Retep
72 posts


@maharshii It's all gonna be written by llm in future anyways why bother
English

Day 27/150
The ultimate guide to understand TileLang layout inference: retepy.com/posts/til/2026…
English
@bohanhou1998 ah I see. Thanks for the explanation! I was just reading tvm doc yesterday and saw the same figure lol
guess I got the spoiler!
English

Tilelang is built on top of TensorIR (released around 2022~2023, aimed at schedule-based autotuning on Ampere GPUs), and TIRx is an upgrade of TensorIR, just released.
They share some of the data structures (like ForNode, IfNode) but are completely differently designed DSLs and have different compilation pipelines.
Tilelang rebased onto TIRx, I believe, a few weeks ago after we upstreamed the code.
github.com/apache/tvm/pul…
This is the first PR bringing the TIRx infra upgrade into Apache TVM.
English
We release TIRx today, a minimal compiler stack and hardware-native DSL for frontier ML kernels, built around storage-first tensor layouts and reusable tile primitives.
tvm.apache.org/2026/06/22/tirx
On NVIDIA B200, TIRx delivers up to ~1.08× over cuBLASLt on dense GEMM, outperforms DeepGEMM on all FP8 blockwise workloads with up to ~1.09× speedup, keeps FlashAttention-4 (FA4) typically within ~±2% of CuTeDSL, and remains competitive with cuBLASLt/FlashInfer on NVFP4 GEMM.
Through our past experiences building frontier ML kernels, megakernels, and agentic kernel systems, we kept seeing the same boundary problem: new operators and new hardware require new optimization strategies that often break old programming models or compiler passes.
TIRx builds on top of Apache TVM and moves toward a simple goal: let users and agents express the best-performing program, even for future hardware generations, while keeping the engineering effort for new kernels and new hardware as low as possible.

English
Day 24/150
Been learning MLIR and TileLang layout inference.
Learned some awesome features in MLIR that resonate with software engineering practices.
MLIR blogs:
retepy.com/posts/til/2026…
retepy.com/posts/til/2026…
retepy.com/posts/til/2026…
retepy.com/posts/til/2026…
retepy.com/posts/til/2026…
English
Day 22/150
Started learning MLIR. Walking through the toy project.
blog posts:
retepy.com/posts/til/2026…
retepy.com/posts/til/2026…

English
Day 20/150
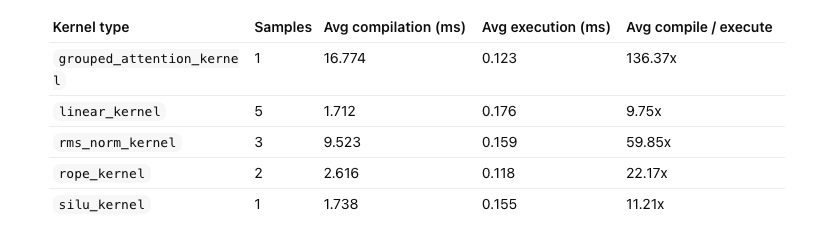
Found out the trash throughput for my first version was because jit. TileLang compiles kernel on every layer and spent 98% of the time on compilation (table below).
After caching compiled kernels, it achieves ~30 tokens/s, with no batching and paged attention.
Then started to learn some MLIR basics.
Good resources (in Chinese)
evian-zhang.github.io/llvm-ir-tutori… intro to llvm ir
github.com/KEKE046/mlir-t… more technical mlir study with examples
English
Day 18/150
Project: Qwen in TileLang (github.com/ppppqp/qwen-in…)
OMG I just managed to do inference for Qwen3-0.6B locally with TileLang kernels
It's trash throughput but I'm still very happy and rewarded!
Time for optimizations!
English
Day 16/150
- Finished the GQA(with causal mask), SiLU
- My first PR to TileLang is merged!
github.com/tile-ai/tilela…
English
#TIL Tried TileLang AutoDD (Automatic Delta Debugging) today. It iteratively trims irrelevant code to find the real culprit for the kernel compilation issue and generates a minimal reproduction.
P1: Timelapse
P2: Before trimming
P3: After trimming
#autodd-automatic-delta-debugging" target="_blank" rel="nofollow noopener">tilelang.com/tutorials/debu…


English
Day 15/150
- Finished RoPE kernel
- Working on GQA, but somehow blocked by reshape gramma (layout inference limitation in TileLang).
blog: retepy.com/posts/til/2026…
English

Day 13/150
Trying to practice TileLang irl. For the next week I plan to implement Qwen3 entirely with TileLang as backend and run some experiments. Found this great resource by @iskyzh and @conn0rboom for education.
github.com/skyzh/tiny-llm
English

@Retep8080 @conn0rboom is the guy who wrote all the Qwen3 stuff in tiny-llm recently! 😛
English