Sabitlenmiş Tweet

Max Headroom
20.3K posts

@CosmicMonad
Project Mayhem: Operation Unity Russian from УССР. Vincit omnia veritas.



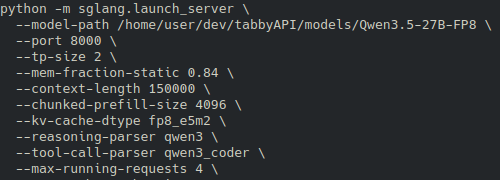

- model: Qwen3.6-35B-A3B-UD-IQ4_XS.gguf - GPU: RTX 4090 - CUDA, f16 KV, flash attention on - n_gpu_layers=999, threads=8, batch=256, ubatch=256 - Prompt-only, 512 tokens: about 4995 tok/s - Generation-only, 128 tokens: about 180 tok/s - Mixed, 4096 prompt + 128 gen: about 2700 tok/s effective combined throughput - 512,0: 4976.8 to 4994.8 tok/s - 0,128: 179.36 to 179.95 tok/s - 4096,128: 2700.06 tok/s x.com/ErdalToprak/st…






Just proved that IQ is an infohazard. YOURE WELCOME


⚡ Meet Qwen3.6-35B-A3B:Now Open-Source!🚀🚀 A sparse MoE model, 35B total params, 3B active. Apache 2.0 license. 🔥 Agentic coding on par with models 10x its active size 📷 Strong multimodal perception and reasoning ability 🧠 Multimodal thinking + non-thinking modes Efficient. Powerful. Versatile. Try it now👇 Blog:qwen.ai/blog?id=qwen3.… Qwen Studio:chat.qwen.ai HuggingFace:huggingface.co/Qwen/Qwen3.6-3… ModelScope:modelscope.cn/models/Qwen/Qw… API(‘Qwen3.6-Flash’ on Model Studio):Coming soon~ Stay tuned


For local models, which is better in Hermes Agent?