Bohan Hou@bohanhou1998
We release TIRx today, a minimal compiler stack and hardware-native DSL for frontier ML kernels, built around storage-first tensor layouts and reusable tile primitives.
tvm.apache.org/2026/06/22/tirx
On NVIDIA B200, TIRx delivers up to ~1.08× over cuBLASLt on dense GEMM, outperforms DeepGEMM on all FP8 blockwise workloads with up to ~1.09× speedup, keeps FlashAttention-4 (FA4) typically within ~±2% of CuTeDSL, and remains competitive with cuBLASLt/FlashInfer on NVFP4 GEMM.
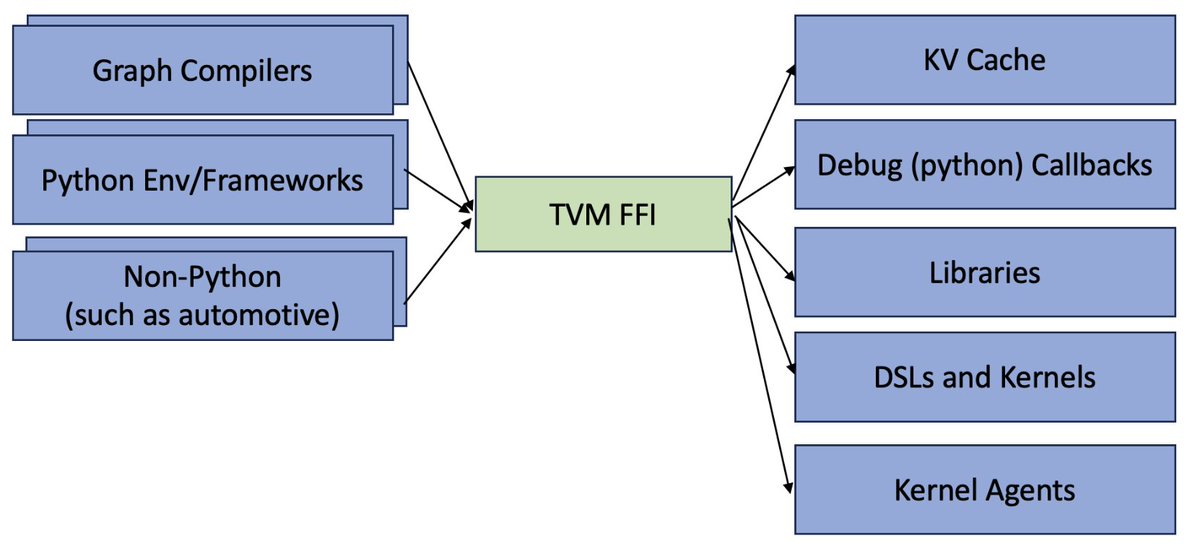
Through our past experiences building frontier ML kernels, megakernels, and agentic kernel systems, we kept seeing the same boundary problem: new operators and new hardware require new optimization strategies that often break old programming models or compiler passes.
TIRx builds on top of Apache TVM and moves toward a simple goal: let users and agents express the best-performing program, even for future hardware generations, while keeping the engineering effort for new kernels and new hardware as low as possible.