固定されたツイート

#ICML2024
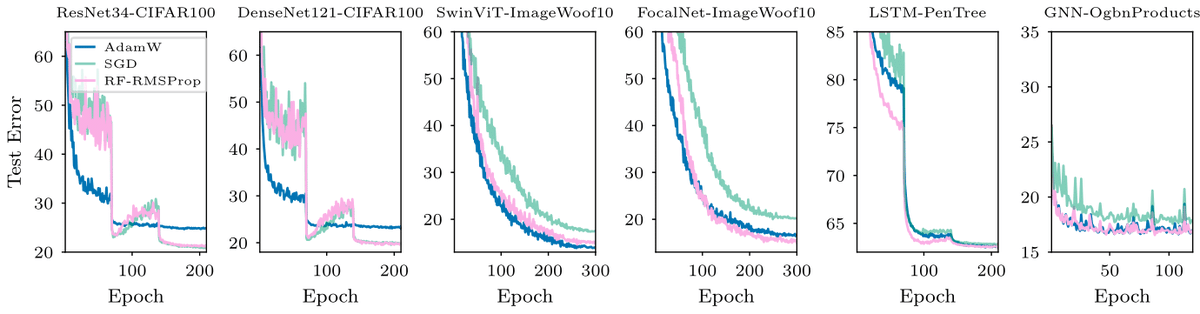
Can We Remove the Square-Root in Adaptive Methods?
arxiv.org/abs/2402.03496
Root-free (RF) methods are better on CNNs and competitive on Transformers compared to root-based methods (AdamW)
Removing the root makes matrix methods faster: Root-free Shampoo in BFloat16 /1
English