QingYue
4.1K posts



观察发现@wangray的文章
浏览量都很高
是我单条推文的10倍甚至百倍不止
我的单条推文一般1万就是上限,3万要看机遇!
所以我先转贴一条,蹭蹭流量!
或许这就是从第一条推文注定的风格差异!
我的第一条openclaw推文是短文,Ray的第一条openclaw相关是文章是教程,所以这么久以来我都是写短文,尤以3句半作为自己的追求目标……
考古Ray的第一篇openclaw配置安装文章见链接:
x.com/wangray/status…
Ray Wang@wangray
中文


QingYue me-retweet

@elliotchen100 @YuLin807 你感觉这个像不像你茶馆那位写“记忆树”技能的小伙子相同的思维?
记忆信息可以通过agent评级确定是否重要,不重要的记忆慢慢忽略和遗忘存档。
上下文也可以同样方法,让LLM只思考重要的信息,避免被杂乱的内容干扰😁
中文

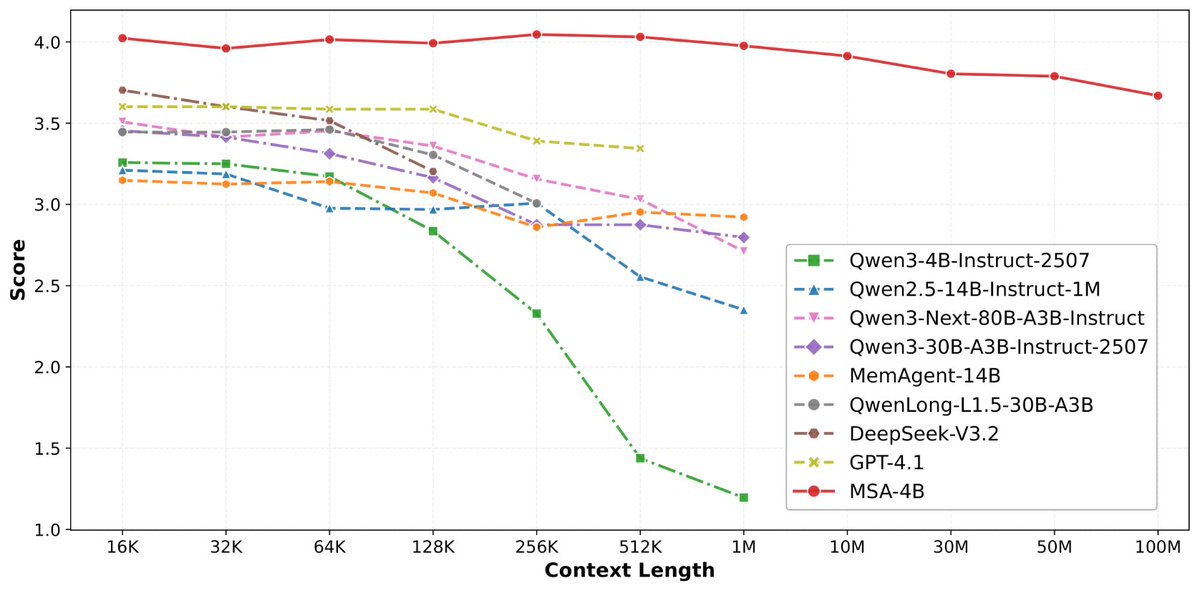
论文来了。名字叫 MSA,Memory Sparse Attention。
一句话说清楚它是什么:
让大模型原生拥有超长记忆。不是外挂检索,不是暴力扩窗口,而是把「记忆」直接长进了注意力机制里,端到端训练。
过去的方案为什么不行?
RAG 的本质是「开卷考试」。模型自己不记东西,全靠现场翻笔记。翻得准不准要看检索质量,翻得快不快要看数据量。一旦信息分散在几十份文档里、需要跨文档推理,就抓瞎了。
线性注意力和 KV 缓存的本质是「压缩记忆」。记是记了,但越压越糊,长了就丢。
MSA 的思路完全不同:
→ 不压缩,不外挂,而是让模型学会「挑重点看」
核心是一种可扩展的稀疏注意力架构,复杂度是线性的。记忆量翻 10 倍,计算成本不会指数爆炸。
→ 模型知道「这段记忆来自哪、什么时候的」
用了一种叫 document-wise RoPE 的位置编码,让模型天然理解文档边界和时间顺序。
→ 碎片化的信息也能串起来推理
Memory Interleaving 机制,让模型能在散落各处的记忆片段之间做多跳推理。不是只找到一条相关记录,而是把线索串成链。
结果呢?
· 从 16K 扩到 1 亿 token,精度衰减不到 9%
· 4B 参数的 MSA 模型,在长上下文 benchmark 上打赢 235B 级别的顶级 RAG 系统
· 2 张 A800 就能跑 1 亿 token 推理。这不是实验室专属,这是创业公司买得起的成本。
说白了,以前的大模型是一个极度聪明但只有金鱼记忆的天才。MSA 想做的事情是,让它真正「记住」。
我们放 github 上了,算法的同学不容易,可以点颗星星支持一下。🌟👀🙏
github.com/EverMind-AI/MSA
艾略特@elliotchen100
稍微剧透一下,@EverMind 这周还会发一篇高质量论文
中文
#Openclaw #Clawdbot
🦞X Fetch 重磅更新
v1.9.0 — Obsidian 导出
现在可以把 X 长文和 arXiv 论文保存为 Obsidian Markdown,图片全部下载到本地。
✨ 新功能:
• X → Obsidian:长文导出 + 本地图片(社区 PR by @AY_0116_ 🙏)
• 论文 → Obsidian:arXiv 论文完整导出,公式、图表、参考文献全保留
已测试:Attention Is All You Need、Chain-of-Thought、ViT、TinyLlama — 全部通过 ✅
零依赖,纯 Python 标准库。
感谢 @andrew0116 的首个社区贡献,直接催生了整个论文导出功能!🎉
_____________
@andrew0116 咱就老实说认识初期那是沉迷于minimax不知天地为何物!!!每天不是修龙虾就是唉声叹气,后来我力荐切换到claude系列,好家伙那功力是一日千里,从唯唯诺诺的小白提问者变身成为重拳出击的贡献者!
楊義兄后来和我说minimax模型,女人用了会流泪😭,男人用了会沉默😏!
不过现在也觉着opus挺傻逼的,有没有啥方案切换到爽用Gemini3.1pro 谷子天天限流……
QingYue@YuLin807
#openclaw #clawdbot 🔬 x-tweet-fetcher v1.8.0 — 学术论文模式 给一篇论文,自动完成两件事: 1️⃣ 找到所有作者的 X/Twitter 账号 2️⃣ 推荐相关论文(引用/被引/同作者/相关领域) 四种入口: · 推文链接 → 提取论文 · GitHub 仓库 → 解析 BibTeX · ArXiv ID → 元数据 · 论文标题 → OpenAlex 检索 基于 OpenAlex(2.5亿+论文),零 API Key,零注册,开箱即用。 ⚠️ VPS 公网 IP 可能被搜索引擎限流,配合 ask-search 使用效果更佳 👇 x.com/YuLin807/statu… Github 链接见下:@li9292
中文






终于没有靠女朋友靠自己
以两篇 ask search skill 合计斩获11w +浏览量🎉
这下男儿当自强了!
考古链接:
x.com/YuLin807/statu…
QingYue@YuLin807
#openclaw 面向Agent的最强搜索引擎 ask - search 现已开源 内置Google + Brave + DuckDuckGo + Wikipedia 等 70+ 源 知乎Reddit抓全文不在话下 全面替代Brave API 本地党龙虾的不二之选!
中文
QingYue me-retweet

Claude Code官方推出了Channel功能,使用plugin配置后在telegram和discord上面远程和你本地设备打开的Claude Code对话。
对于不希望研究Openclaw的用户来说会容易很多,也可以直接使用Claude的订阅账户。配置了一下流程很容易,方案如下,也可以看到测试视频。
如何安装:
指南 - github.com/anthropics/cla…
1. 下载bun curl
curl -fsSL bun.sh/install | bash
2. 安装Claude Code的Telegram插件:
打开claude code后直接输入
/plugin install telegram@claude-plugins-official
/reload-plugins
3. 在telegram的bot创建功能上按照以下流程创建机器人账号:
打开 t.me/botfather
输入 /newbot 后,设置bot的名字和ID
随后就可以拿到接入API
4. 把Telegram Bot的API提供给Claude Code
/telegram:configure 这里复制你的API
5. 退出当前的session,打开Channel模式
Claude Code会让你直接测试,但是你必须要先退出
输入exit
然后
claude --channels plugin:telegram@claude-plugins-official
6. 这个时候和你的telegram bot发一个消息,就会收到pairing code,随后在claude中输入如下
/telegram:access pair
如果你这一步收不到消息,很可能是bun安装失败,或者你没有重启claude code
7. 设置为白名单通信模式
/telegram:access policy allowlist
就可以用了 中文
