
Interesting! Few years back, I did experiment and observed 4x reduction without regression. In some cases, it even gave boost. But still entailed computing that giant LxL matrix so I dropped it.
Ashwin Gopinath@ashwingop
English
Tsendsuren
22K posts

@TsendeeMTS
Research scientist at Google DeepMind | previously at Microsoft Research and Postdoc at UMass. Views are my own. Most tweets in Mongolian 🇲🇳.

Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation. Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers. 🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth. 🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale. 🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead. 🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains. 🔗Full report: github.com/MoonshotAI/Att…


Say hi to Exclusive Self Attention (XSA), a (nearly) free improvement to Transformers for LM. Observation: for y = attn(q, k, v), yᵢ and vᵢ tend to have a very high cosine similarity Fix: exclude vᵢ from yᵢ via zᵢ = yᵢ - (yᵢᵀvᵢ)vᵢ/‖vᵢ‖² Result: better training/val loss across model sizes; increasing gains as sequence length grows. See more: arxiv.org/abs/2603.09078
The winding river towards Monte Fitz Roy, Patagonia
We’re also launching Immersive Navigation - our biggest navigation upgrade in over a decade! A new vivid 3D view better reflects your surroundings, with helpful road details like lanes, crosswalks, traffic lights etc. Gemini models analyze real world imagery from Street View and aerial photos to give you an accurate view of landmarks along your route. Starts rolling out in the US today.

Torres del Paine, Chile
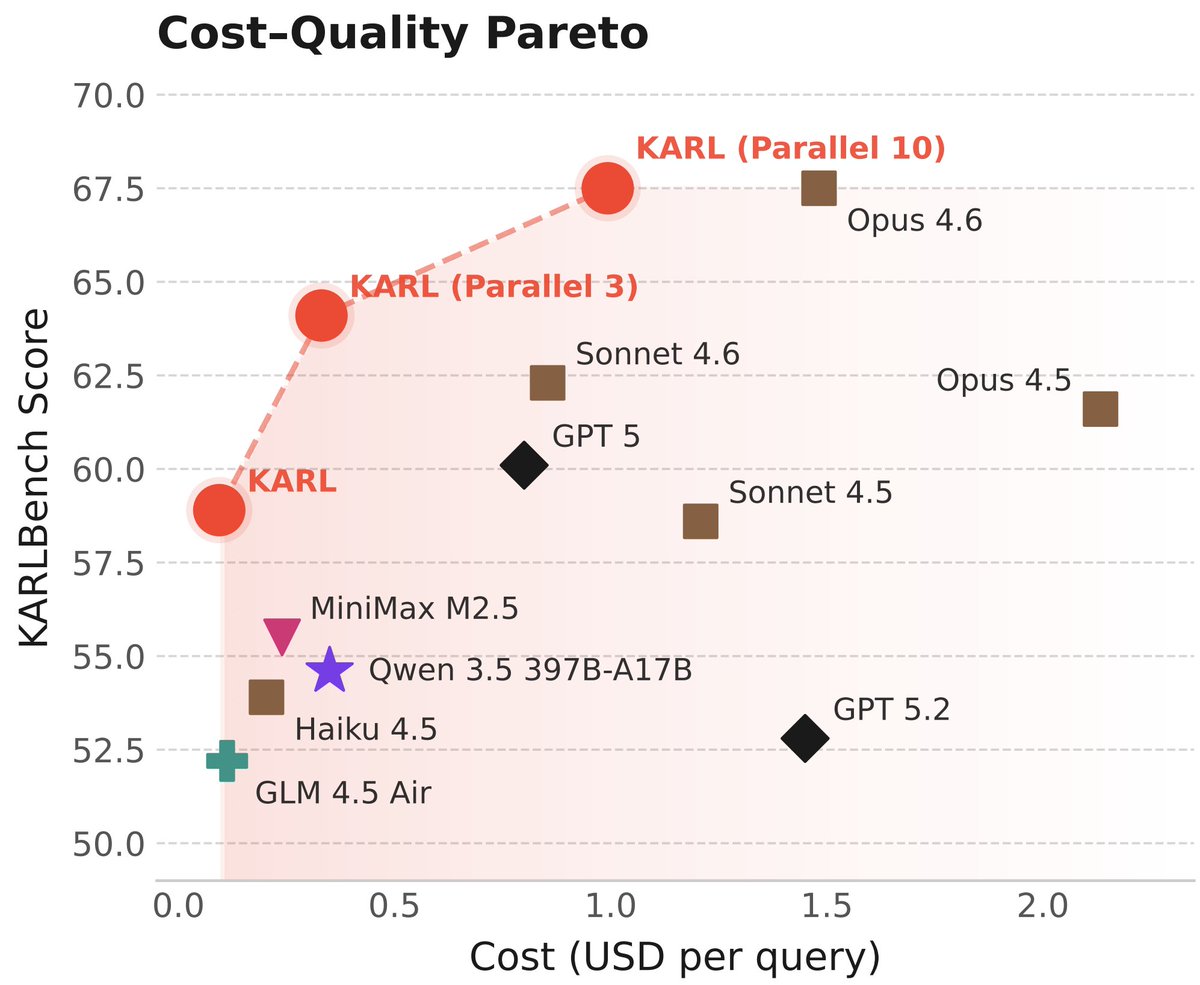
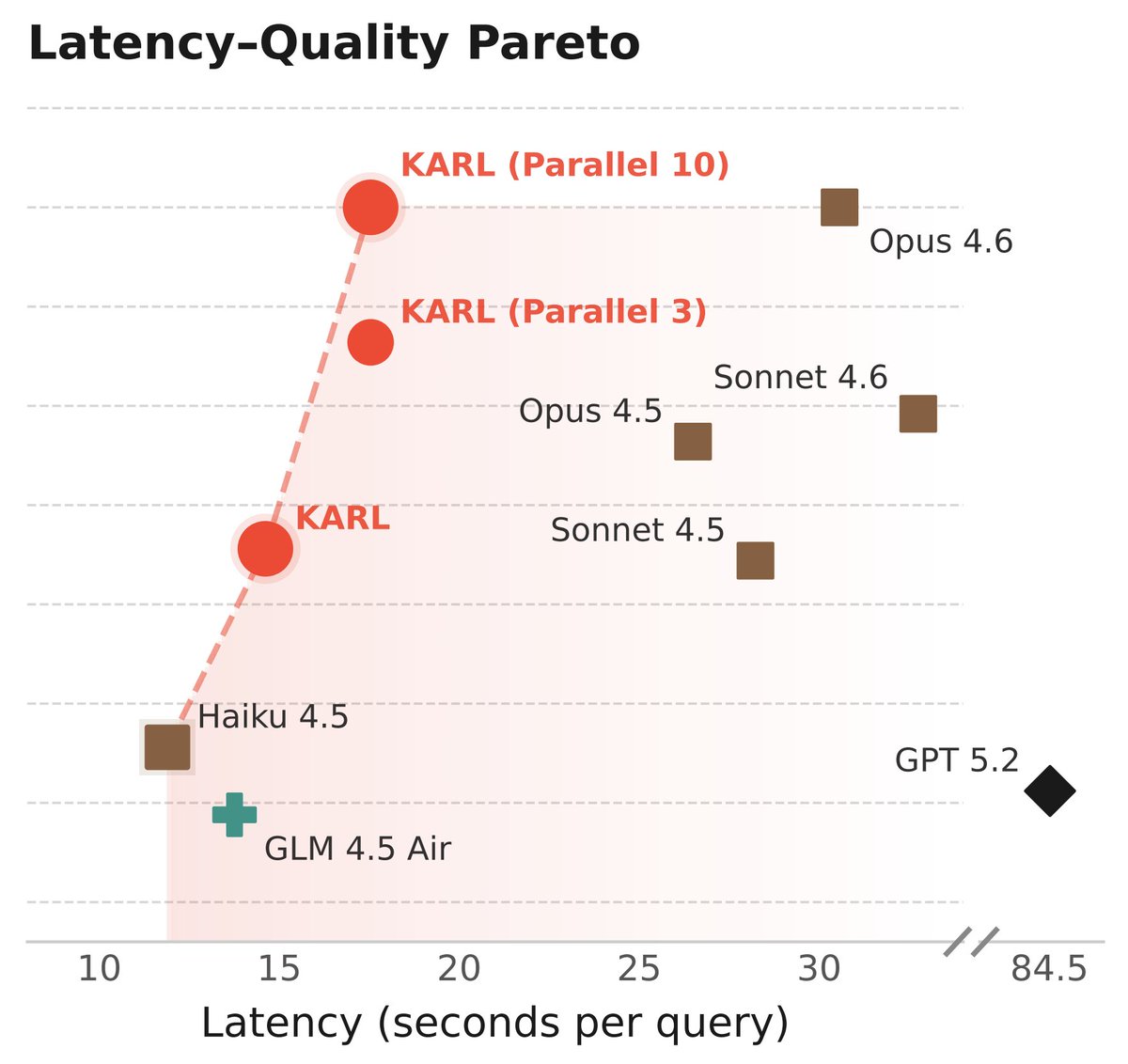
Reusability influenced every decision we made: * Off-policy RL for simplicity and robustness. No quality tradeoffs: arxiv.org/abs/2602.19362 * Simple, elegant test-time compute via parallel thinking to control latency * RL-learned context compression * Multi-task RL for modularity






Doc-to-LoRA: What if you could online distill documents into your LLM weights without training? 🚀 Stoked to share our new work on instant LLM adaptation using meta-learned hypernetworks 📷📝 Building on our previous Text-to-LoRA work, we doc-condition a hypernetwork to output LoRA adapters, improving the base LLM's effective context window. The hypernetwork is meta-trained on 1000s of summarization tasks and shows remarkable compression capabilities at low latency 📈 🧑🔬 Work led by @tan51616 with @edo_cet & Shin Useka at @SakanaAILabs 📷



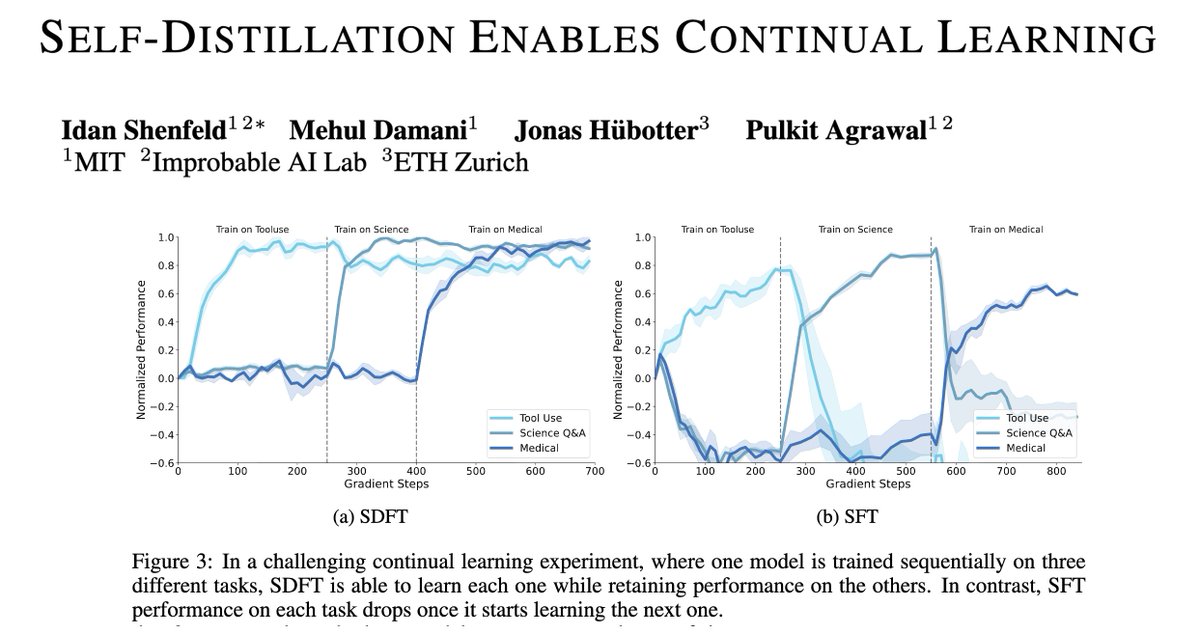
Introducing Self-Distillation Fine-Tuning (SDFT), a simple method that enables on-policy learning from expert demos—no rewards needed. Key insight: Putting SFT data in-context to turn the model into its own teacher, producing on-policy signals that preserve prior skills and improve generalization. (3/n)








