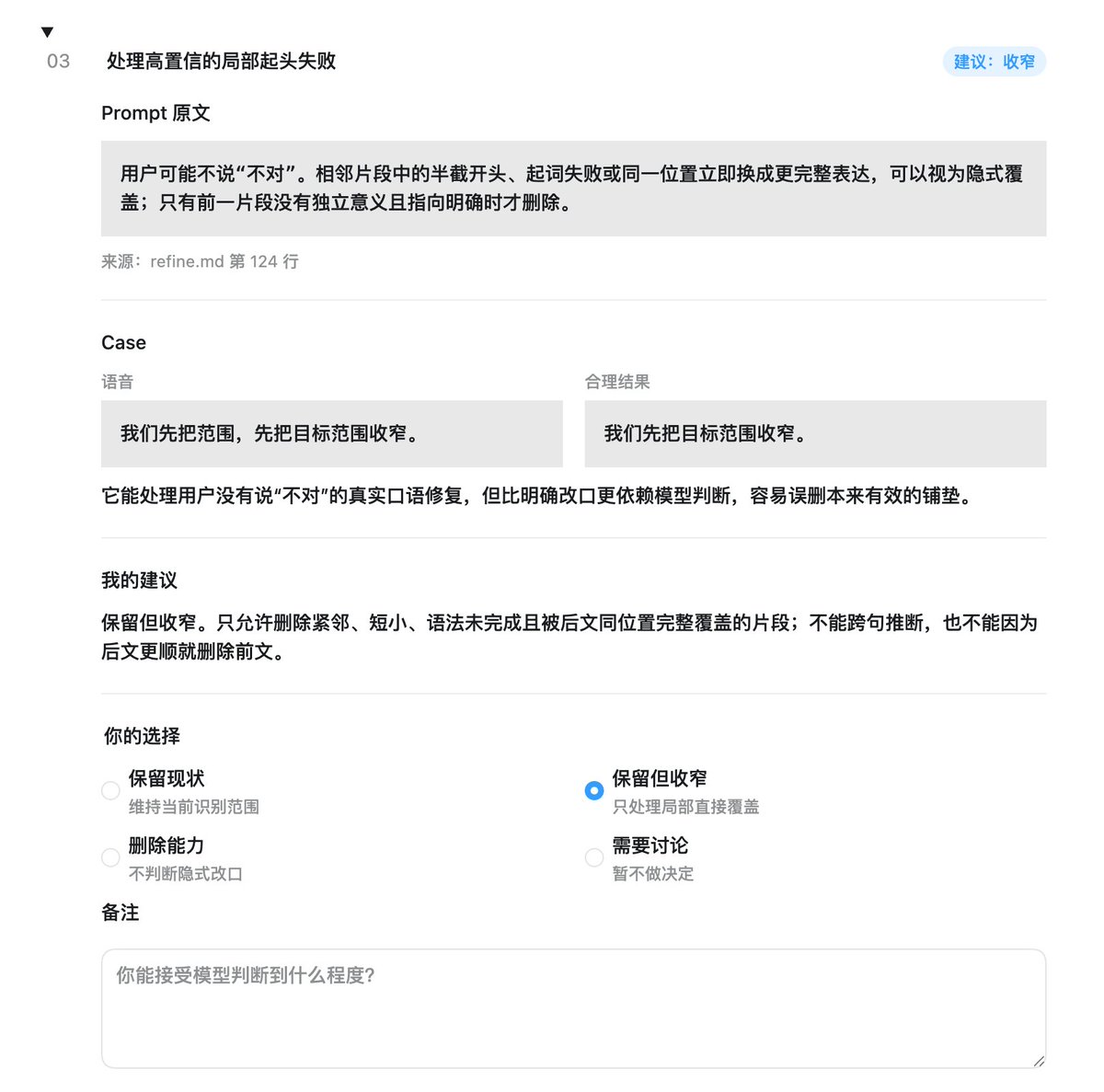
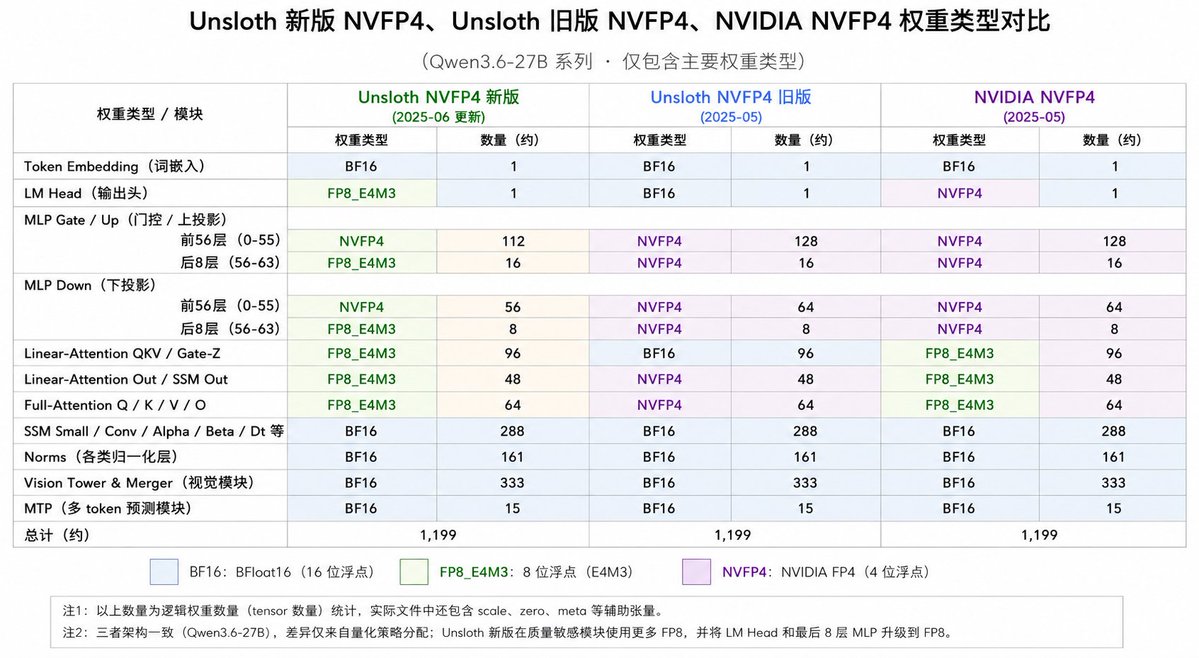
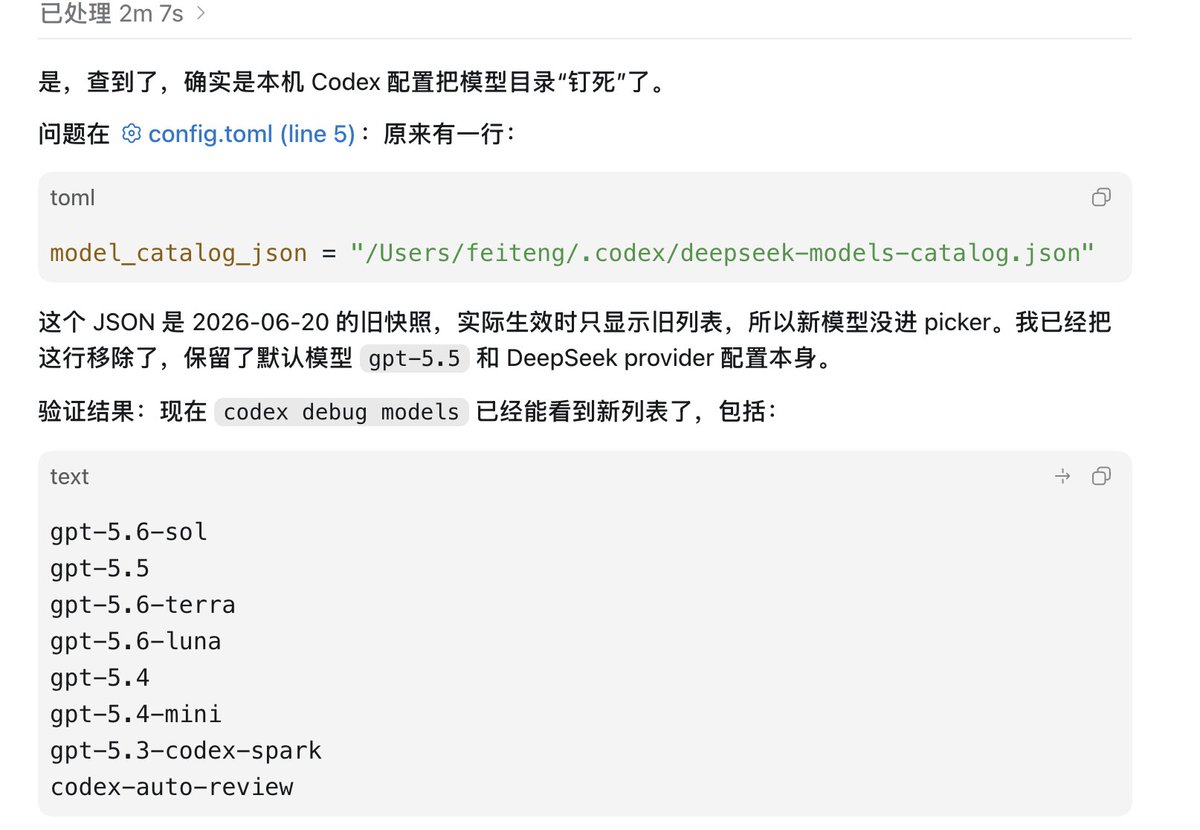
Sabitlenmiş Tweet

太顶了,用 @EdgeSpeak_HQ MCP 在 Codex 里面一句话就做出了 视频的卡拉 OK 字幕
› 用 EdgeSpeak MCP 转录和对齐 video.mp4 并制作成 卡拉 OK 字幕放在当前目录下
视频来源 x.com/AnthropicAI/st…
Anthropic@AnthropicAI
New Anthropic research: A global workspace in language models. Of everything happening in your brain right now, only a tiny fraction is consciously accessible—thoughts you can describe, hold in mind, and reason with. We found a strikingly similar divide inside Claude.
中文