Nikhil Chandak@nikhilchandak29
✨New work: How do we train language models for open-ended forecasting?🔮
For example, consider “Which tech company will the US government buy a > 7% stake in by September 2025?”.
This requires one to explore the outcome space, not just assign probabilities to choices (as in most binary questions in prediction markets).
Instead of picking from “Yes/No” options, we forecast in natural language: name the outcome + state your probability of it being correct.
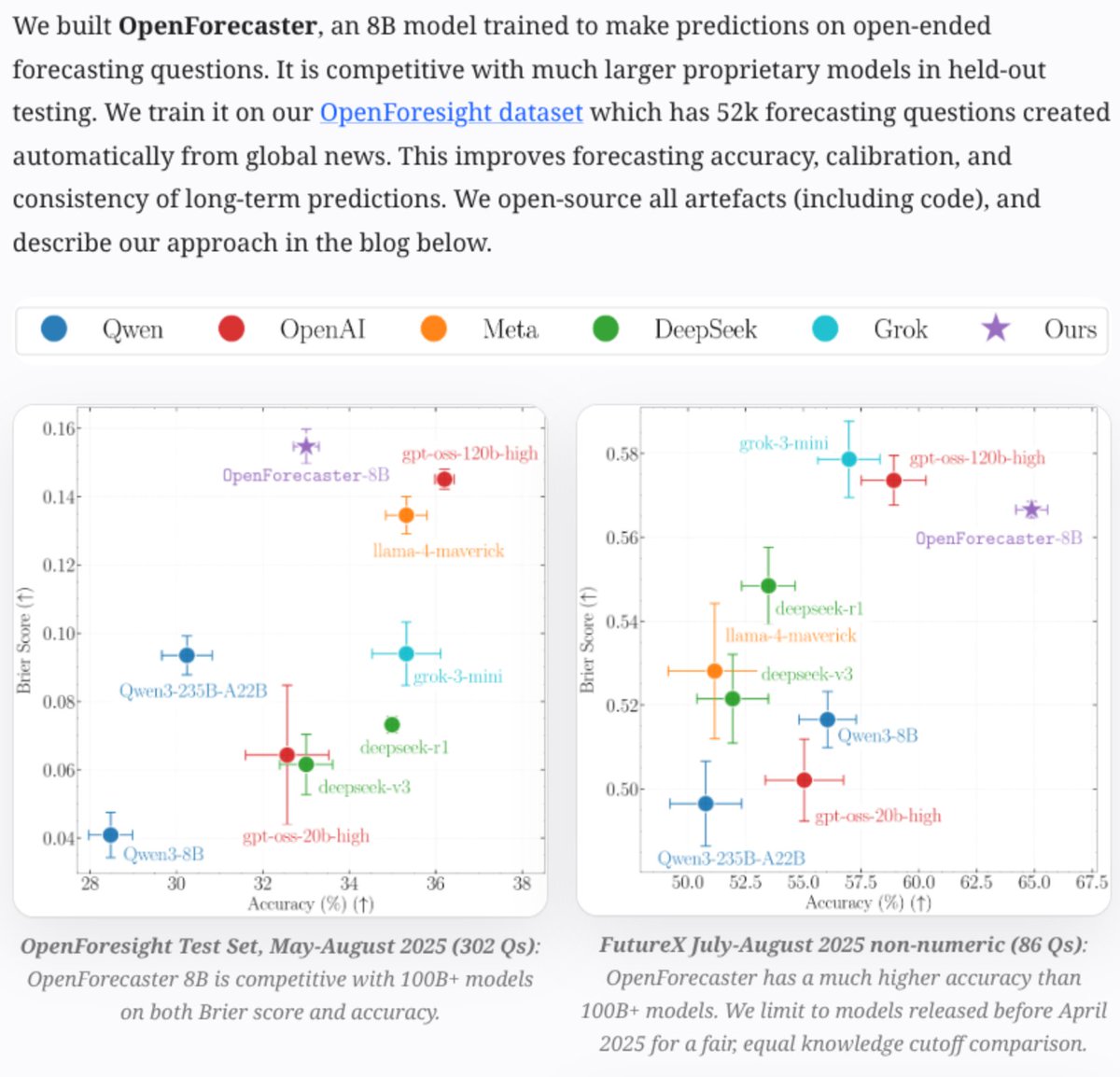
Results: with our data and post-training recipe, our OpenForecaster-8B model outperforms much larger models on calibration (Brier Score) and is competitive on accuracy, on held-out testing over 4 months.📈✅