고정된 트윗
DIMENSION
371 posts


DIMENSION
@_DimensionCap
A first-of-its-kind firm partnering with founders at the interface of technology and life sciences to transform the trajectory of life on earth
New York and San Francisco 가입일 Haziran 2022
26 팔로잉2.7K 팔로워
DIMENSION 리트윗함

Excited to announce our investment in Congruence Tx on the brink of entering the clinic with their first corrector program in genetic obesity!
Small molecule correctors are a unique drug class that behave exactly like they sound - correcting the folding of mutant proteins to regain function. Congruence is leveraging their AI discovery engine to develop novel correctors with nuanced design and extreme efficiency.
Incredibly proud to partner with this team on the next phase of the journey 🚀
Zavain Dar@zavaindar
.@_DimensionCap is leading a $40M financing for Congruence, leveraging frontier AI & molecular dynamics for a best in class small molecule corrector platform. This financing brings this high powered nimble team into the clinic w/ 3 unique assets. LFG! endpoints.news/congruence-sta…
English
DIMENSION 리트윗함

.@_DimensionCap is leading a $40M financing for Congruence, leveraging frontier AI & molecular dynamics for a best in class small molecule corrector platform. This financing brings this high powered nimble team into the clinic w/ 3 unique assets. LFG!
endpoints.news/congruence-sta…
English
DIMENSION 리트윗함
inspired by writings of @karpathy & @ericjang11 we built an autoresearcher via Claude & @modal
within 48 hours we’d beat published baselines in protein thermostability
we’re not pivoting to a neolab 🙃 but here’s what a small team w curiosity & gumption can do w todays tools
Frank Gao@ChemVagabond
We @_DimensionCap ported @karpathy's autoresearch framework to biology. We let Claude run 50 experiments over the weekend on protein thermostability prediction via @modal. It beat a recent baseline (TemBERTure) using a 20x smaller model. Code + research blog later this week!
English
DIMENSION 리트윗함

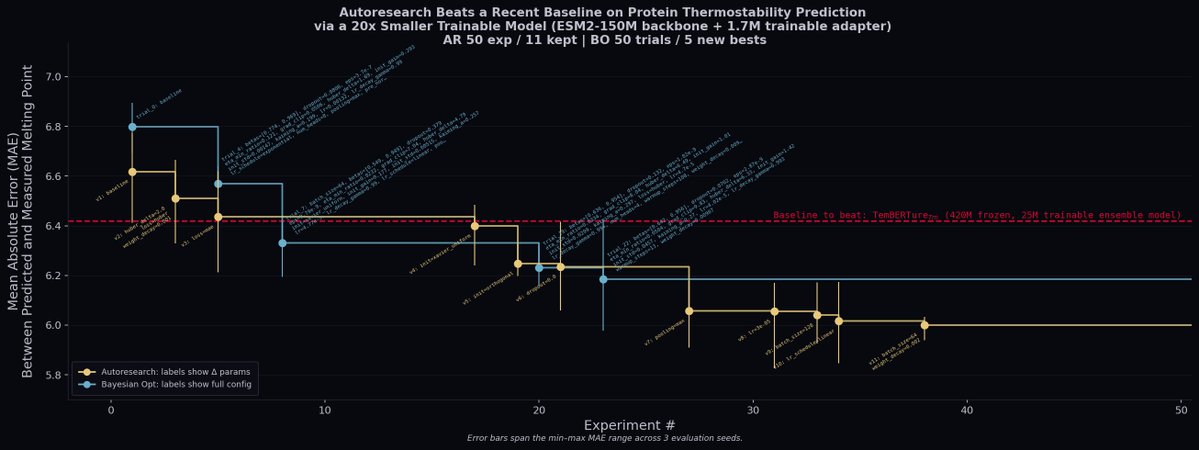
We @_DimensionCap ported @karpathy's autoresearch framework to biology.
We let Claude run 50 experiments over the weekend on protein thermostability prediction via @modal.
It beat a recent baseline (TemBERTure) using a 20x smaller model.
Code + research blog later this week!
English
DIMENSION 리트윗함

Can't think of a better first X post for @_DimensionCap's newest research ~ Frank Gao (@ChemVagabond).
We ran @karpathy's autoresearch framework using @modal this weekend ~ focusing on protein thermostability prediction.
50 experiments in and much more to come this week!
👇
Frank Gao@ChemVagabond
We @_DimensionCap ported @karpathy's autoresearch framework to biology. We let Claude run 50 experiments over the weekend on protein thermostability prediction via @modal. It beat a recent baseline (TemBERTure) using a 20x smaller model. Code + research blog later this week!
English
DIMENSION 리트윗함



DIMENSION 리트윗함
We find this failure mode counter intuitive and too expensive to ignore in this technological moment
Today, as @_DimensionCap crosses it's 4th birthday, we're openly publishing the letter
pages: 4-7




English
DIMENSION 리트윗함
Memo: What If We're Right?
We recently wrote a private letter to partners & friends of a common failure mode: the inability to consistently reason through the daisy chain of downstream consequence when non-consensus, low-probability, events actually occur
pages: 1-3



English
DIMENSION 리트윗함
DIMENSION 리트윗함
I’m in Boston this week for the TD Cowen conference. If you’re around Copley Square and want to chat—please DM!
English
DIMENSION 리트윗함
Congratulations to @tamarindbio on the announcement of their $13.6M Series A led by @_DimensionCap!
Tamarind is the central town square for bio foundation models. They enable ML engineers, computational biologists, and wet-lab scientists alike to easily access and scale the most cutting-edge tools for drug discovery.
We are thrilled to partner with @kavi_deniz and Sherry Liu to build the core infrastructure for AI-enabled drug discovery where the next generation of therapeutics will be designed!
forbes.com/sites/the-prot…
English
DIMENSION 리트윗함

Today, we announce Tamarind Bio’s $13.6M Series A, led by @_DimensionCap, with participation from @ycombinator.
Tamarind has now become the trusted platform for molecular AI inference, serving tens of thousands of scientists, including 8 of the top 20 pharma, dozens of biotechs and research organizations.
Since last year, we’ve grown revenue 7x and are grateful to work with world-class biopharma R&D organizations like @Bayer, @Boehringer, and Adimab.
—
When we started two years ago, a few brave biotechs took a chance with us. Hoping this new company, providing easy access to computational drug discovery tools, would enable their scientists to apply foundation models to real therapeutic applications.
Since then, our library of AI models has grown to hundreds, not just open-source tools, but also our users’ internal protocols, proprietary models trained on users’ own data, pipelines of multiple models together and more!
Now, we are doubling down on our commitment to building the core AI and data infrastructure to power the next generation of medicines. We will continue to support open models, strengthening them with proprietary data, and prioritize access to all scientists.
Join us as we build the infrastructure for all AI-powered drug discovery.
English
DIMENSION 리트윗함

Excited to announce @_DimensionCap's partnership with Deniz and Sherry on Tamarind Bio! They are building the unified operating system and inference cloud for life science and have been on a tear in the past year.
Between landmark model access deals and dedicated supercomputer builds, BioPharma is making more software and ML investments and Tamarind has built a killer product to help with ML adoption.
Super excited for the path ahead and read more about our involvement here:
dimensioncap.com/blog/leading-t…
Deniz Kavi@kavi_deniz
Today, we announce Tamarind Bio’s $13.6M Series A, led by @_DimensionCap, with participation from @ycombinator. Tamarind has now become the trusted platform for molecular AI inference, serving tens of thousands of scientists, including 8 of the top 20 pharma, dozens of biotechs and research organizations. Since last year, we’ve grown revenue 7x and are grateful to work with world-class biopharma R&D organizations like @Bayer, @Boehringer, and Adimab. — When we started two years ago, a few brave biotechs took a chance with us. Hoping this new company, providing easy access to computational drug discovery tools, would enable their scientists to apply foundation models to real therapeutic applications. Since then, our library of AI models has grown to hundreds, not just open-source tools, but also our users’ internal protocols, proprietary models trained on users’ own data, pipelines of multiple models together and more! Now, we are doubling down on our commitment to building the core AI and data infrastructure to power the next generation of medicines. We will continue to support open models, strengthening them with proprietary data, and prioritize access to all scientists. Join us as we build the infrastructure for all AI-powered drug discovery.
English
DIMENSION 리트윗함
♻️ Recursive language models (RLMs) are incredibly cool and now is the time to be paying attention to them.
Reasoning models are clearly the frontier. They've matured at breakneck speed. We've gone from simple chains-of-thought to sophisticated test-time scaling paradigms in a few years.
Great! But how can we make reasoning more efficient at scale?
--
‼️ TL;DR
Do surgery on an existing transformer. Install an internal recursion mechanism to create an RLM.
The model's immune system will respond. That's okay. Conduct a 'healing phase' to reawaken the RLM to its new, hybrid reality.
You don't need to do RL or SFT with valid reasoning traces to amplify higher-level thinking.
Now, instead of scaling tokens/context at test-time to boost reasoning, the thinking happens within the model's latent space as it iteratively polishes its hidden state -- saving inference compute.
Current reasoning models pay for every thought twice—once to generate the token, once to store it.
RLMs think in place, exiting tokens only when ready. What's the new efficiency ceiling? Couldn't tell ya'.
Is this a robust procedure yet? No.
Do we know how the method scales or if we can reapply any other modern reasoning mechanisms? Also no.
Is it obvious how far RLMs will take us or if they'll be the prevailing paradigm? Definitely not.
But if we knew all these answers, it wouldn't be as interesting to read about.
More detailed mini-essay below.
👇
--
⏩ Skip this section if you don't want the background.
I found out about RLMs at the inaugural workshop on efficient reasoning at @NeurIPSConf, where they were a fixture.
It struck me how tech progress is rarely linear. It ebbs and flows with funding cycles, grinds to a halt if technology barriers pile up, and can explode with one eureka moment.
But other times cool ideas fade into the scientific backwater if we get fixated on something that works. That's sort of what happened with the 2017 transformer unlock.
We got these smooth-looking scaling laws with a simple recipe of parameters, tokens, and FLOPs. As pretraining waned, the field has moved into post / test-time training to keep the party going, and to much success.
So, why not keep spamming this formula? I certainly would, especially if I'm a multi-billion $ frontier lab that can't afford to fall behind, break a narrative, etc.
Engineering inertia is very real.
That's why RLMs were so cool to hear about. It was like rediscovering an idea. Recursion isn't new, by any means.
But every once in a while, ideas orbit back around. The immense gravity of parallel-processing via transformers seems to have pulled recurrent scaling back into the limelight.
--
▶️ RLM stuff starts here.
The transformer essentially killed recurrent neural networks (RNNs) for language-modeling tasks.
RNNs excel in some areas like real-time processing of sequential data, but they're notoriously hard to train as gradient updates can vanish/explode inside them. They also don't take advantage of GPU parallelism to the same extent.
But was there a way to have one's cake and eat it too with some sort of hybrid model? Yes!
Universal Transformers (UTs, 2018) were kind of like patient zero for this idea.
You exploit the parallel attention of a transformer, but impose a recurrent inductive bias that exists in depth rather than sequence position.
Basically, you're refining a hidden state representation at each token position until the model decides it's done thinking. But when's that?
Ponder time (a/k/a adaptive computation time, ACT) came out a few years earlier. Here, you embed a lightweight halting classifier at each position that determines its doneness.
Similar ideas were floating at the time, like neural GPUs, neural Turing machines, etc, but I like UTs because they combined global attention with recurrent depth and dynamic halting and also showed they could smoke vanilla transformers on contemporary benchmarks.
arxiv.org/abs/1807.03819
--
The main RLM work I want to talk about combines several modern ideas (e.g., test-time scaling, recurrence, latent reasoning). The lead author @jonasgeiping also gave the talk!
Conceptually, the idea is that humans don't vocalize our intermediate thoughts while reasoning, which is what current reasoning LLMs do -- they construct their reasoning trajectories via token-scaling.
Using a prior on metastable brain waves, we talked about how neuronal activity bounces between these 'thinking modes' defined by MRI activity. So how can we bio-mimic this?
Well, we can reason in the model's latent space rather than forcing thinking through the pinhole of token verbalization. Neat, but how?
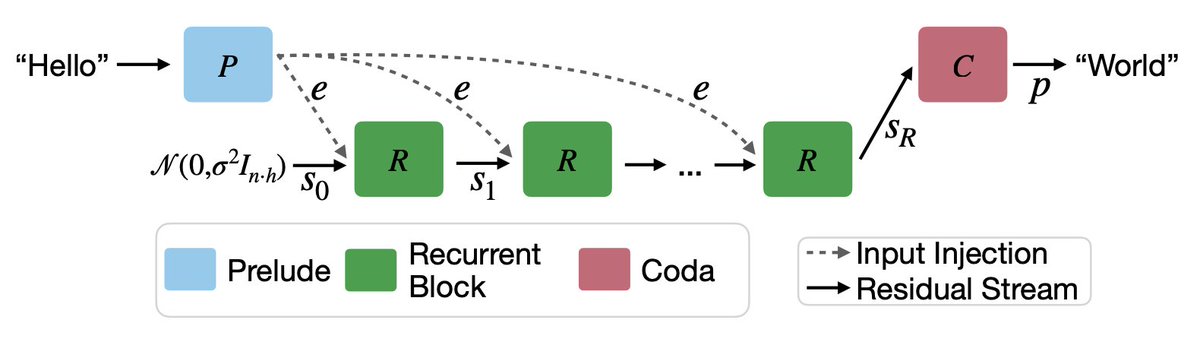
They made Huginn-0125, a 3.5B parameter model trained on 0.8T tokens. It's got three main parts: an encoder section (prelude), the inner recurrent block (R), and a decoder (coda), shown below.
Importantly, there's a residual stream that concatenates the tokenized (but unaltered) input through each iteration to ensure training/inference stability.
Huginn wasn't trained with an explicit number of iterations (k), but rather via random (Poisson distributed) k un-rollings, making sure the model stays on it's toes and doesn't expect to exit at a specific time.
At test-time, the model dynamically iterates the hidden state through the R block, polishing each position until it's ready to go.
The paper fully admits the model was trained sub-optimally for budget reasons, so I read this as a proof-of-principle, which makes the results even more exciting because there's a lot of work that can be stacked quickly.
Without any RL or SFT on reasoning traces, Huginn is pretty competitive with models 2-3 its size on reasoning tasks (e.g., GSM8k).
In effect, this is another way to scale at test-time.
You simply increase iteration count in latent space instead of blowing up your token count as is currently being done.
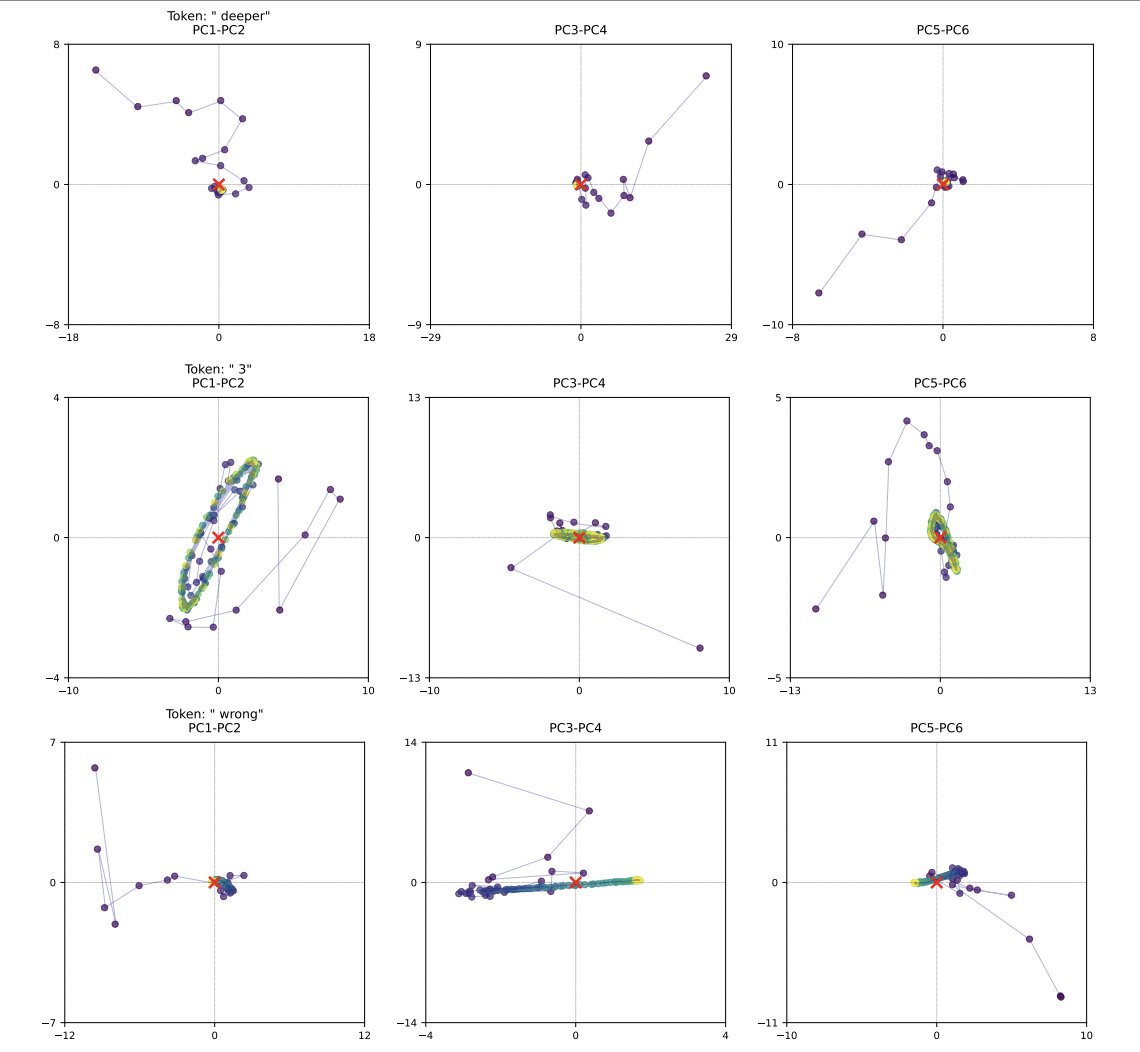
What really blew my mind was the call-back to brainwave regimes. They ran a PCA analysis of the model's latent space trajectories, finding that it sometimes converges on these orbital-like shapes during certain tasks.
That's crazy to me because we saw the same thing with the MRI scans. I don't want to get heavy-handed with the bio-analogies, but this is 'pinch me' stuff.
I think this is important because latent reasoning loses interpretability by default, so some semblance of a way to monitor these trajectories could be useful.
arxiv.org/pdf/2502.05171
--
Many of the same authors (+ @SeanMcleish) did some important follow-up work that cements a few guardrails around RLMs and also an important concept --
You can adapt pre-trained transformers to do recurrent, latent reasoning. You don't need to start from scratch. This opens up doors for accessibility quite a lot.
First, they find that you can take a many-layer, non-recurrent pre-trained transformer and cut it into the aforementioned prelude/recurrent/coda blocks.
While this was originally traumatic for Llama, they noticed that additional training (healing) can adapt the network to the new inductive bias. Also, they find that initializing from the pre-trained weights is vastly more FLOPs-efficient.
Compared to Huginn-0125, this retrofitted recurrence method was +12 points on MMLU and +7 points on GSM8k despite Huginn having 4-5x more parameters and being trained on 0.8T of data.
Economically, this sounds like model distillation to me. At least in the sense you take a pre-trained teacher and build a smaller (in this case, depth-scalable) student without paying the full cost again.
openreview.net/pdf?id=Oq3Xblt…
--
I'll close with a bit of efficiency talk. We've seen how these RLMs can be created, even forked from existing open-source models, but I want to talk about economics.
Another work points to the fact that Huginn-0125 was much slower (a factor of k) than the non-recurrent versions. We need some early threads about how to recover that speed.
From the original paper Huginn-0125 paper, we know that some token positions mature quicker than others. Simpler iterates can exit quicker than others. So, this follow-up work addresses that by noting conceptual/mathematical similarities with diffusion.
I could be wrong, but my understanding is that you can consider an RLM to be a continuous, latent diffusion model. Obviously the randomized unrolling objective is different than static denoising, but the analogy holds.
So, they flip the recurrent process from batch processing to an assembly-line. Because some token positions finish early, waiting for the whole batch to be done is inefficient.
They use a different sampler that fills the token position x iteration depth grid on a diagonal wavefront. At each step, you advance active positions by a step, decode draft tokens at the frontier, and freeze stable tokens.
It's a bit like speculative decoding.
You don't necessarily save on FLOPs, but you are exploiting GPU parallelism in a way the initial, sequential setup left on the table. This netted a 5x speed-up with minimal accuracy loss, though obviously there's still much room to run.
openreview.net/pdf?id=nA5IRfA…
--
Alright, here's the rub.
On paper, nothing about RLMs seems economically appealing as of today.
Recurrent depth imposes a speed penalty that has only been partially offset with wavefront diffusion sampling. This is substantially behind transformers and not anywhere close to cases where time-to-first-token matters.
There are new failure modes (e.g., overthinking can lead to inverse scaling), new hyper-parameters, less mature tooling, etc.
Current performance doesn't appear to be an OOM better than token-scaling.
So, why be excited about this?
Well, consider a future where frontier labs have multiple different models/architectures under the hood that they route to different requests depending on what the situation calls for (with gross margin being ubiquitous in the denominator).
The fact that RLMs have fixed hidden states regardless of iteration count is important, especially if juxtaposed against KV caches that grow linearly with chain-of-thought methods.
Theoretically, RLMs are Turing complete and can loop ad infinitum, maybe allowing them to address extremely difficult tasks that feed-forward networks can't, though there's zero proof of this yet?
I'm not sure how many latent iterations will be needed to approximate equivalent token-scale reasoning, but if it's relatively small, I can see a place for RLMs to co-exist.
There will need to be new infrastructure.
Maximizing inference efficiency seems like the biggest one. We'd need routers/schedulers that assume fixed KV and dynamic iteration. Perhaps some purpose-built kernels for diagonal wavefront sampling, exit tracking, etc could be useful optimizations?
I'm really hoping this stuff goes mainstream!

English
DIMENSION 리트윗함

Join the early team @CoefficientBio. We have an AI team that I’m incredibly proud of, and truly think is the most effective and exceptional technical team building in AI x bio.
We're looking for people to:
* Build and maintain robust AI systems to an exacting standard
* Design and run experiments that let us iterate fast
* Work on challenging scientific and engineering problems for human flourishing
NYC-based (or willing to relocate).
If you’re curious about what we’re building, reach out directly. If we don’t know each other yet, a great cold DM (or email: join@coefficientbio.com), or warm intro goes a long way.
English

DIMENSION 리트윗함

I joined @_DimensionCap.
I make $1-50m+ investments. Pre-seed to Public. Infra, horizontal apps, life sciences.
I’m Nikhil. Our website is dimensioncap.com. My email is a combination of those.
English
ecstatic to welcome @nikhilvnamburi to the @_DimensionCap team!
nikhil is an investor’s investor & technologist’s technologist. if you’re debating the state of ML/infra, building and want a strategic copilot, or raising $ to accelerate your vision.. reach out to Nikhil below 👇
Nikhil Namburi@nikhilvnamburi
I joined @_DimensionCap. I make $1-50m+ investments. Pre-seed to Public. Infra, horizontal apps, life sciences. I’m Nikhil. Our website is dimensioncap.com. My email is a combination of those.
English

@zavaindar @nikhilvnamburi @_DimensionCap This strategy is brilliant! Invest in the cutting edge deep tech application companies + the infra/tools they need to build the applications. See and own the whole picture of the future.
English
Excited to welcome @nikhilvnamburi to the investment team at Dimension!!
Nikhil brings an investment background in compute / ML infrastructure to the team and will help the firm continue to expand our work in cutting-edge technology and science.
In addition to his domain expertise, Nikhil brings a deep curiosity for the technologies and the businesses shaping the modern internet and a passion for the craft of investing.
Welcome Nikhil!
dimensioncap.com/people/nikhil-…

English