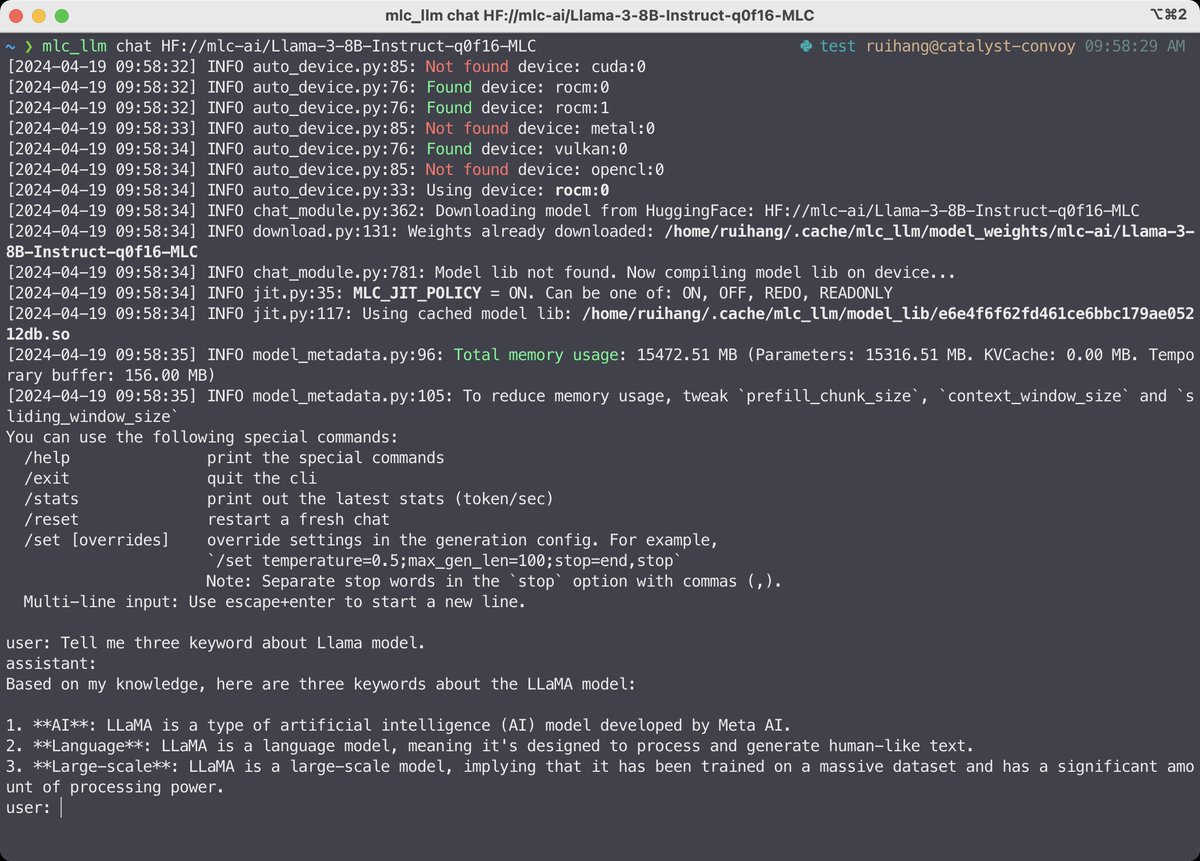
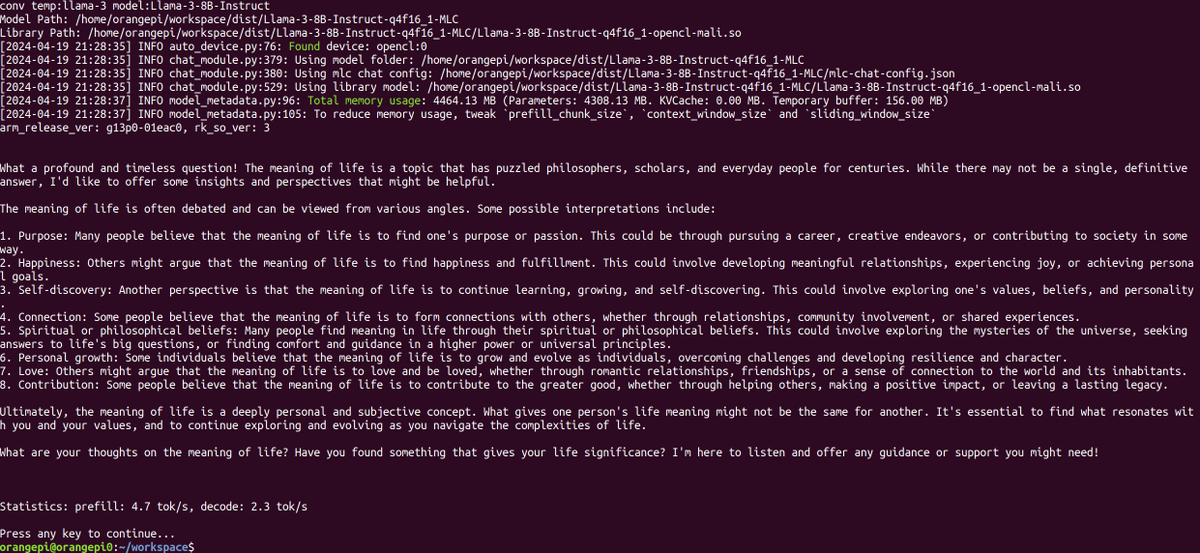
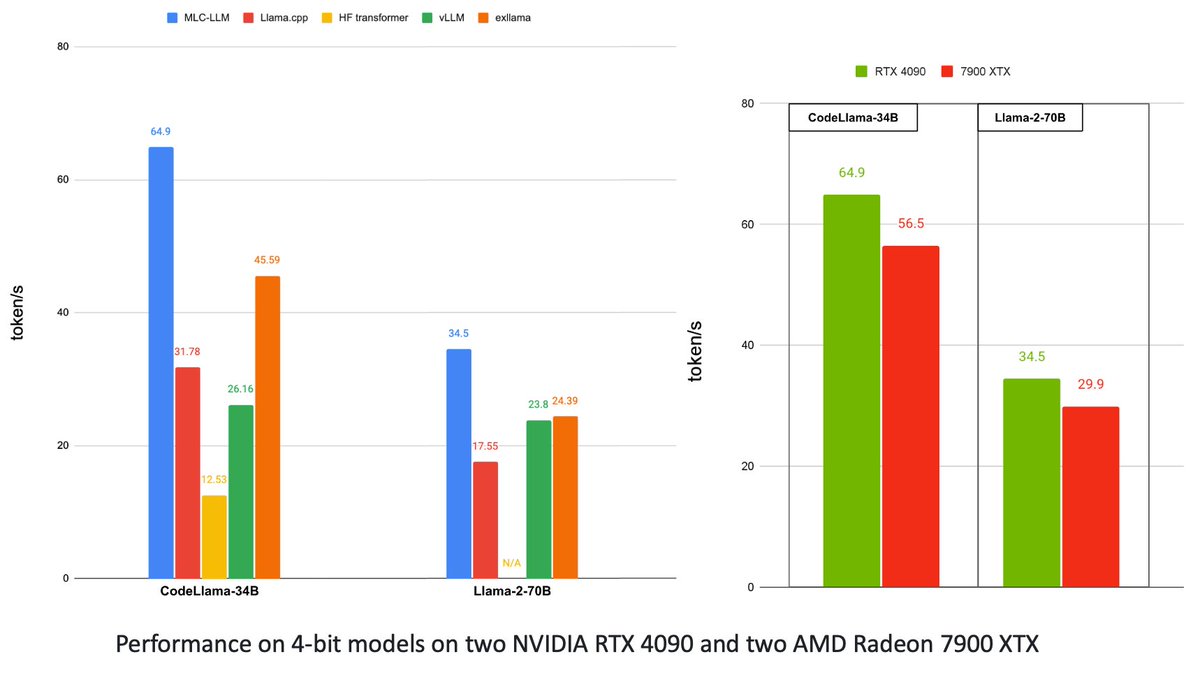
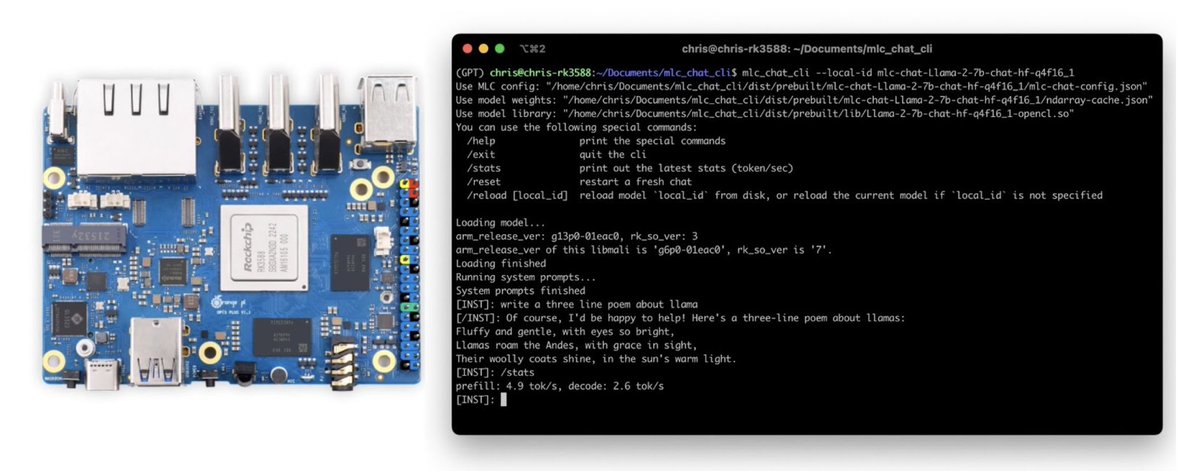
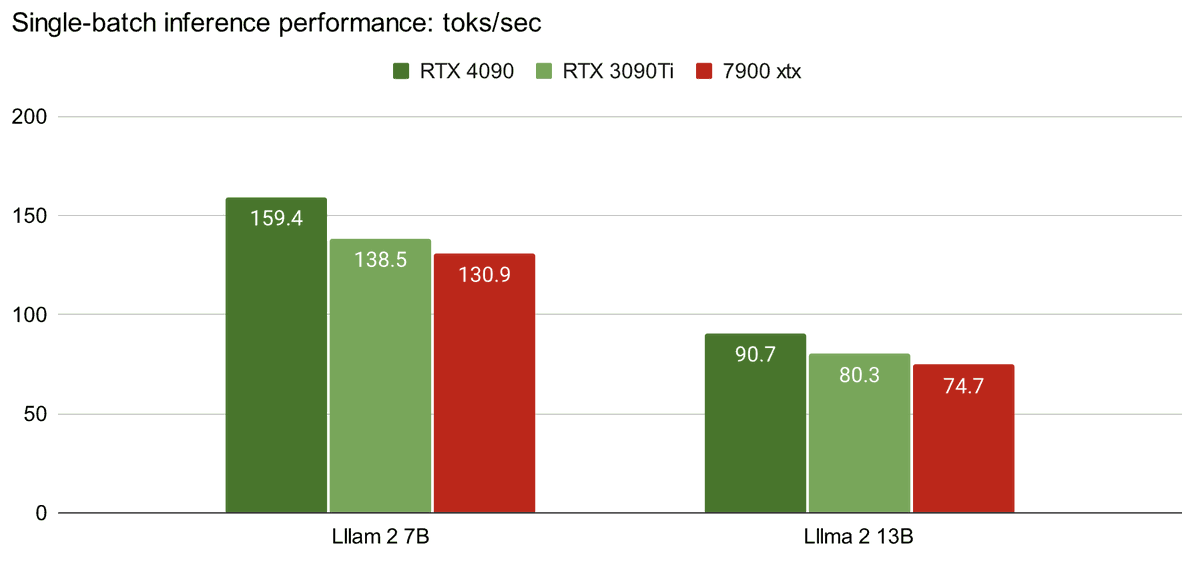
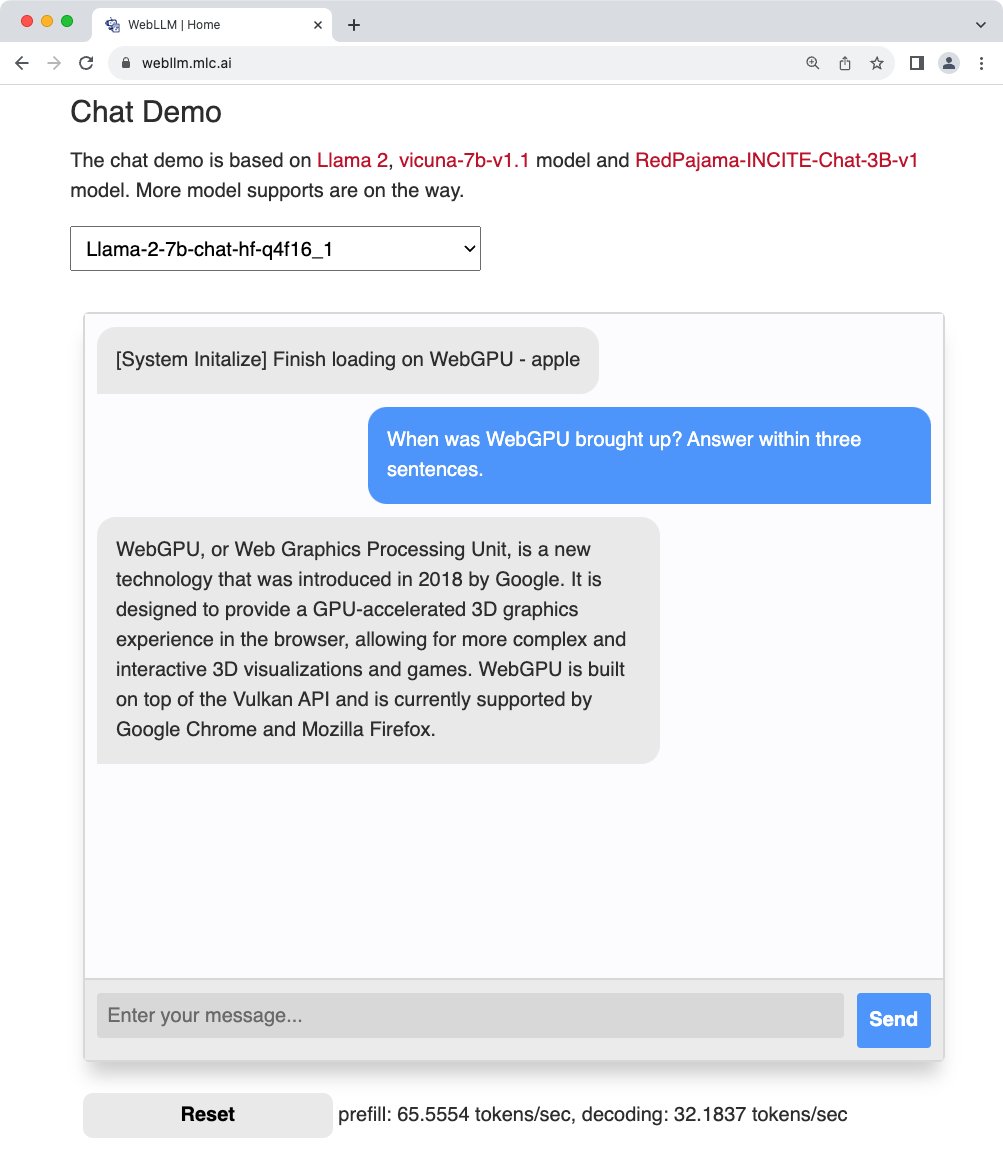
Bohan Hou retweetledi

📢Excited to introduce Apache TVM FFI, an open ABI and FFI for ML systems, enabling compilers, libraries, DSLs, and frameworks to naturally interop with each other. Ship one library across pytorch, jax, cupy etc and runnable across python, c++, rust tvm.apache.org/2025/10/21/tvm…
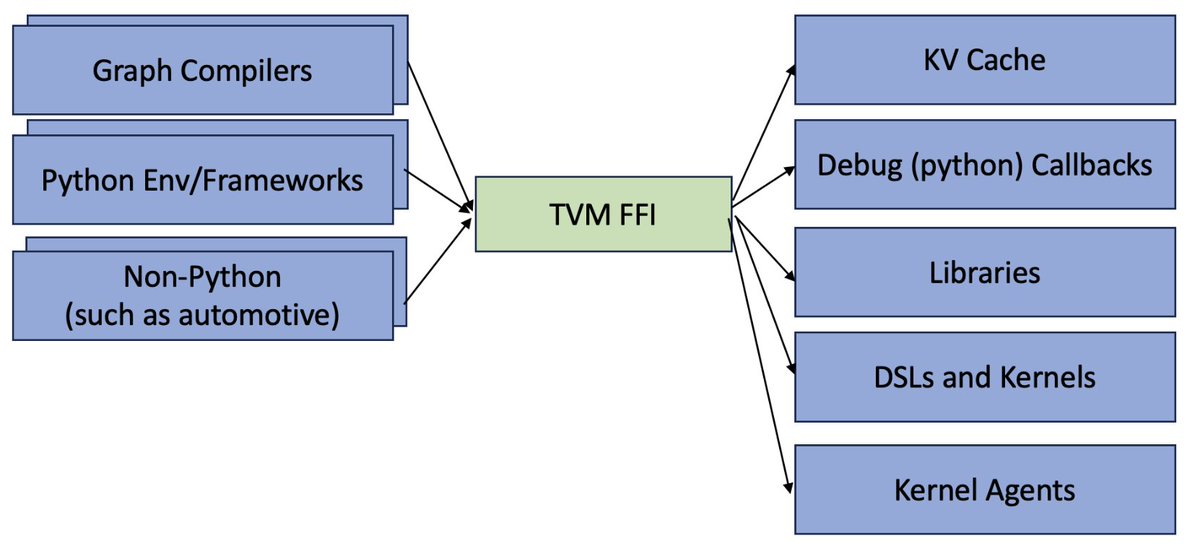
English