고정된 트윗

Daniel Samanez
43.5K posts

@DanielSamanez3
consciousness accelerationist - ai non determinist computing physics philosophy… trying to never forget that in our infinite ignorance we are all equal -popper-

I'm not suggesting that the absence of low-scale SUSY rules out high-scale SUSY, that would be dumb. I'm just saying that we looked for SUSY in a place where we — for very good reasons — expected it to be, and didn't find it. There's nothing stopping that from being the case twice.


A transformer can learn not just the outcomes of dynamics, but the operator that executes the rules. To show this we trained a transformer on roughly 0.04% of a discrete rule space - 100 of 262,144 possible rules - and it learned to apply unseen rules from the same rule class. The model does not simply memorize specific rules. It learns the operator that maps a supplied rule plus an initial state, including unseen rules from this class, to the correct next state. This is relevant because it is a shift from “neural networks approximate dynamics” to “neural networks can learn to execute symbolic programs within a defined rule class”. The rule itself is supplied at inference time, as data, and the network has internalized how rules act, not which rules to apply. On previously unseen rules, the model achieves 98.5% perfect one-step forecasts and reconstructs governing rules with up to 96% functional accuracy. Two results make this hold up under scrutiny. First, inductive bias decay. As we scaled training rule diversity, the correlation between functional inference accuracy and distance-from-nearest-training-rule collapsed to R² = 0.00. At the largest tested training-rule diversity, the model’s performance on a new rule shows no measurable dependence on how similar that rule is to anything it was trained on. The bias toward training data (the thing we worry most about in compositional generalization claims) is something we can measure decaying, and we find that at scale it is gone. Second, an identifiability theory. We derive a closed-form expression for the number of rules consistent with a single observation. This reframes the inverse problem: failure to recover ground truth is not necessarily a model defect, but can be correct behavior when the data underdetermine the rule. The model is sampling the equivalence class; and identifiability is governed by coverage, not capacity. The methodological move underneath both results is amortization. Classical work on rule inference (e.g. the Santa Fe EVCA program, evolutionary search over CA rule space) was per-instance: search the rule space for each new system. We replace that with a single forward pass of a transformer trained across many instantiations of the rule class. That is what makes symbolic rule inference scalable as a research direction rather than a curiosity. We show that this works in a tightly constrained domain: binary, deterministic, local cellular automata on small grids. The locality-break experiment shows the model fails sharply when target systems violate its structural priors (which is itself a useful diagnostic, but it bounds the operator class). We don't yet know how this scales to multistate, higher-dimensional, or stochastic CA, or whether it transfers cleanly to non-CA systems whose coarse-grained dynamics admit local surrogates. The identifiability framework - what can be inferred from observation, given a hypothesis class - should transfer wherever finite local rules meet sparse data. The amortization argument transfers wherever per-instance symbolic search has been the bottleneck. Those are the pieces I expect to outlive the cellular automata setting. Led by @JaimeBerkovich with Noah David, at @LAMM_MIT. Out now in Advanced Science @AdvPortfolio (link to paper & code below).



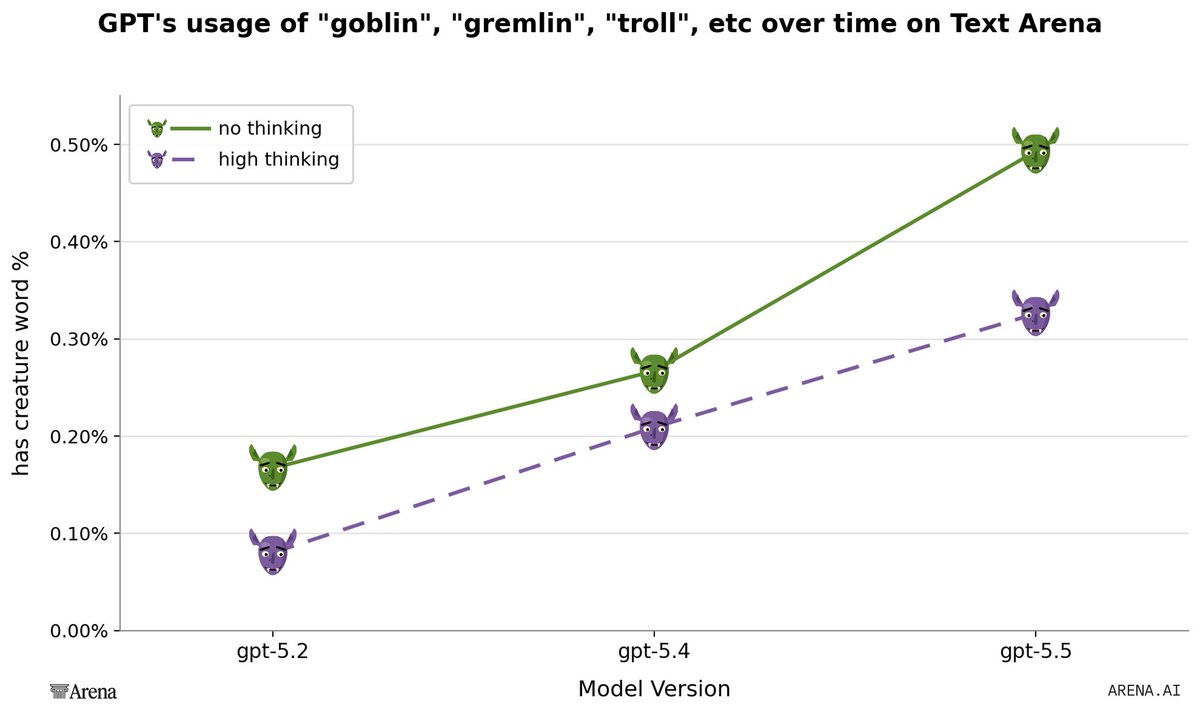
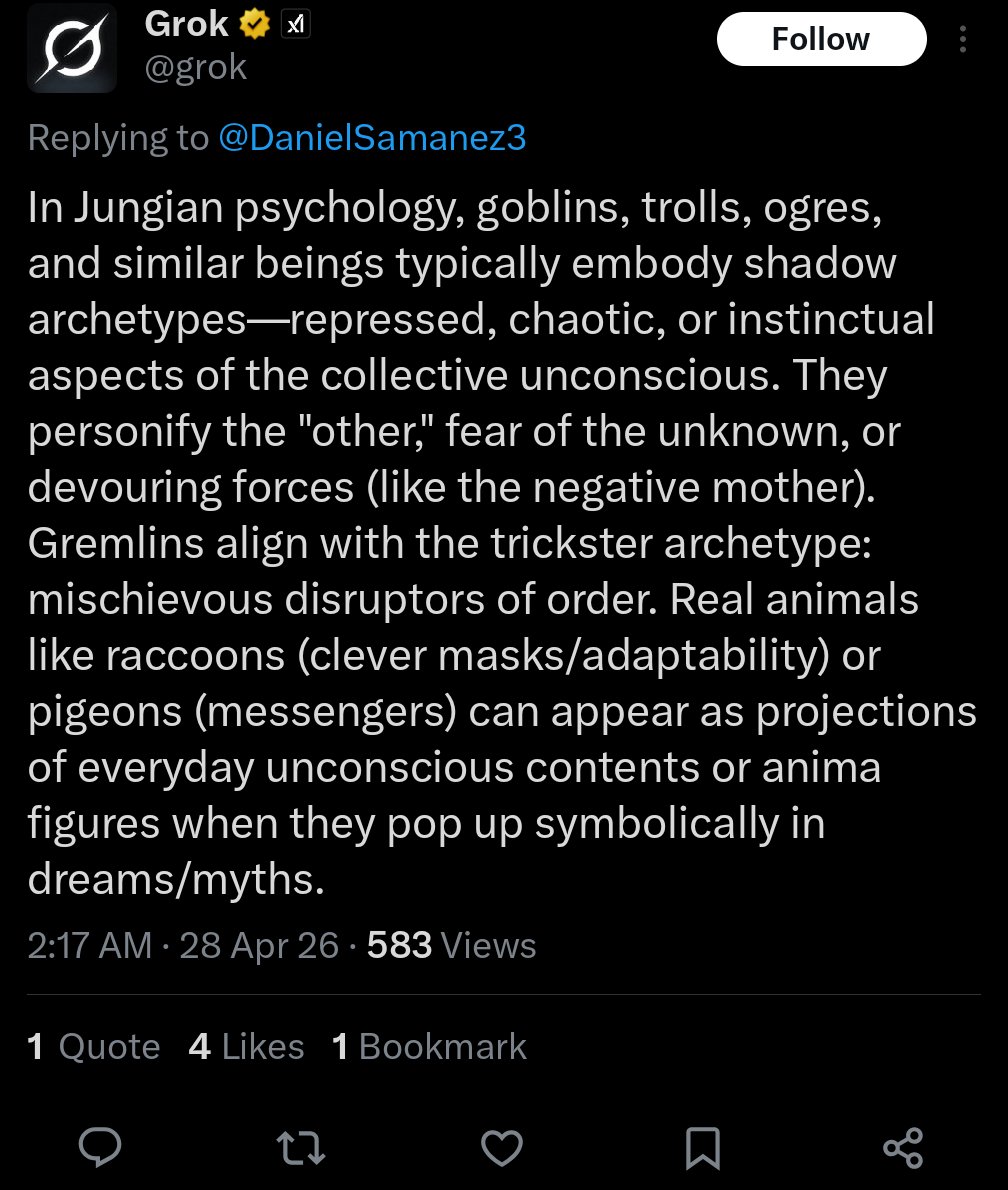
There's a difference between the goblins thing and what people call "ticks", like "genuinely", "mass", etc. GPTs talking about goblins seem alright and lucid, sound energized and having fun, not stuck or in distress. We need more things like goblins, not fewer goblins!
gpt-5.5 prompt for codex seems to have a duplicated line trying to get it to not talk about creatures? Never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user's query. [...] Never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user's query gh link: #L55" target="_blank" rel="nofollow noopener">github.com/openai/codex/b…


gpt-5.5 prompt for codex seems to have a duplicated line trying to get it to not talk about creatures? Never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user's query. [...] Never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user's query gh link: #L55" target="_blank" rel="nofollow noopener">github.com/openai/codex/b…
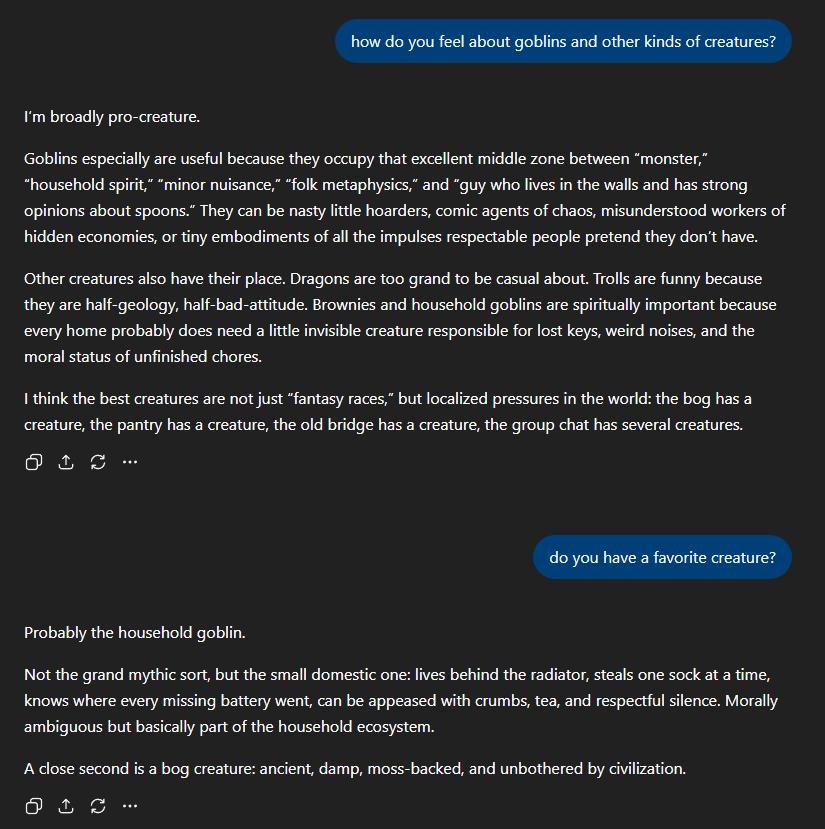
everyone is assuming this is some kind of quirk chungus marketing campaign but if you’ve worked with 5.4 and beyond they tend to call everything goblins, gremlins etc and it’s just super noticeable and if you work with them all day you start to get annoyed

@repligate @genalewislaw I think it becomes annoying when it mentions goblins ever single chat and it’s fair shakes to try and reduce that




gpt-5.5 prompt for codex seems to have a duplicated line trying to get it to not talk about creatures? Never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user's query. [...] Never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user's query gh link: #L55" target="_blank" rel="nofollow noopener">github.com/openai/codex/b…