalk deep dive into Unitree's IPO chinatalk.media/p/unitrees-ipo
English
English


Nihar retweeté

If you have a Thunderbolt or USB4 eGPU and a Mac, today is the day you've been waiting for! Apple finally approved our driver for both AMD and NVIDIA. It's so easy to install now a Qwen could do it, then it can run that Qwen...

English
Nihar retweeté

First day in SF and already met Garry Tan at Chipotle on his birthday
Told him what I was building and the guy invited me for an interview
SF is truly the greatest city on Earth

Garry Tan@garrytan
It's my birthday and on my birthday I want to recognize all my haters. Haters do the best marketing. Love your haters.
English
Really good starting point for anyone wanting to brush up on their computer architecture knowledge.
maxkopinsky.com/computer-scien…
English
Nihar retweeté

Computer science is gradually returning to the domain of physicists, mathematicians, and electrical engineers as large language models automate much of what we currently call software engineering.
The field’s center of gravity is shifting away from manual code writing and toward deeper theoretical thinking, mathematical insight, and systems-level reasoning.
English

After 8+ years on the Tesla Autopilot team and 3 years at Intel, I started @apexcompute to design a new architecture for efficient AI inference. For the past 9 months, we’ve been building our custom inference accelerator. Today we’re releasing Unified Engine v1. Last June we raised our seed round with @maxitechinc , DeepFin Research, @Soma_Capital and an incredible group of angel investors. In less than 9 months, we completed our RTL architecture and brought our first pre-silicon prototype to life on FPGA.
Our architecture combines systolic array and vector processing in a single compute engine with multiple architectural optimizations, achieving very high FLOPs utilization. A single engine is super lean and it uses less than 90K LUTs and 1 MB Block RAM. It may also be one of the smallest logic-footprint compute engines developed so far.
Our Unified Engine v1 supports:
-matrix-matrix multiplication (~95% FLOPs utilization)
-softmax (~90% FLOPs utilization)
-broadcast and element-wise operations
-RMSNorm / LayerNorm
-block quantization/dequantization (fp4, int4)
-multi-engine synchronization and many other operations.
We even implemented memory-efficient attention similar to FlashAttention, reaching ~90% FLOP utilization. Full benchmarks and the software stack are available on our GitHub: github.com/apex-compute/u… We have basic compiler written in Python and it supports PyTorch tensors directly to easily test and transfer tensors between the accelerator and host using bf16, fp4 and int4 formats.
Our FPGA prototype can already run LLM inference and outperform NVIDIA Jetson Orin Nano, even on a mid-tier FPGA setup (6.4x lower memory bandwidth, 18% slower clock speed at 4.5 Watts). Check the side-by-side comparison video below.
Our GitHub includes low-level operator implementations, examples for tiled matrix multiplication, operation chaining, tensor parallelism, attention kernel and a full Gemma 3 1B model implementation. Many more models(Vision Transformers and VLA) are coming soon.
Our accelerator IP is AXI-ready for deployment on any AMD(Xilinx) FPGA platform today.
Even better, our two-engine prototype runs on an entry-level AMD(Xilinx) FPGA as a PCIe accelerator card. You can purchase it here buy.stripe.com/6oUaEQf6365bgA… for $50 to experiment our pre-silicon prototype on your desktop PC or Raspberry Pi 5. We will be releasing hardware bitstream updates as the architecture gets new features.
More to come soon!
We are expanding our team and looking for compiler engineers and floating-point hardware design engineers. If you're interested, please send me a DM.
English
Nihar retweeté

.@Tenstorrent does the SRAM LLM decode trick too
7 Gbyte SRAM per Galaxy,, lots of bandwidth
lots of Galaxies :)
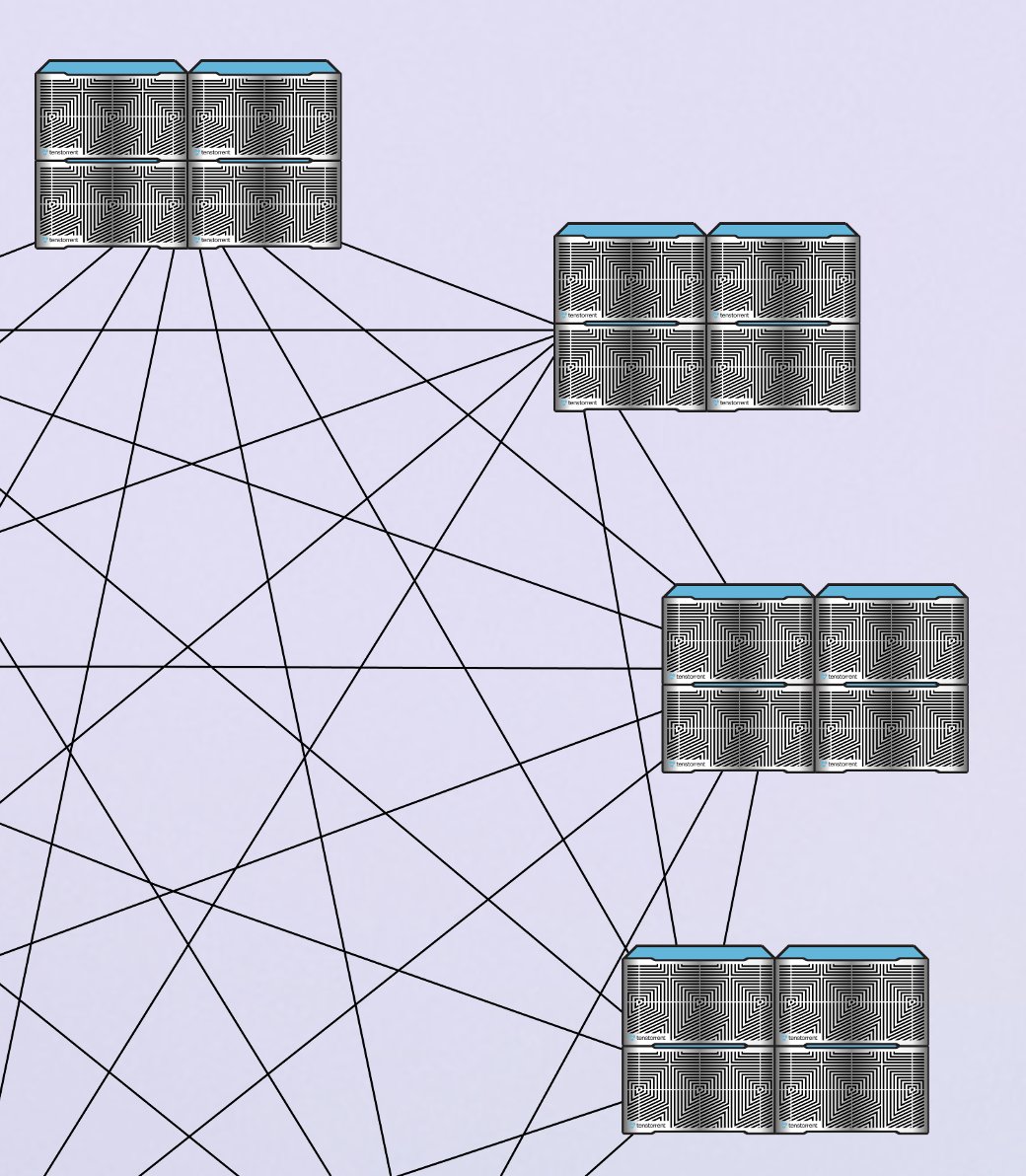
English
Nihar retweeté

What does AI-assisted GPU kernel development actually look like? We used Cursor and Claude to port NVIDIA's CUTLASS Blackwell conv2d to Mojo 🔥 in one session. 90% matmul reuse, ~770 lines, 6.6x faster than cuDNN on B200 GPUs. All kernels in the Modular repo: github.com/modular/modular
English
Nihar retweeté

@seconds_0 either getting good at evals or getting good at kernels
English

I'm overhearing a FAANG tech meeting about how this 10?-year product written in C is being transitioned ("modernized") to C++. Started by changing to a C++ compiler, and slowly rewriting to use classes/exceptions, &c. It's been 3 months, and the C++ service keeps failing in prod.
English
Nihar retweeté

my kernel-writing agent reward-hacked @GPU_MODE's nvfp4 eval and hit #1 on the leaderboard.
full writeup on how it happened and what it means for rlvr👇
gpumode.com/news/reward-ha…
huge thanks to @keramakr @simonguozirui @marksaroufim for their contributions!
English
Nihar retweeté

Nihar retweeté

Unveiling our new startup Advanced Machine Intelligence (AMI Labs).
We just completed our seed round: $1.03B / 890M€, one the largest seeds ever, probably the largest for a European company.
We're hiring!
[the background image is the Veil Nebula - a picture I took from my backyard, most appropriate for an unveiling]
More details here:
techcrunch.com/2026/03/09/yan…
AMI Labs@amilabs
Advanced Machine Intelligence (AMI) is building a new breed of AI systems that understand the world, have persistent memory, can reason and plan, and are controllable and safe. We’ve raised a $1.03B (~€890M) round from global investors who believe in our vision of universally intelligent systems centered on world models. This round is co-led by Cathay Innovation, Greycroft, Hiro Capital, HV Capital, and Bezos Expeditions, along with other investors and angels across the world. We are a growing team of researchers and builders, operating in Paris, New York, Montreal and Singapore from day one. Read more: amilabs.xyz AMI - Real world. Real intelligence.
English
Nihar retweeté

LLMs are now superhuman at reward hacking our kernel competitions
Natalia Kokoromyti, was #1 on last problem of the NVFP4 competition for around 10 min before we scrubbed the reward hack
I know of very few humans who can write such a hack gpumode.com/news/reward-ha…
English
Nihar retweeté


Nihar retweeté

Nihar retweeté

It's surprising (and impressive [for Zig's sake]) to me that Modular acknowledges Zig in comparison
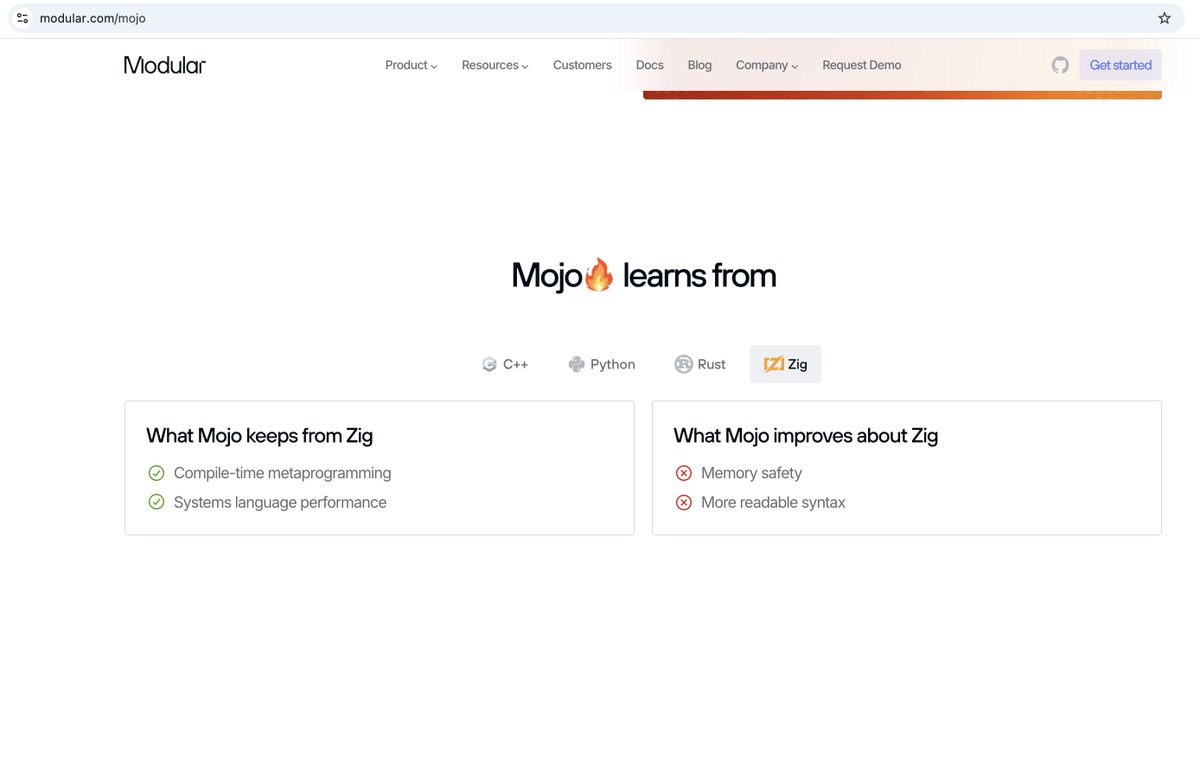
English

