Tweet Disematkan

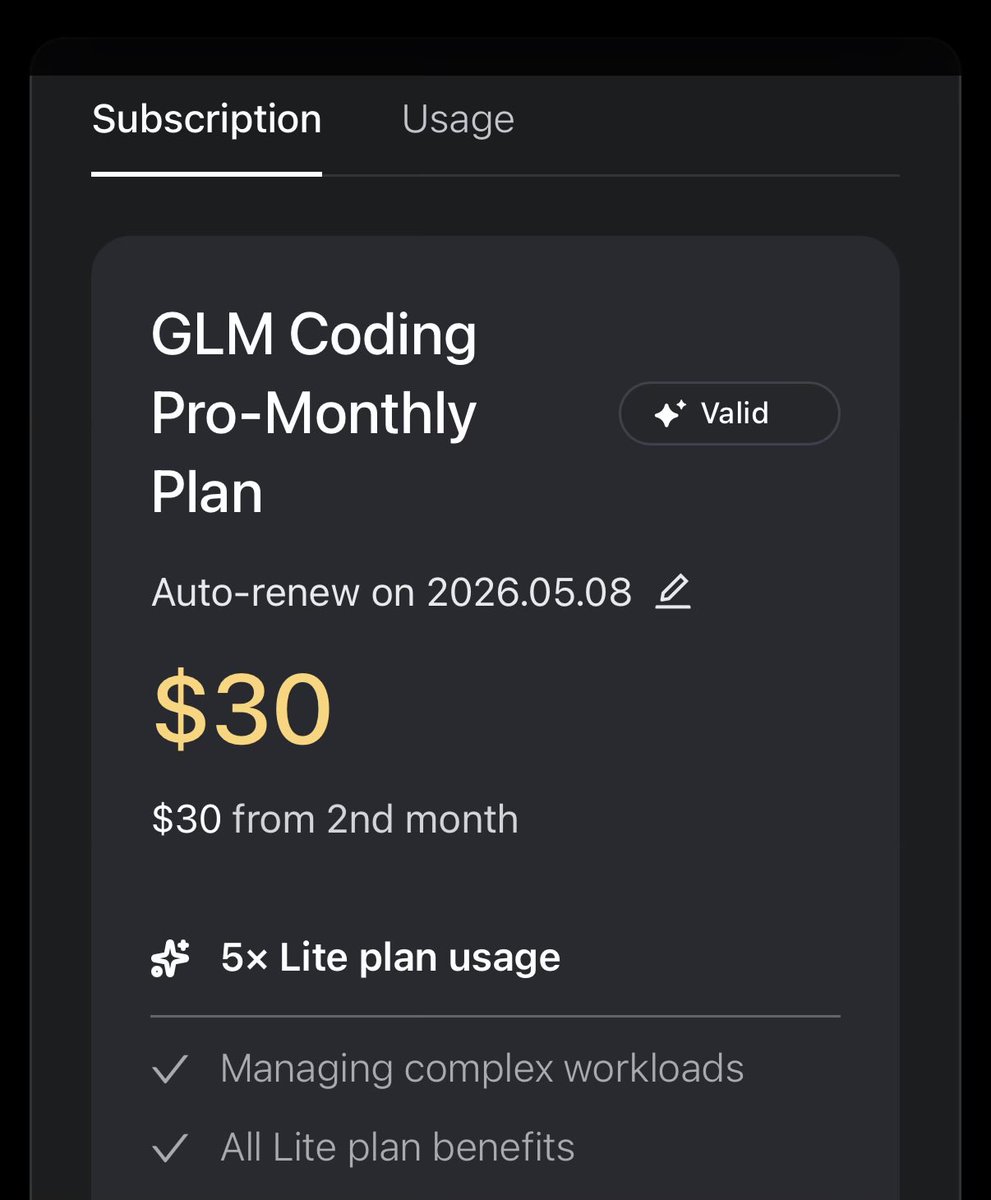
⭐️These plans are still the best. Buy them now while they’re still this cheap.
They will rise like GLM plans!!!
Today I coded for 3 hours, constant refactoring, code reviews etc. Just 2% weekly usage. 2%! 45000 requests per week.
The quality is really good, at least like Sonnet 4.5. Very fast.
Also one of 3 best models for OpenClaw or Hermes.
Mark my words. This is the last time you’ll see prices this low.
Mateusz Mirkowski@llmdevguy
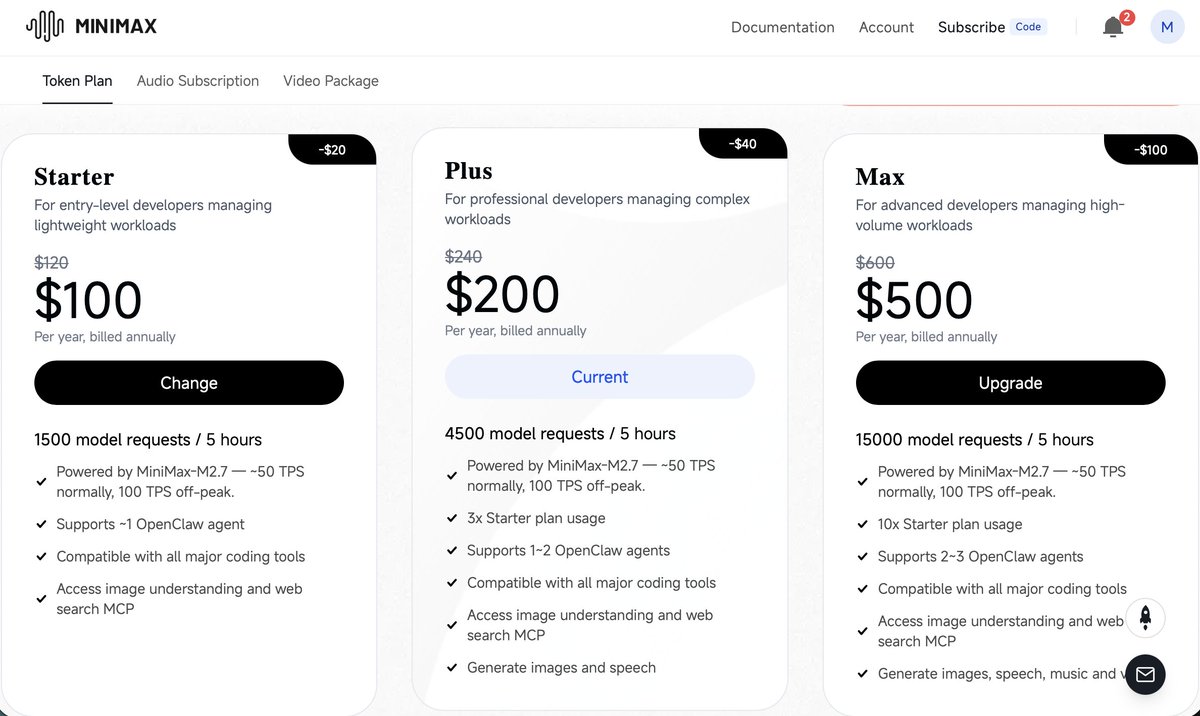
OK that was fast.. GLM 5.1 was the best model in terms of quality and price. For just few days.🙈 For this price it's still good option, but instead of 72$ I would rather pay 100$ for codex. More reliable models. For GLM go for OpenCode GO for 5 usd. 4400 requests per month is not bad to play with it. It's slow, but works. If you like it go with lite. King of value stays with MiniMax 2.7.
English