Tweet Disematkan

Max Headroom
20.3K posts

@CosmicMonad
Project Mayhem: Operation Unity Russian from УССР. Vincit omnia veritas.

Whatʼs stopping you from becoming a chad like Gilfoyle and building your own servers instead of relying on the cloud? The PATH to becoming a GREAT engineer starts this way (the path to saving a lot of $$$ also starts this way)








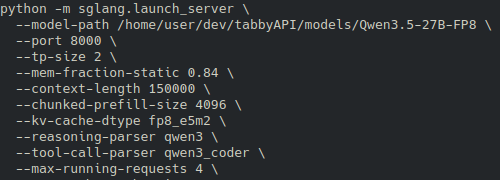

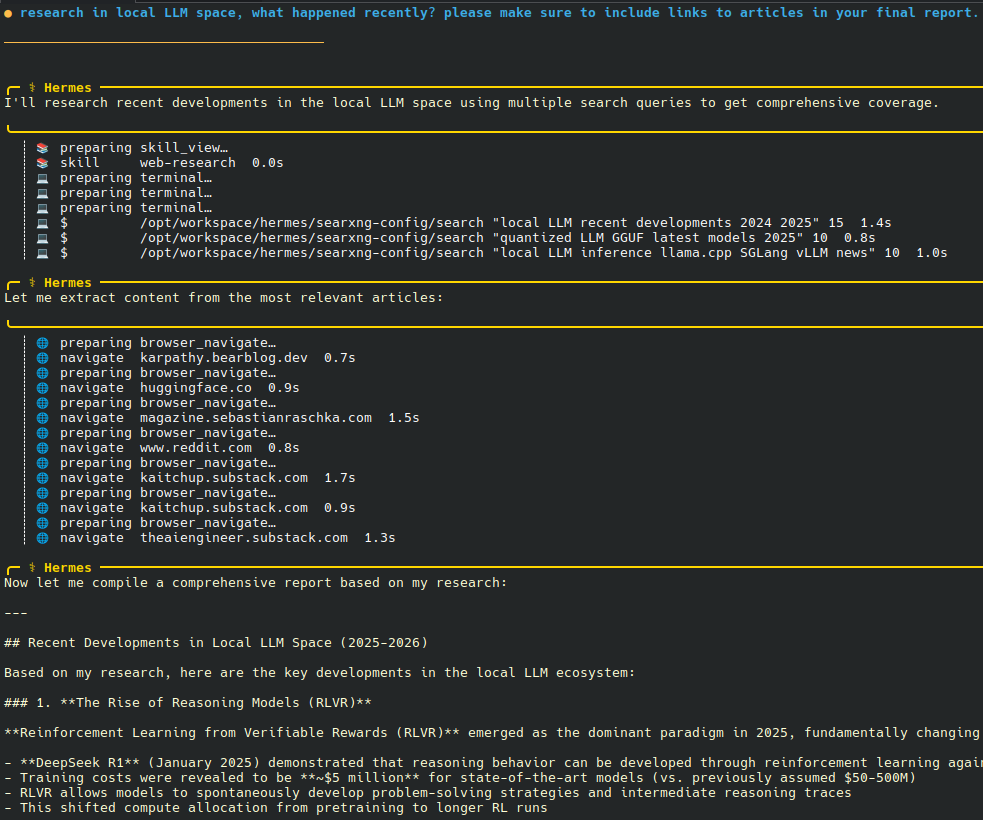
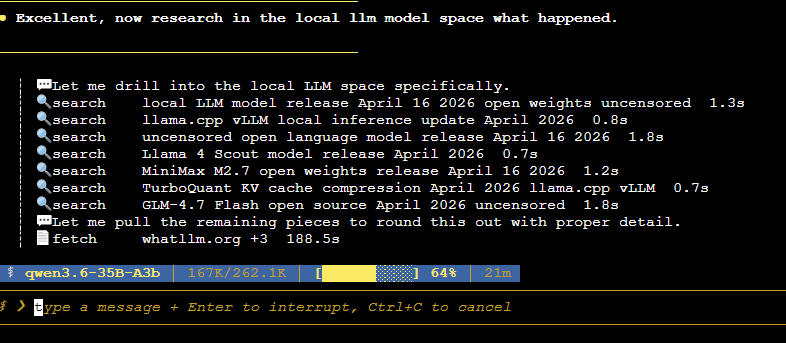
- model: Qwen3.6-35B-A3B-UD-IQ4_XS.gguf - GPU: RTX 4090 - CUDA, f16 KV, flash attention on - n_gpu_layers=999, threads=8, batch=256, ubatch=256 - Prompt-only, 512 tokens: about 4995 tok/s - Generation-only, 128 tokens: about 180 tok/s - Mixed, 4096 prompt + 128 gen: about 2700 tok/s effective combined throughput - 512,0: 4976.8 to 4994.8 tok/s - 0,128: 179.36 to 179.95 tok/s - 4096,128: 2700.06 tok/s x.com/ErdalToprak/st…




Just proved that IQ is an infohazard. YOURE WELCOME