
gangz
50 posts

𝗢𝗻𝗲 𝗺𝗲𝗺𝗼𝗿𝘆 𝗰𝗮𝗻’𝘁 𝗿𝘂𝗹𝗲 𝘁𝗵𝗲𝗺 𝗮𝗹𝗹.
We present 𝗟𝗼𝗚𝗲𝗥, a new 𝗵𝘆𝗯𝗿𝗶𝗱 𝗺𝗲𝗺𝗼𝗿𝘆 architecture for long-context geometric reconstruction.
LoGeR enables stable reconstruction over up to 𝟭𝟬𝗸 𝗳𝗿𝗮𝗺𝗲𝘀 / 𝗸𝗶𝗹𝗼𝗺𝗲𝘁𝗲𝗿 𝘀𝗰𝗮𝗹𝗲, with 𝗹𝗶𝗻𝗲𝗮𝗿-𝘁𝗶𝗺𝗲 𝘀𝗰𝗮𝗹𝗶𝗻𝗴 in sequence length, 𝗳𝘂𝗹𝗹𝘆 𝗳𝗲𝗲𝗱𝗳𝗼𝗿𝘄𝗮𝗿𝗱 inference, and 𝗻𝗼 𝗽𝗼𝘀𝘁-𝗼𝗽𝘁𝗶𝗺𝗶𝘇𝗮𝘁𝗶𝗼𝗻.
Yet it matches or surpasses strong optimization-based pipelines. (1/5)
@GoogleDeepMind @Berkeley_AI
English

imagine the amount of training data we could get from this library!
Curiosity@CuriosityonX
The ancient library of Tibet. Only 5% has been translated. x.com/i/status/15936…
English
na man, that’s not what it means😭 this mf just destroyed one of the happiest memories of my childhood😭 why tf does it sound soo honourable and gives of king vibes if it’s just that NAAAAA!!
Don Keith@RealDonKeith
😂Hilarious! What the words to The Lion King song actually mean…
English
@TheAhmadOsman FR, the moment i started just doing the work with no worries regarding results that’s when actually results happened, it’s soo weird like u just gotta enjoy the work and everything else just falls in place
English

i learned this the hard way:
chasing outcomes poisons them
when i wanted things too badly
jobs, approval, momentum
nothing landed
the moment i focused on the work
and stopped needing the result
doors opened without force
same pattern everywhere
real leverage comes from
conviction before validation
doing it all alone & without guarantees
embracing variance
even if it means burning the map
and starting over
most people cling to their current peak
i’m willing to descend
because that’s how you reach a higher one
English
y’all ever wondered how people can do stuff for soo long stay locked in and do stuff for years when we can’t even focus for an hour? the secret sauce is they enjoy what they’re doing. if u ain’t enjoying what ur doing, what’s the point of locking in? well then u may ask what’s the point of anything? well my dear that’s the whole point. as anyway it’s pointless why not enjoy doing it?
think about it.
English

best shit ngl. engineer the solution then ask the model to build it. we are shifting from pure coding skills to architecture as these models get insane. pick up a system design book right now but dont stop coding or youll be cooked when the model hallucinates LMAO
Sahil@sahill_og
POV: How it feels when AI can't solve your problem and you switch to documentation
English
@TheAhmadOsman how do i convince my dad lol? i’ve been using open code and it’s amazing
English
@aaryan_kakad dont stop kid, fun’s just begun!! get messy f*ck around with stuff, that’s how u learn. BTW i maintain a whole seperate book for research papers to jot down my understanding and dig deeper. can’t wait to see what’s ur next proj gonna be :)
English

I was 12 when I wrote my first Python script.
Not because someone forced me - because I loved building things.
By 13, I was already obsessed with stocks and crypto.
I loved predicting what would happen next. I loved the feeling of being right about the future.
But at 16, something else caught my attention: the online business world.
SMMA, dropshipping, all of it. I loved the concept of earning a lot of money by doing business.
I wanted the money. I wanted the leverage.
So I tried it four times - and failed four times.
Every single one crashed.
But I learned how businesses actually work from failing that much.
I learned what actually matters.
When ChatGPT dropped in 2022, I didn't build it.
I was just another user, asking it to fix my code, wondering how the hell this thing worked.
For three years, I wondered.
Then in June 2025, I stopped wondering and started building.
I finally decided to learn ML from scratch.
I haven't told anyone in real life what I'm doing.
Just Twitter. Some friends and family know, and they appreciated it, but that's it.
This has been a solo mission.
Every morning at 5 AM, I wake up and work until 9 or 10.
One session. Four to five hours of intense, deep ML work.
That's it.
Then I go to the gym.
I do this every day, missing it as little as possible.
I sacrificed my entire social life for this.
It's just me, the GYM, and ML.
I believe in extremes. This isn't for everyone, but it's what I chose.
I started with agentic AI. LangChain.
I built cool stuff immediately because I needed to see things move.
Then I moved to core ML, brushed over some linear algebra and statistics - not deep, just overviews so I wouldn't feel stupid.
I took Andrew Ng's AI for Everyone to get the basics down.
Then I hit deep learning. I started CS229, but @jsuarez told me to switch.
He said CS229 was too much math, that I'd quit if I stayed there.
He pointed me to CS231n instead.
He was right. CS231n was perfect - I finished every lecture, every assignment.
I finally understood how things actually work and how to build cool stuff around it.
When I get curious about a topic now, I watch @karpathy's videos.
But here's my real secret:
I print research papers. PHYSICALLY.
The ones that make me curious. I read them, understand them, explain them in my own words, and write the explanations directly on the paper itself.
That's how I learn now.
I have the fundamentals, the intermediate understanding, and now I'm doing the reps and spending enough time around it to become an expert.
Nothing felt hard because I was obsessed.
I revisited backpropagation multiple times because it's the most important one, but I never wanted to quit.
Not once. When you're actually obsessed with ML and building, you don't need discipline. You need to be forced to stop.
My first real build was fine-tuning ResNet18 on 5,500 images to rate faces.
When it worked, that was the moment I knew I could actually do this.
After that, I built a Siamese network that finds what celebrity you look like. And then MedVLM - that's the one I'm proud of.
It's a hybrid Vision Transformer that reads chest X-rays like a pro.
I trained it on just 3,400 X-rays - that's tiny - and it predicts report captions with high accuracy.
I built it on a free tier Kaggle GPU. No budget. No lab. Just me and the code.
All my projects are on my X. I'm not showing them here because they're already there.
Here's what I know:
99% of CS grads finish their degrees without knowing how to actually build something.
They know theory.
I know how to train a model on 3,400 images and make it generate medical reports.
I have building experience. That's the edge.
I skipped the conventional math-first approach because you'll definitely quit if you start with a lot of math.
You don't need a PhD to build cool stuff or do research. @gabriel1 and a lot of others already proved that.
Now here's the thing: I'm not doing this to become a machine learning engineer.
I'm not trying to get hired at Google to work on someone's recommendation algorithm.
My goal is to apply ML and build huge companies that solve real problems at scale.
I want to build my legacy that way - not by writing code for someone else's empire, but by using this technology to build my own.
I failed at business four times at 16 because I didn't have the leverage.
Now I have the leverage.
I have the skill to build things that actually work.
Now, its time to use it.
P.S. I know this sounds like too much for a 19 year old kid, but its my true story. And I recently turned 19 btw on 28th Jan.
English
@neural_avb aiming for blt-level adaptivity but within a BPE framework by using IGOT and MorphBPE constraints. basically trying to see if LiteToken pruning can get me to SOTA without the GPU tax. a bit of both worlds LMAO
English

@quantumcuddle Very cool! By tokenization models, do you mean dynamic/adaptive tokenization? Something like Byte Latent Transformers? Or pure (non-parametric) tokenization?
English
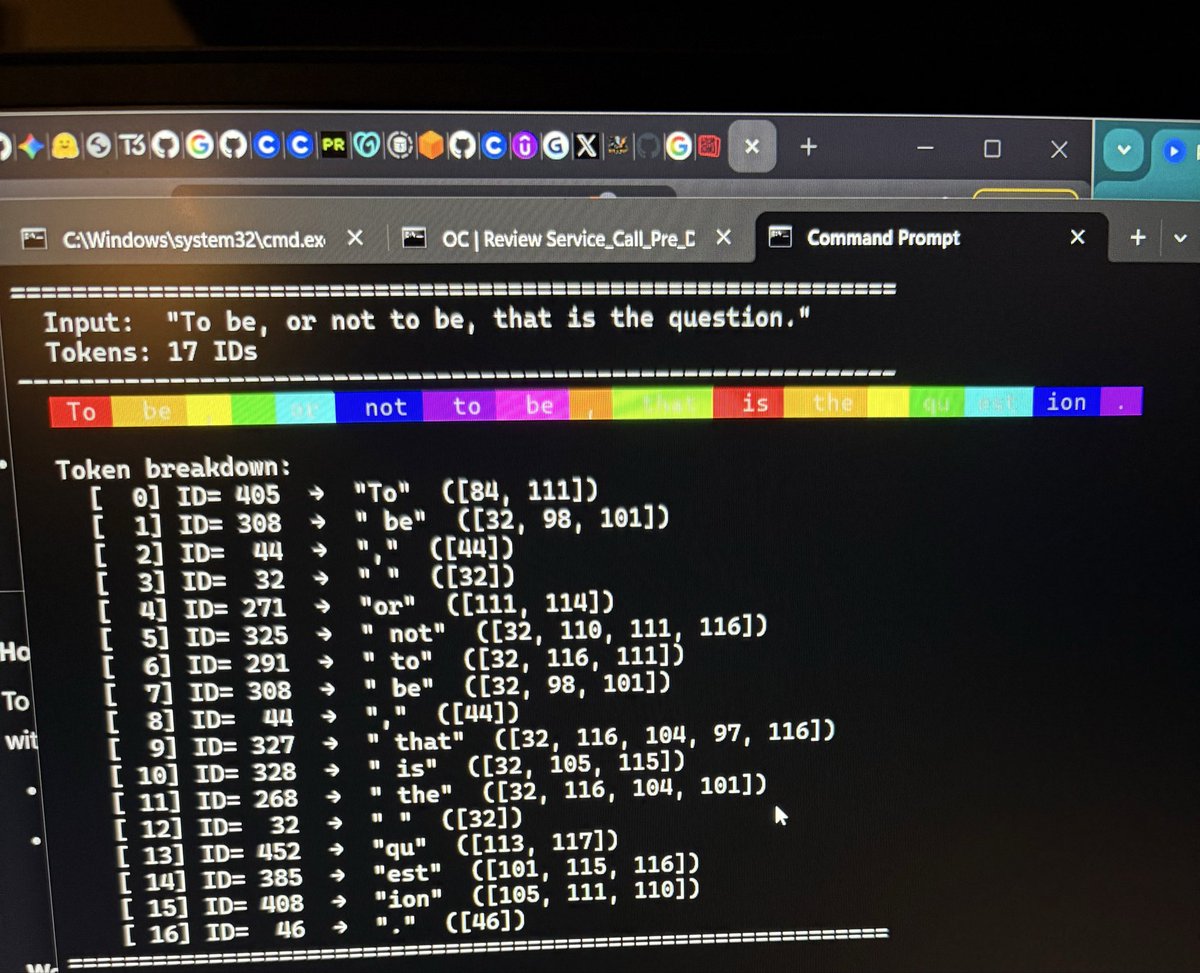
i can already see myself changing the entire architecture of the application lmao, can’t wait to get my hands dirty and test the shit out of this model
𝗿𝗮𝗺𝗮𝗸𝗿𝘂𝘀𝗵𝗻𝗮— 𝗲/𝗮𝗰𝗰@techwith_ram
𝗔 𝗧𝗶𝗺𝗲 𝗦𝗲𝗿𝗶𝗲𝘀 𝗙𝗼𝘂𝗻𝗱𝗮𝘁𝗶𝗼𝗻 𝗠𝗼𝗱𝗲𝗹 𝗕𝘆 𝗚𝗼𝗼𝗴𝗹𝗲 This has been pre-trained on a time series corpus of 100 billion data points, & shows impressive performance on various benchmarks from diverse domains. 𝗧𝗶𝗺𝗲𝘀𝗙𝗠 𝗚𝗶𝘁𝗵𝘂𝗯 𝗽𝗮𝗴𝗲: github.com/google-researc… 𝗟𝗲𝗮𝗿𝗻 𝗠𝗟 𝗮𝗻𝗱 𝗙𝗼𝗿𝗲𝗰𝗮𝘀𝘁𝗶𝗻𝗴: leanpub.com/pycaretbook/
English
@ihailmyindia FR we are so used to criticising ourselves and comparing us to others we forgot how to atleast appreciate the people who are putting in the work to get us on the global stage and make us proud!! phenomenal work @SarvamAI and team, u made us proud
English

India literally had its own DeepSeek moment via Sarvam, yet it’s not even celebrated 1% the way China’s DeepSeek was celebrated by us, especially when Indians used that achievement to criticise India.
I seriously don't get it.

English