nullHawk
62 posts


nullHawk
@null_hawk
i make GPUs go brrr... | building voice @rumik_ai
参加日 Ağustos 2023
124 フォロー中40 フォロワー





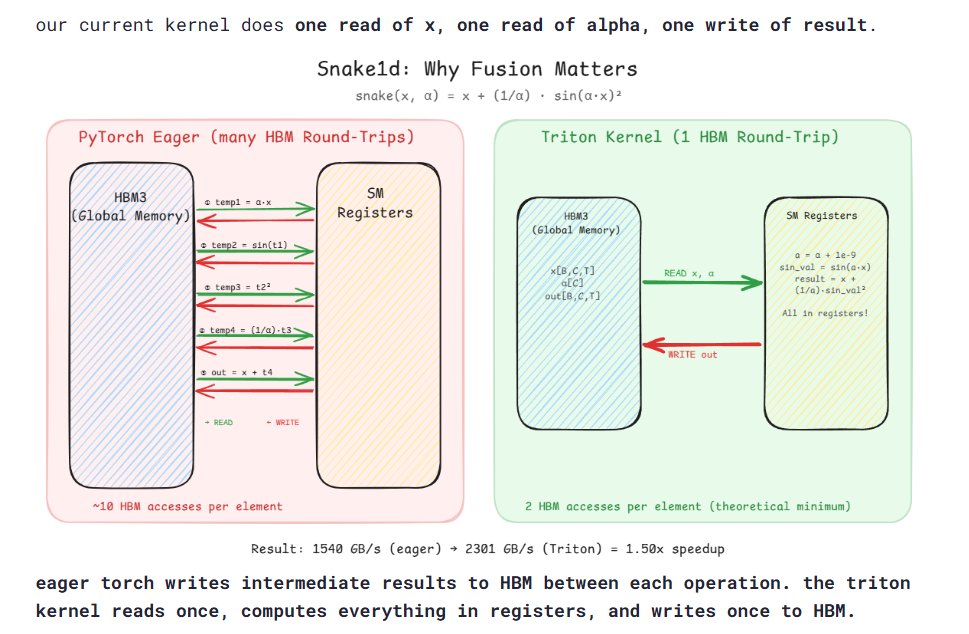
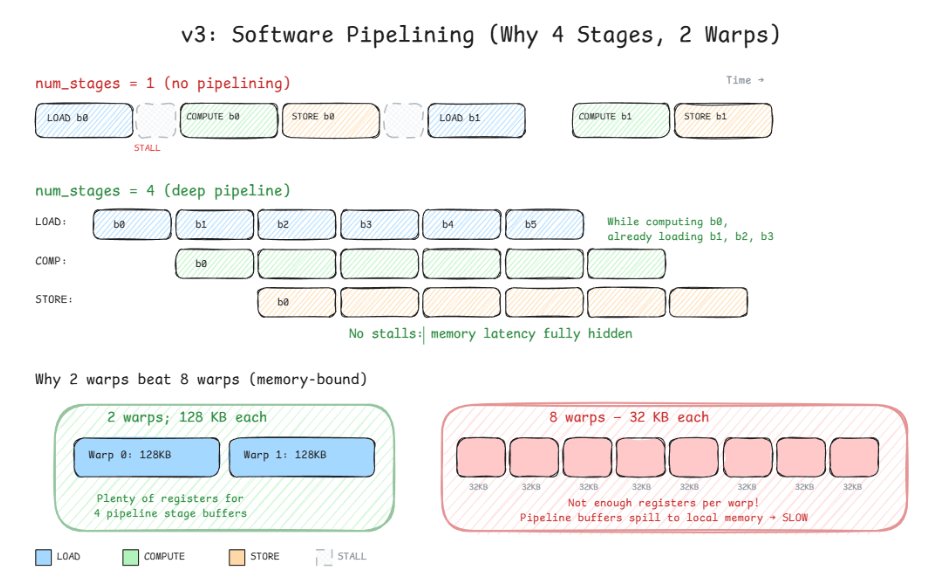
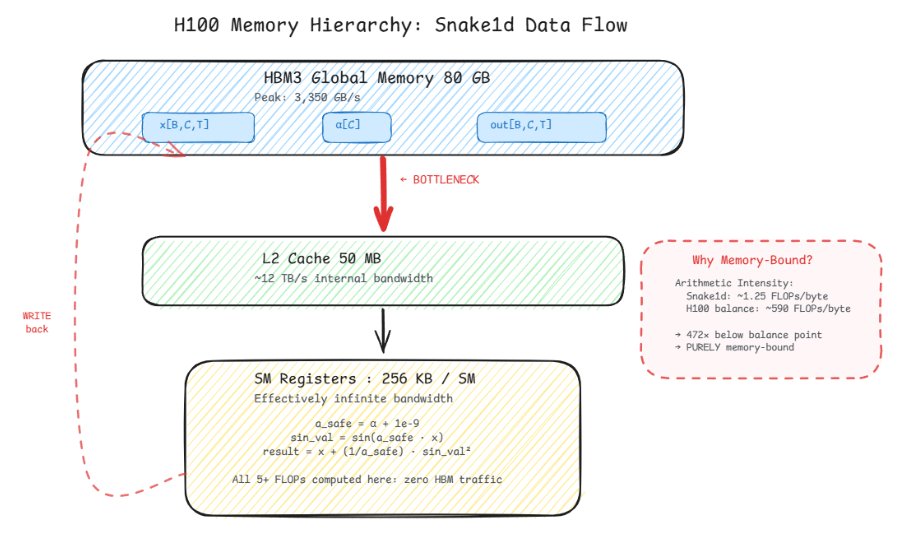
Its been approx 20+ hrs and finally reduced my GRPO runtime from ~12.8 hrs to ~1.5 hrs. used vLLM inference on one GPU and DDP on the other 3, applied pretty much everything I had.
using 3 GPUs for DDP, hosted vLLM inference on one GPU, with 8 samples generating parallely, along with codec tokens, grad_accum=4, data sharding across ranks, micro-batching within the loss function, TF32 tensor cores, BF16 autocast for forward pass, Flash SDP + mem-efficient SDP, cuDNN benchmark mode, BF16 reduced precision reduction... works well for Hopper architecture.
also turned on gradient checkpointing, manual gradient all-reduce (instead of full DDP wrapping), plus a file-based vLLM watcher that restarts the inference server with fresh merged weights at every optimizer step from a clean process tree (to avoid NCCL conflicts with torchrun), with retry logic on generation calls during server.
biggest debugging rabbit holes:
vLLM V1 silently ignoring stop_token_ids (had to force V0 with VLLM_USE_V1=0), and merge_and_unload() with tie_word_embeddings=True dropping the trained lm_head during save, model generates infinite codec tokens and never stops. fix: untie before merge so both embed_tokens and lm_head are saved separately.
GRPO on TTS is a different beast from text!

English
@cneuralnetwork @smallest_AI i don't know why it didn't worked when i tried it... maybe its upset with me :(
English

okay so lightning v3.1 from @smallest_AI gets hard hindi tongue twisters right
Sudarshan Kamath@kamath_sutra
English


@SherryYanJiang @amilabs @theworldlabs @gen_intuition @moonlake @physical_int @bifrost_ai @reactorworld @odysseyml @NianticSpatial @Figure_robot @SkildAI @DecartAI @runwayml @wayve_ai maybe add @rumik_ai in that list too 👀
English

here are some cool companies doing stuff in world models and physical ai - anyone im missing??
@amilabs
@theworldlabs
@gen_intuition
@moonlake
@physical_int
@bifrost_ai
@reactorworld
@odysseyml
@NianticSpatial
@Figure_robot
@SkildAI
@DecartAI
@runwayml
@wayve_ai
@agilityrobotics
English


Why can't teams with big resources achieve good audio quality? The model is nice but the audio quality is low :/
Xiaomi MiMo@XiaomiMiMo
MiMo TTS doesn't just talk — it sounds human. Sobbing. A sudden laugh. A cough. Heavy breathing. A nervous sigh. All woven naturally into speech. 🎧 2/n
English
nullHawk がリツイート


This is either the biggest fumble or the biggest bag
English


nullHawk がリツイート

New blog!!
From Air Pressure to Speech: Exploring classical TTS pipeline
i walk you through how tts works from capturing sound froom microphone to getting wav files
hope you guys enjoy ; )
@VioSIlverP/rkOZITb9Wx?utm_source=profile-share" target="_blank" rel="nofollow noopener">hackmd.io/@VioSIlverP/rk…
English


nullHawk がリツイート