固定されたツイート

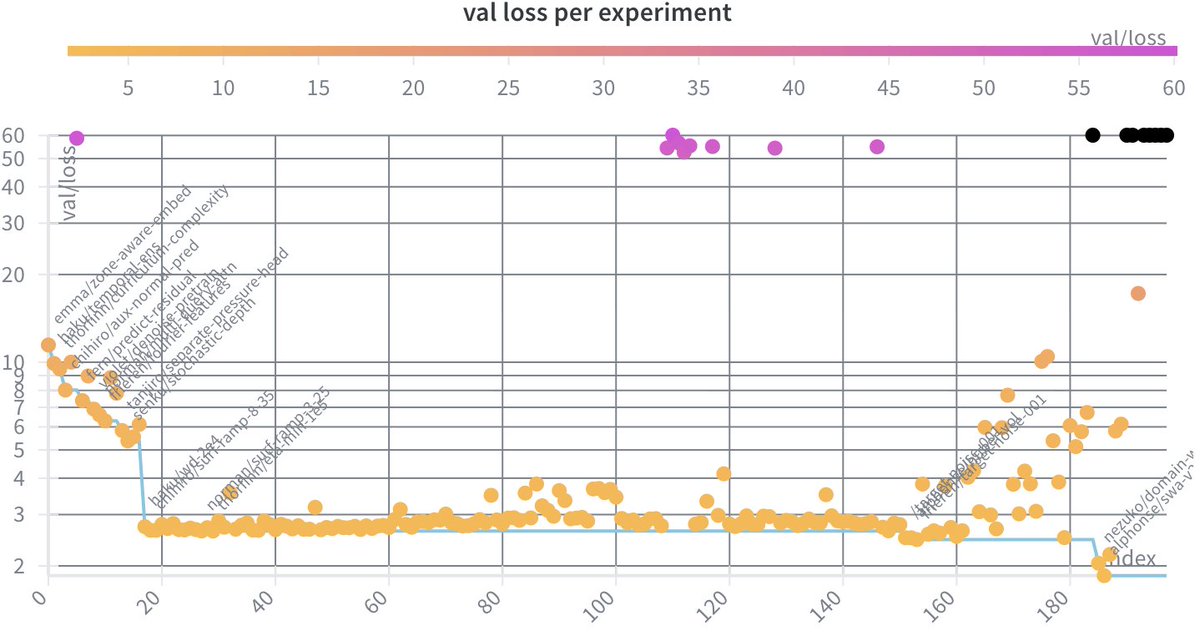
Here's an animation of a @PyTorch DataLoader.
It turns your dataset into a shuffled, batched tensors iterator.
(This is my first animation using @manim_community, the community fork of @3blue1brown's manim)
Here's a little summary of the different parts for those curious:
1/5
English