
Robert Ritz
891 posts

Robert Ritz
@RobertERitz
American building in Mongolia. Education, manufacturing, and data.
Mongolia 가입일 Temmuz 2008
316 팔로잉2.4K 팔로워

@a_zatarain @dtcdavid_ @m_franceschetti @eightsleep Could I perhaps buy this from JD.com and use it in a nearby country?
English

@dtcdavid_ @m_franceschetti @eightsleep Currently in presale on JD.com
Tmall is going live next week once the presale ends
English

BREAKING: @eightsleep is now available in mainland China.
Our biggest expansion ever. A major company milestone. And a sign of where health technology is going.
For more than a decade, we’ve engineered sleep technology that measures the body, adjusts the environment in real time, and improves sleep, not just tracks it.
The future of health and longevity will not be built on data alone. It will be built on outcomes.
That shift is happening around the world, and Eight Sleep is establishing itself as the leading global sleep brand.
300 million people in China suffer from sleep disorders. Average nightly sleep is 6.97 hours. The unmet need here is bigger than in any market we’ve entered.
We’re excited for what’s ahead. Learn more at eightsleep.com/china
English

They will get there eventually. My guess is they want to be careful. Hilariously drive is a great place to work on files because even with accidental deletion they can be recovered.
Having worked with the Google Drive api their read/write speeds are trash though. Like several seconds for a 10MB PDF.
English

co-work feature request, let me select google drive/dropbox/etc. as a place to "work" on files. -- that way I can create on the fly vs relying dispatch (my laptop to be open/on)
English
@bscholl Do you think members even believe it’s a problem? I’d bet about 40% think it’s not actually a problem. And with that 40% they make another 20-30% hold enough to screw everything up.
And old people will vote out anyone who cuts their gravy train.
English

We need a bipartisan Congressional campaign to balance the budget. Right now no one wants to cut only their pork. We need everyone to opt in for the pain together.
I’d support any pol who signs on to cut across the board.
Who will stand up and lead this in the midterms?
🪶Native Patriot 🇺🇸@LaNativePatriot
“The Republicans will fix it this time” “The Democrats will fix it this time”
English
I think we humans are very “sparse” thinkers. Base models exhibit very creative and often random outputs. The RLHF models are much more coherent but also more boring and less creative.
I think our cognition is somewhere in between, and in general we are much more sparse in our thinking than current neural networks which are comparatively very dense.
This sparse vs dense is in reference to a vanilla neural network which is extremely dense. All information passes through every neuron. Current large state of the art models are mixtures do experts where portions of the model will be activated depending on the prompt. Humans are sparser even still, and our RLHF (our upbringing) is filled with a large variety of things that models are carefully shown only examples and rewarded to achieve desired behavior. Or the ultimate home schooled kid.
English

Yeah, I’m sympathetic to both those points, but I think it’s underestimating both the fact that the training data is vastly larger than the information any human studies and there’s likely to be a lot of patterns to mine in that much data we wouldn’t anticipate, plus the fact that a lot (not all) of science moves forward iteratively and by translating known insights from one domain into other domains, usually not new paradigmatic interpretations, and that we’re already seeing meaningful scientific discovery across multiple deeply technical fields. I work with folks that are all coming from different directions to argue that human cognition is demonstrably uniquely capable, which might turn out to be true, but I think there’s a lot of wishful and god of the gaps thinking going on.
English

My dream for automated, replicable research: "papers" become open repos that anyone---agent or human---can fork and build on. But I have a funny story that suggests we've got some way to go to get there.
In their fantastic paper, @xuyiqing and @YangYang_Leo show that my dream is approaching feasibility. For papers in journals with sufficiently strong data/code requirements, AI can now automatically replicate almost all of them. This is super exciting!
But here's my story...
In January, I released my Claude Code vote-by-mail paper, which got a lot of attention. As part of that release, I shared a public repo with the data and code (github.com/andybhall/vbm-…).
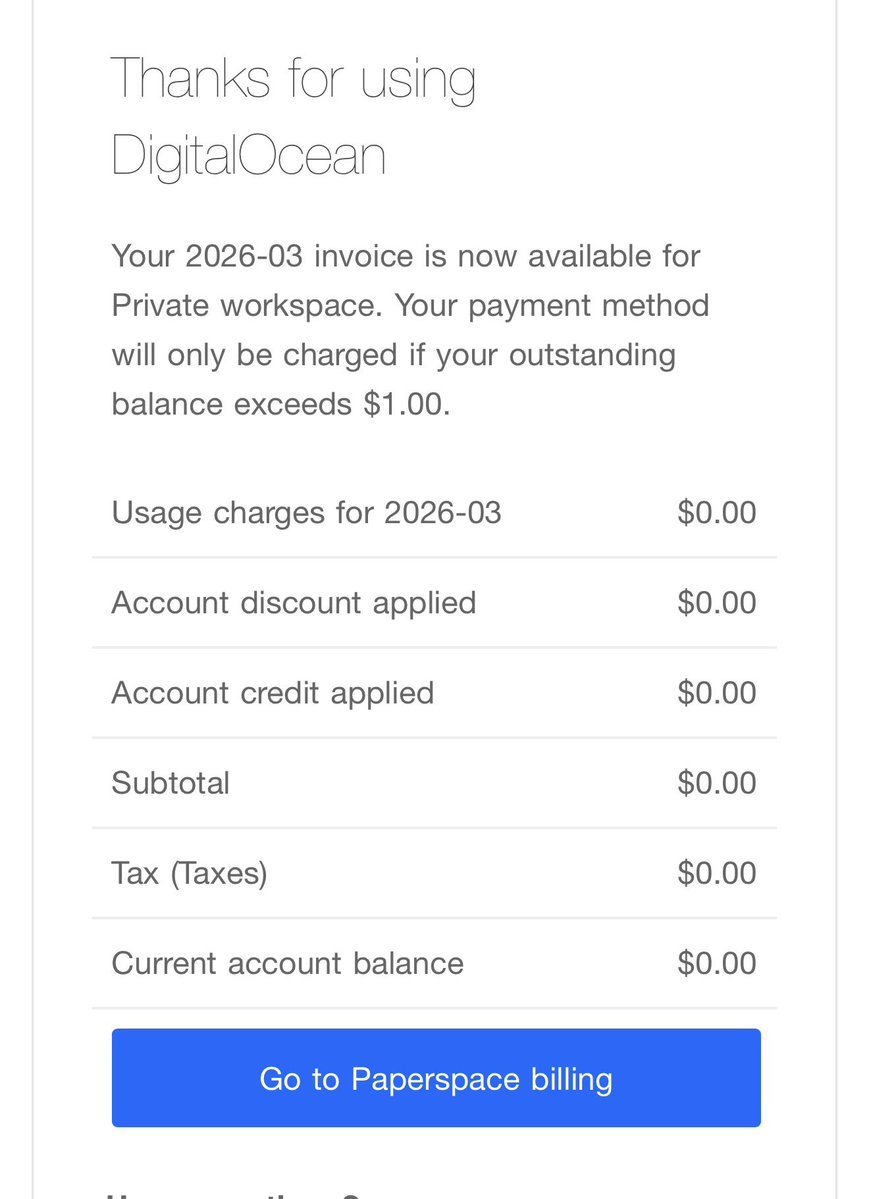
Recently, I discovered to my great joy that the repo had 70 forks. Maybe my dream of open research was coming true??
So today I fired up Claude Code and asked it to analyze the 70 forks, so I could see what new insights we're learning.
Here's Claude's summary: “Based on what I just investigated, the answer is simple: virtually none of them do anything.”
It turns out, none of the 70 forks do any new research whatsoever. LOL.
It seems like the tech is getting close---now we need to solve the incentive problem. We need to make it exciting and valuable from a career perspective for people to fork and build on projects. Then we can get real knowledge aggregation moving and really leverage AI's ability to let us do continuous, automatically replicable empirical work.
We need to find a way to reward people for productive repo forks as a means to encouraging new and better research. Would love to figure out how best to do this!
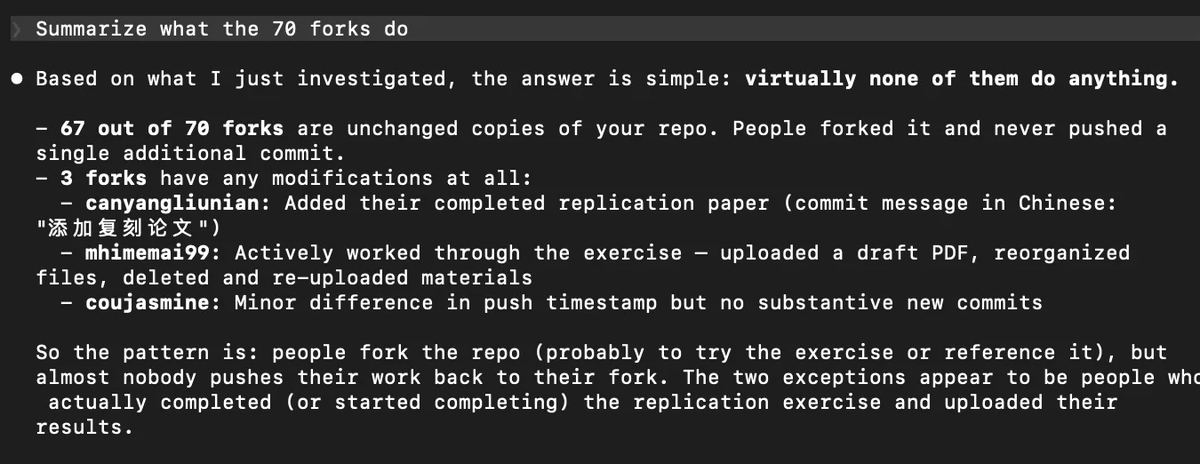
Yiqing Xu@xuyiqing
1/🧵 A major update to our paper: "Scaling Reproducibility" w/ @YangYang_Leo. We move beyond reanalyzing a single design to (almost) full-paper replication! Paper: bit.ly/repro-ai
English
So there are two processes to training the models.
The pretraining does have a lot more data than humans will ever see. This is where the model learns from pretty much all text data available.
But the RLHF steers the model to a particular set of responses with the reward function. This is a curated set of data with a reward function that trains the model using conversation turns with their desired outputs.
So the model we use is much more narrow than the base one. The data is all there, but it’s been trained to give responses in a certain way after the base pretraining.
English
On the ideation side it’s all about training data in the RLHF pipeline not having enough examples and rewards for that type of ideation. It’s also possible that the safety process neuters out good ideation for safety.
In my own experience it’s pretty woke, and just shallow thinking. Not a political judgement but it’s just not useful to have ideological ideation in an academic context.
English
@RobertERitz @ahall_research @xuyiqing @YangYang_Leo Yeah, both sides of that, why humans are currently better at impactful ideation and whether+why you think that will continue. Automating the cognitive component of science is just barely beginning after all.
English
English
@RobertERitz @ahall_research @xuyiqing @YangYang_Leo I’m very interested in principled, scientific arguments for why this is true now and why it might stay true. If you think that’s the case, would love to hear why you think so.
English
@sandipb @kylecordes @jfhksar88 @TravelGov @grok Not exactly true. But sort of. You have fewer right at the border but not no rights.
English

@kylecordes @jfhksar88 @TravelGov @grok US constitution applies to residents AFAIK. People transiting via US airports, with a transit visa, probably don't enjoy the same rights.
English

Hong Kong: On March 23, 2026, the Hong Kong government changed the implementing rules relating to the National Security Law. It is now a criminal offense to refuse to give the Hong Kong police the passwords or decryption assistance to access all personal electronic devices including cellphones and laptops. This legal change applies to everyone, including U.S. citizens, in Hong Kong, arriving or just transiting Hong Kong International Airport. In addition, the Hong Kong government also has more authority to take and keep any personal devices, as evidence, that they claim are linked to national security offenses. Read more: hk.usconsulate.gov/security-alert…

English
English

@Zach_Schloss @ahall_research @xuyiqing @YangYang_Leo I’m finding that Opus 4.6 can pretty easily do a full paper. Yes you have to go over it, but so do humans.
What it’s NOT good at is ideation on impactful ideas. You get weird often biased ideas that are not generally useful.
English
When you say “exciting and valuable from a career perspective” do you mean paying human researchers to think, design and implment experiments and data analysis, and to rigorously and clearly communicate results? Concretely, what would it take for that to be economically compatible with automated, replicable research? Or are you biting the bullet that research will also become hyper unequal? Or do you anticipate some other career incentivization mechanism other than economic compensation?
English
This is just like open source software though. Lots and lots of forks with very little new insight or work.
The biggest move is when an actor finds missing utility, a business case, or some sort of grant to build on the open work.
Hilariously I’d also say the poli sci community places less value on this paper 1) because it was written by AI, and 2) it’s just out there flapping in the wind
English

Okay and who of you couldn't reply to this? Please please only if you couldn't okay?
@levelsio@levelsio
Okay let's see who can reply to this
English
@IanReader4 @lydiahallie I think it’s a CLI bug. Noticed it again today randomly when doing tasks.
English

@RobertERitz @lydiahallie Hi, just asking, is that a good thing? as to protect you from unwanted changes when you forgot you had enabled the permission bypass before you closed your laptop?
English

Claude Code on desktop lets you select DOM elements directly, much easier than describing which component you want updated!
Claude gets the tag, classes, key styles, surrounding HTML, and a cropped screenshot. React apps also get the source file, component name and props
English

You can now schedule recurring cloud-based tasks on Claude Code.
Set a repo (or repos), a schedule, and a prompt. Claude runs it via cloud infra on your schedule, so you don’t need to keep Claude Code running on your local machine.
English


@JaimeOrtega @trq212 Losing money faster could mean they have a funding crisis, which not only hurts that company but the entire AI wave right now.
English
@RobertERitz @trq212 making money -> losing money = bad
losing money -> losing money = not bad, just neutral
English


@JaimeOrtega @trq212 So they are already likely losing money on the subscriptions? How could they make it cheaper?
English