
Liu Liu
1.3K posts

Liu Liu
@liuliu
Maintains https://t.co/VoCwlJ9Eq0 / https://t.co/bMI9arVwcR / https://t.co/2agmCPOZ2t. Wrote iOS app Snapchat (2014-2020). Founded Facebook Videos with others (2013). Sometimes writes at https://t.co/Gyt4J9Z9Tv
San Francisco, CA शामिल हुए Nisan 2010
270 फ़ॉलोइंग2.3K फ़ॉलोवर्स

I joined Anthropic as a member of the technical staff.
Excited to work on frontier modeling at a place with unwavering values and a generational mission.
English

English
To folks who benchmark the new M5 Max with @drawthingsapp: using Exact models otherwise the dequant will hurt the performance on chips with specialized accelerators. It is just a hair bit but nowadays mflux is really fast (Good job @filipstrand) so every bit matters.

English
@ivanfioravanti Also, be more specific: since we use the non-Exact as "recommended", it is fine to benchmark to reflect user experience. I am more talking about benchmark against other implementations and dequant will hurt us in these cases. Honestly, it is just a few milliseconds...
English
@ivanfioravanti Yes, 6-bit will be slower just because it is slightly more arithmetic intense than 8-bit. It is a legacy issue (and I am still unsure either way) that for bigger models, we call 8-bit standard and the FP16 one Exact 🤪
English
@liuliu Thanks Liu, I tested them all before publishing and I confirm 6bit is slower.
English
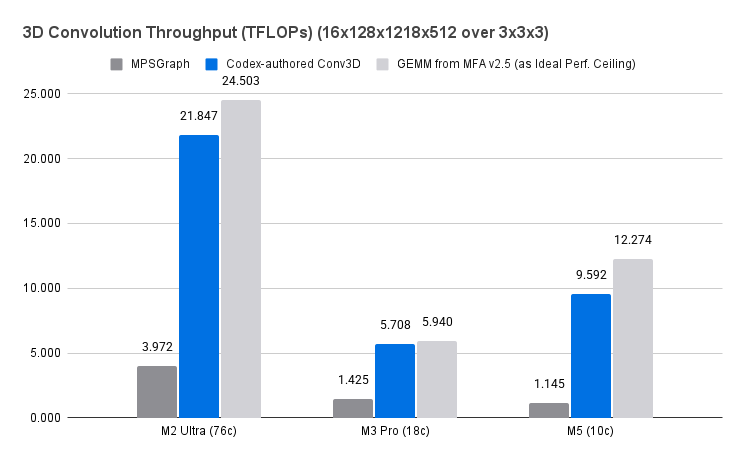
@norpadon I was always fascinated by stories like MPSGraph, which was an ambitious project, must be conjured into existence (pre-AI) by one unsound hero, but ultimately failed on its own weight (like, implementing ANE as alternative backend must be massive but see how that brings us).
English

@liuliu No, I never worked at Apple. But I spent countless hours trying to make MPSGraph programs work and finding one bug or undocumented behaviour after another
The official WWDC presentations contain the code that cannot possibly compile…
English
@liuliu MPSGraph is a fucking cursed abomination. Stay away lmao
English
Tokens -> performance.
Liu Liu@liuliu
Have a hunch that the Conv3D in MPSGraph is not well-maintained. BRB.
English
@lefttailguy Adobe's problem is not their product. It is their margin cannot be maintained with AI disruptions. Buying up these companies won't solve that issue. New companies will pop up and take their margin. Doing this just provides exit liquidity to VCs to fund future competitions.
English

Adobe should buy Higgsfield, Fal, Krea, Flora, just roll up the whole damn thing. Most of these folks don't have sustainable unit economics. I think they'll take the money. They'd massively benefit from Adobe's distribution. It's time for incumbents to start overpaying.
English
People who say "copyright" and GPL in the same sentence don't see the irony nowadays. GPL is "copyleft", meant to use "copyright" to attack "copyright". It is never about grant you the "copyright" to use.
John Carmack@ID_AA_Carmack
I know there is some overlap between open source and anti-AI activists, but I have a hard time reconciling it. My million+ open source LOC were always intended as a gift to the world. Yes, I would make arguments about how it would strengthen our communities, and the GPL would prevent outright exploitation by our competitors, but those were to allay fears of my partners to allow me to make the gift. AI training on the code magnifies the value of the gift. I am enthusiastic about it! Some people do look at open source as a tool for social change, career advancement, or reputation building, but those are all downstream of the gift.
English
When everyone is a micromanager now, I wish the Greatest Micromanager of All Time @JeffBezos would share his SKILL.md
English


@anemll Probably some overhead from non-matmul path. If it is matmul heavy, should be around 3.5x to 4x. Honestly the difficult part for me now (on M5 Max) is to eliminate these previously overlooked overheads: model loading, lowering, kernel launch, not enough kernel fusion etc.
English

Some benchmark in M5 Max AI GPU ~ x3 vs M4 Max
browser.geekbench.com/ai/v1/compare/…
That is using NAX units on GPU

Anderson🌊@midnight_john1
English
@awnihannun What about learnable embeddings (like the embeddings in Gemma 3n)? LoRA is not convincing to me as a sleep mechanism too.
English
I've been thinking a bit about continual learning recently, especially as it relates to long-running agents (and running a few toy experiments with MLX).
The status quo of prompt compaction coupled with recursive sub-agents is actually remarkably effective. Seems like we can go pretty far with this. (Prompt compaction = when the context window gets close to full, model generates a shorter summary, then start from scratch using the summary. Recursive sub-agents = decompose tasks into smaller tasks to deal with finite context windows)
Recursive sub-agents will probably always be useful. But prompt compaction seems like a bit of an inefficient (though highly effective) hack.
The are two other alternatives I know of 1. online fine-tuning and 2. memory based techniques.
Online fine-tuning: train some LoRA adapters on data the model encounters during deployment. I'm less bullish on this in general. Aside from the engineering challenges of deploying custom models / adapters for each use case / user there are a some fundamental issues:
- Online fine-tuning is inherently unstable. If you train on data in the target domain you can catastrophically destroy capabilities that you don't target. One way around this is to keep a mixed dataset with the new and the old. But this gets pretty complicated pretty quickly.
- What does the data even look like for online fine tuning? Do you generate Q/A pairs based on the target domain to train the model? You also have the problem prioritizing information in the data mixture given finite capacity.
Memory based techniques: basically a policy for keeping useful memory around and discarding what is not needed. This feels much more like how humans retain information: "use it or lose it". You only need a few things for this to work:
- An eviction/retention policy. Something like "keep a memory if it has been accessed at least once in the last 10k tokens".
- The policy needs to be efficiently computable
- A place for the model to store and access long-term memory. Maybe a sparsely accessed KV cache would be sufficient. But for efficient access to a large memory a hierarchical data structure might be beter.
English