
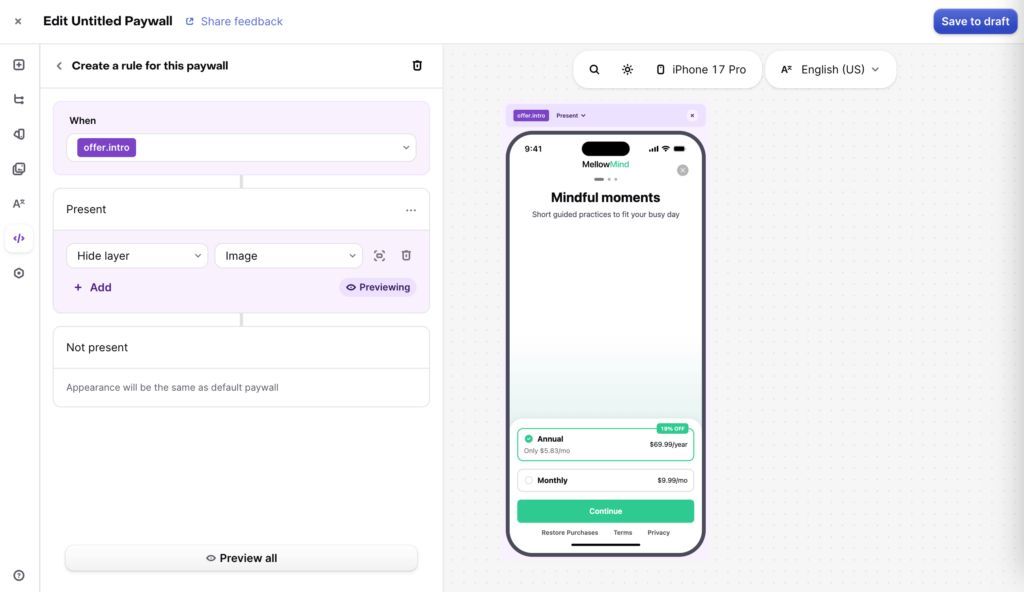
@RevenueCat the no release part is the win. way easier to test offer logic fast
English
Suresh
6.1K posts

@_Suresh2
MSc Software Engineering @ Chongqing University ’26 | Researching AI x Software Engineering (AI for SE & SE for AI) | 🇵🇰➡️🇨🇳





I have been using GPT ImageGen-2 for the past weeks I didn't think that better image-generators would be a big deal but it turns out that there is a quality threshold I didn't expect, where you can now get text, slides, academic papers Look at what it does with my "otter test"!


🚨 New @GoogleDeepMind paper 𝐑𝐨𝐛𝐮𝐬𝐭 𝐑𝐞𝐰𝐚𝐫𝐝 𝐌𝐨𝐝𝐞𝐥𝐢𝐧𝐠 𝐯𝐢𝐚 𝐂𝐚𝐮𝐬𝐚𝐥 𝐑𝐮𝐛𝐫𝐢𝐜𝐬 📑 👉 arxiv.org/abs/2506.16507 We tackle reward hacking—when RMs latch onto spurious cues (e.g. length, style) instead of true quality. #RLAIF #CausalInference 🧵⬇️

🚨 Excited to announce Gistify!, where a coding agent must extract the gist of a repository: generate a single, executable, and self-contained file that faithfully reproduces the behavior of a given command (e.g., a test or entrypoint). ✅ It is a lightweight, broadly applicable evaluation that tests whether models can reason at the codebase level 😯 Even strong LLMs/frameworks struggle, especially on long, multi-file traces!









SpaceXAI and @cursor_ai are now working closely together to create the world’s best coding and knowledge work AI. The combination of Cursor’s leading product and distribution to expert software engineers with SpaceX’s million H100 equivalent Colossus training supercomputer will allow us to build the world’s most useful models. Cursor has also given SpaceX the right to acquire Cursor later this year for $60 billion or pay $10 billion for our work together.


Excited to share our latest blog post on how we're solving real-world LLM inference challenges at production scale, a collaboration between @RedHat_AI and Tesla engineering teams. We hit the usual pain points: massive model weights choking storage, GPU cycles wasted on naive load balancing, infrastructure that fights you when nodes go down. Our answer: KServe + @_llm_d_ + @vllm_project with prefix-cache aware routing. The results: 3x more output tokens/sec and 2x faster time to first token. Thanks everyone who've contributed to this successful adoption: Scott Cabrinha, Sai Krishna, Sergey Bekkerman, Nati Fridman, Killian Golds, Andres Llausas, Bartosz Majsak, Greg Pereira, Pierangelo Di Pilato, Ran Pollak, Vivek Karunai Kiri Ragavan, Robert Shaw

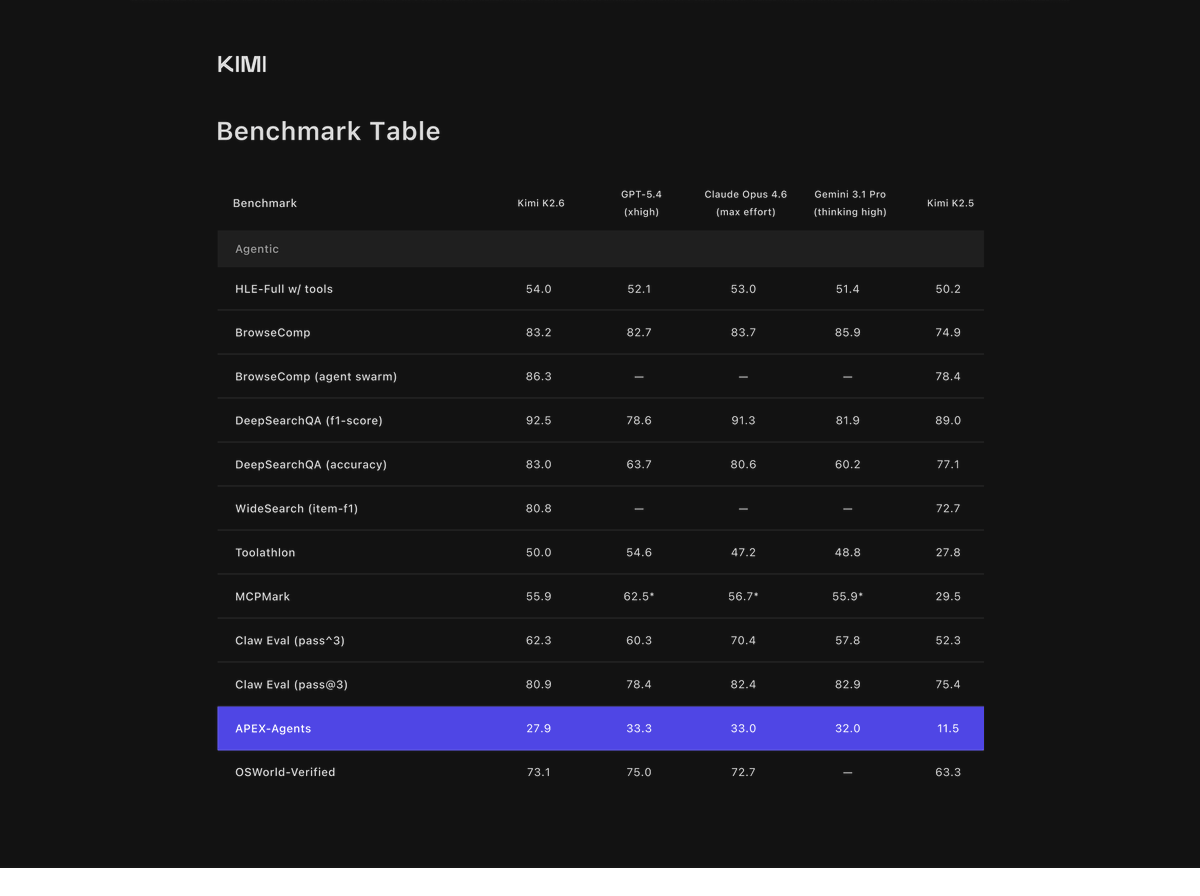
Meet Kimi K2.6: Advancing Open-Source Coding 🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2) What's new: 🔹Long-horizon coding - 4,000+ tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization). 🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP + Framer Motion, Three.js 3D. 🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100+ files. 🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops. 🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop. - K2.6 is now live on kimi.com in chat mode and agent mode. For production-grade coding, pair K2.6 with Kimi Code: kimi.com/code - 🔗 API: platform.moonshot.ai 🔗 Tech blog: kimi.com/blog/kimi-k2-6 🔗 Weights & code: huggingface.co/moonshotai/Kim…

i think you need to be a little bit stupid to work on neural nets. if you're too smart and too good at math you won't make any progress


