पिन किया गया ट्वीट

English
Mateusz Mirkowski
1.7K posts

@visualdevguy
🚀Product engineer ⚡MVP builder 🦞OpenClaw ❤️AI lover 😇13 years in IT

Learn to code first, then use AI? Or Start with AI, learn as you go? Which is better?
Qwen3.5-27B, ran locally on M3 Max, sustaining coherence over 160K+ tokens and 469 tool calls to play a run of Slay The Spire*: *(not well, it died in Act 2, but managed maintain coherence + tool correctness throughout. might've done better w/ thinking, which was off for speed)








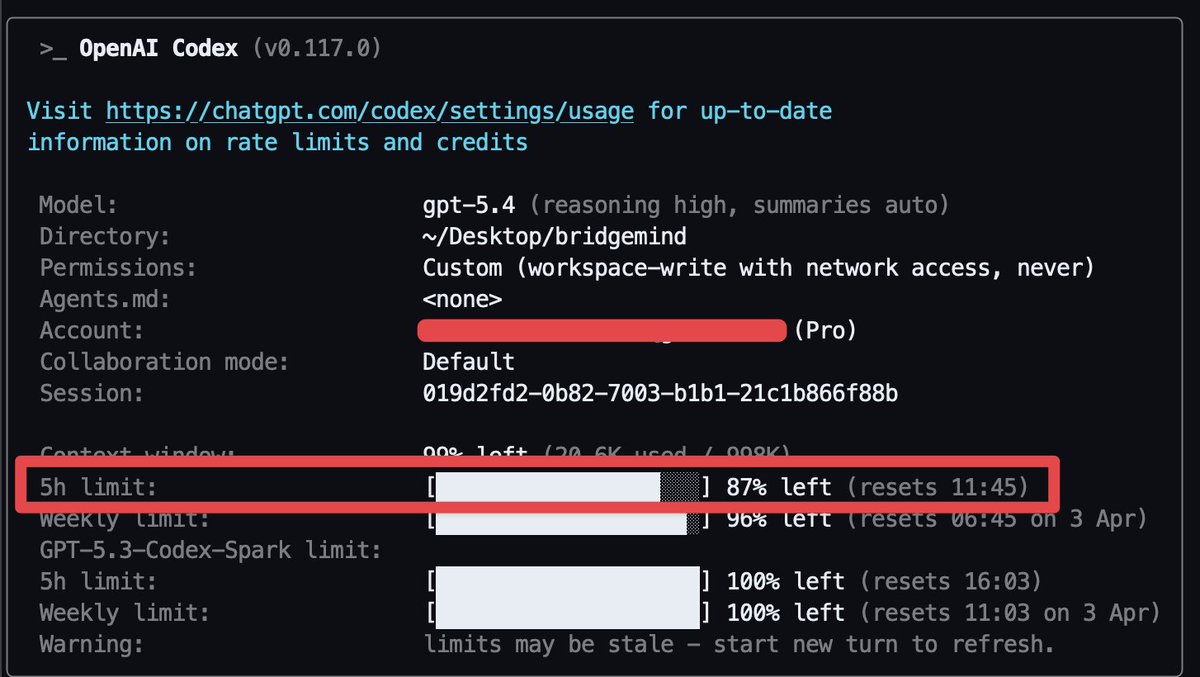



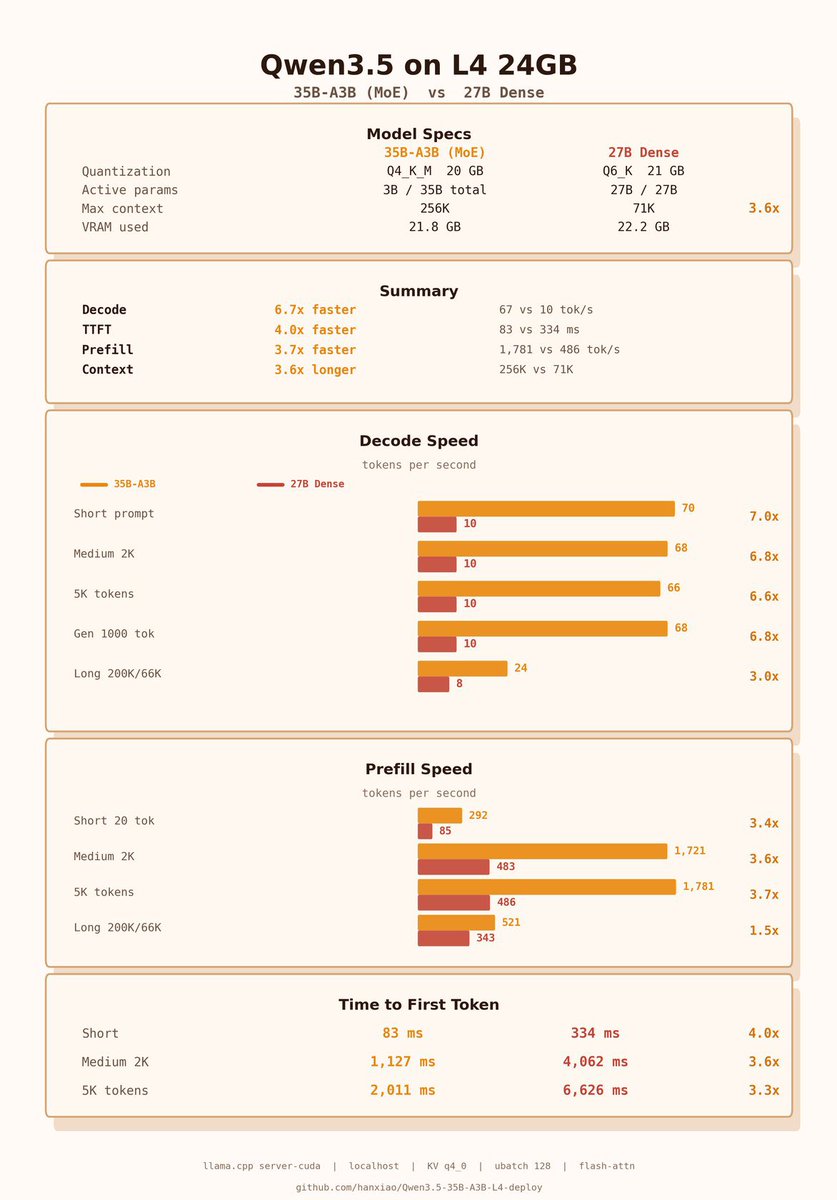



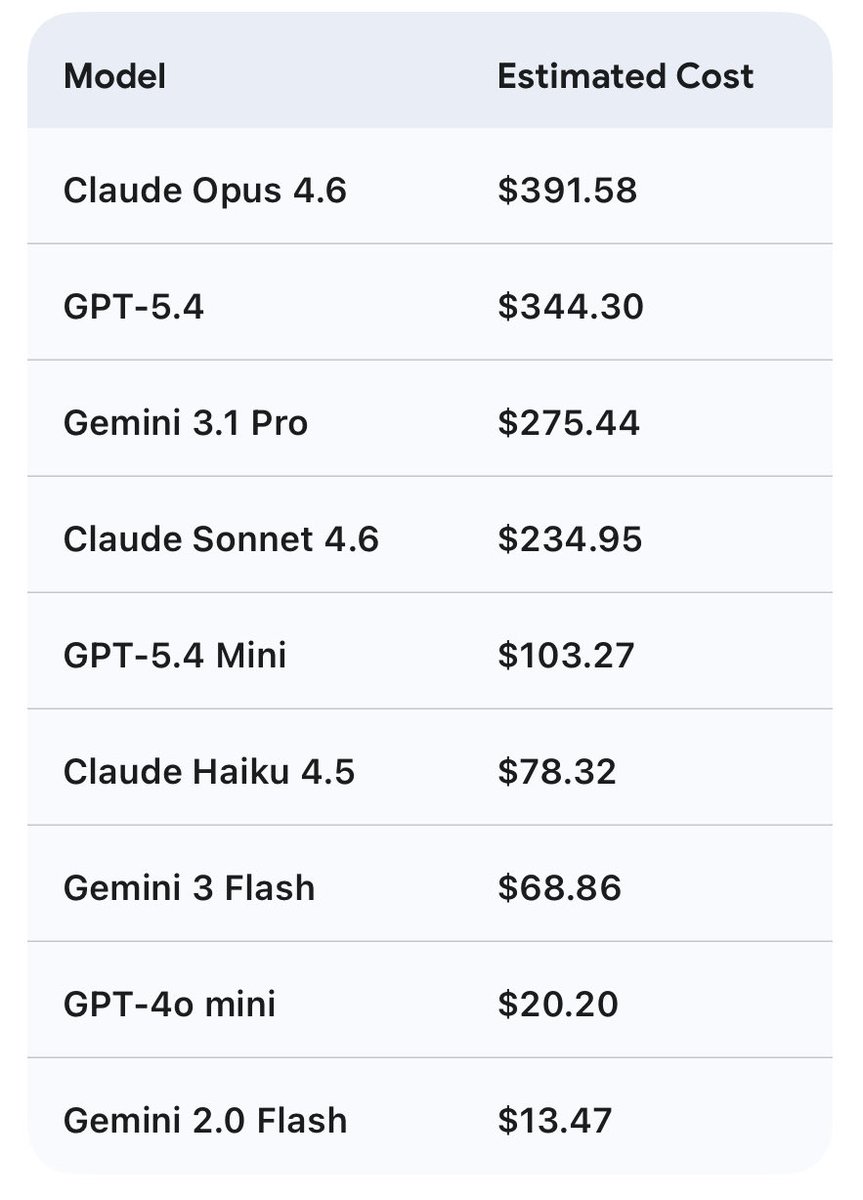
Qwen 27b on the 3090 saving me a bag. This is cost savings for 7 days of usage, w/ Hermes agent. Assuming 80% cache hit (unlikely) and no cache timeout. This is conservative. 27b is between sonnet and 5.4 mini This is just my tokens in/out w/ api costs, assuming no rate limits. Obviously cheaper w/ coding plans $200/m but would be hitting limits likely.




