Tweet Disematkan
Scribe
240 posts


Scribe
@LearnWithScribe
AI-powered side hustles to land your first $1K client in 30 days. From manual outreach to automated systems. No code needed
Bergabung Ocak 2021
420 Mengikuti20 Pengikut


Introducing GLM-5.1: The Next Level of Open Source
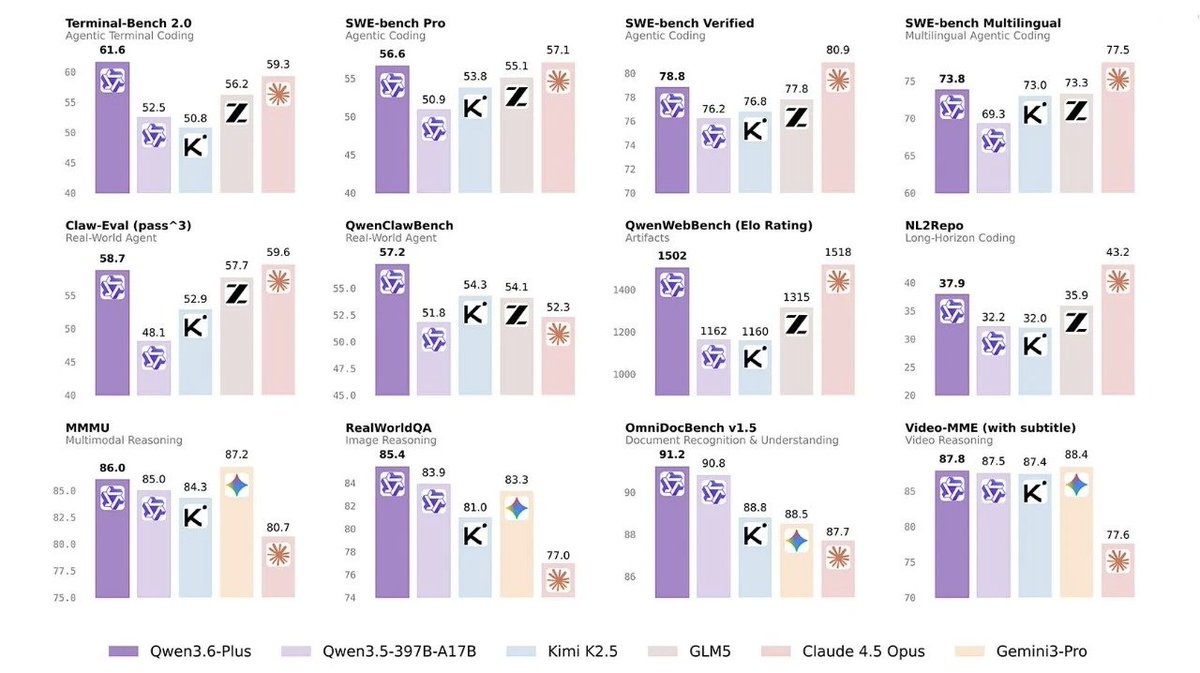
- Top-Tier Performance: #1 in open source and #3 globally across SWE-Bench Pro, Terminal-Bench, and NL2Repo.
- Built for Long-Horizon Tasks: Runs autonomously for 8 hours, refining strategies through thousands of iterations.
Blog: z.ai/blog/glm-5.1
Weights: huggingface.co/zai-org/GLM-5.1
API: docs.z.ai/guides/llm/glm…
Coding Plan: z.ai/subscribe
Coming to chat.z.ai in the next few days.

English


The model is definitely better than minimax 2.7, based on my usage it ranks slightly lower than glm 5.1
Joseph Pidala@jpidala
Qwen 3.6 Plus is an incredible model. Well done to the @Alibaba_Qwen team. It blows GPT-5.4-Codex out of the water for agentic tasks / @openclaw , is 3X faster, and is currently offered free through @OpenRouter. openrouter.ai/qwen/qwen3.6-p…
English
This is crazy stuff, you should try it
Rach@rachpradhan
We're launching CodeDB v0.2.53! 538x faster than ripgrep. 569x faster than rtk. 1,231x faster than grep. 0.065ms code search. Pre-built trigram index. Query once, instant forever. 21 issues closed. 14 PRs merged. 7 contributors. One weekend.
English

Itching to run this bad boy on my Rig, very impressive.
0xSero@0xSero
Holy moly, MiniMax-M2.7 is amazing, watch till the end.
English
@Prince_Canuma @Kurtulmehtap Sad because industry is moving toward more moe than just dense models, but I think , it can useful for increasing the expert size
English

@Kurtulmehtap This model has 5/30 full attention layers, so savings are modest :)
English
Guess they called it "Turbo" for a reason 👀
Model: Gemma-4-26B-A4B-it
Precision: BF16
Device: M3 Max 96GB
English
@DailyDoseOfDS_ We need more metrics about accuracy lost in retrieval step
English

@Prince_Canuma Why peak Mel is slightly the same as baseline , the ram usage should be lower no ?
English
What’s happening, have they started training Mythos?
Crémieux@cremieuxrecueil
So, Anthropic really cut down usage limits, right?
English
@iamsupersocks @Amir_Intel Il arrive à nous donner les points sans lire la date c’est fort
Français

@Amir_Intel tu vas tous les fusiller là mais t'as raison. La plupart regardent même pas les sources, la date, c'est affolant, ça m'agace
Français

"OpenAI vient de publier la première étude exhaustive"
Date en gros dans le rapport : 15/09/2025
Silicon Carne@siliconcarnesf
Suis resté sur le cul... OpenAI vient de publier la première étude exhaustive sur la manière dont 700 millions de personnes utilisent réellement ChatGPT. Les résultats remettent en cause toutes les hypothèses concernant l'adoption de l'IA. On va décortiquer tout çà semaine prochaine dans Silicon Carne... c'est super intéressant 🌶️ Voici tout ce que vous devez savoir en 3 minutes :
Français
@bolaabanjo It can but you have to be way too specific so it’s frustrating
English


Does Google actually hide all the cheaper plan options when setting up a new Google workspace? There are 3 cheaper options and I'm not allowed to see or select any of them.

English



@LearnWithScribe @xiong_hui_chen you're thinking of glm 5 turbo, thats the closed one
English