고정된 트윗

Created a video how to train Flux LoRAs using my convenience script utilizing ai-toolkit on @quickpodio
youtu.be/0I06JHyvuwQ

YouTube
English
Aivan Monceller
956 posts

@aivandroid
I share interesting things I find, what I’m learning, and projects I’m trying. Follow me if you like tech, creative stuff, and learning new things. INFJ-T

Just let Opus go for over an hour on a new feature. When it was done, I asked how I can test it. 20 minutes later, it realized I can't test it because it did the whole thing entirely wrong. Idk how you guys use this model every day for real work 🙃


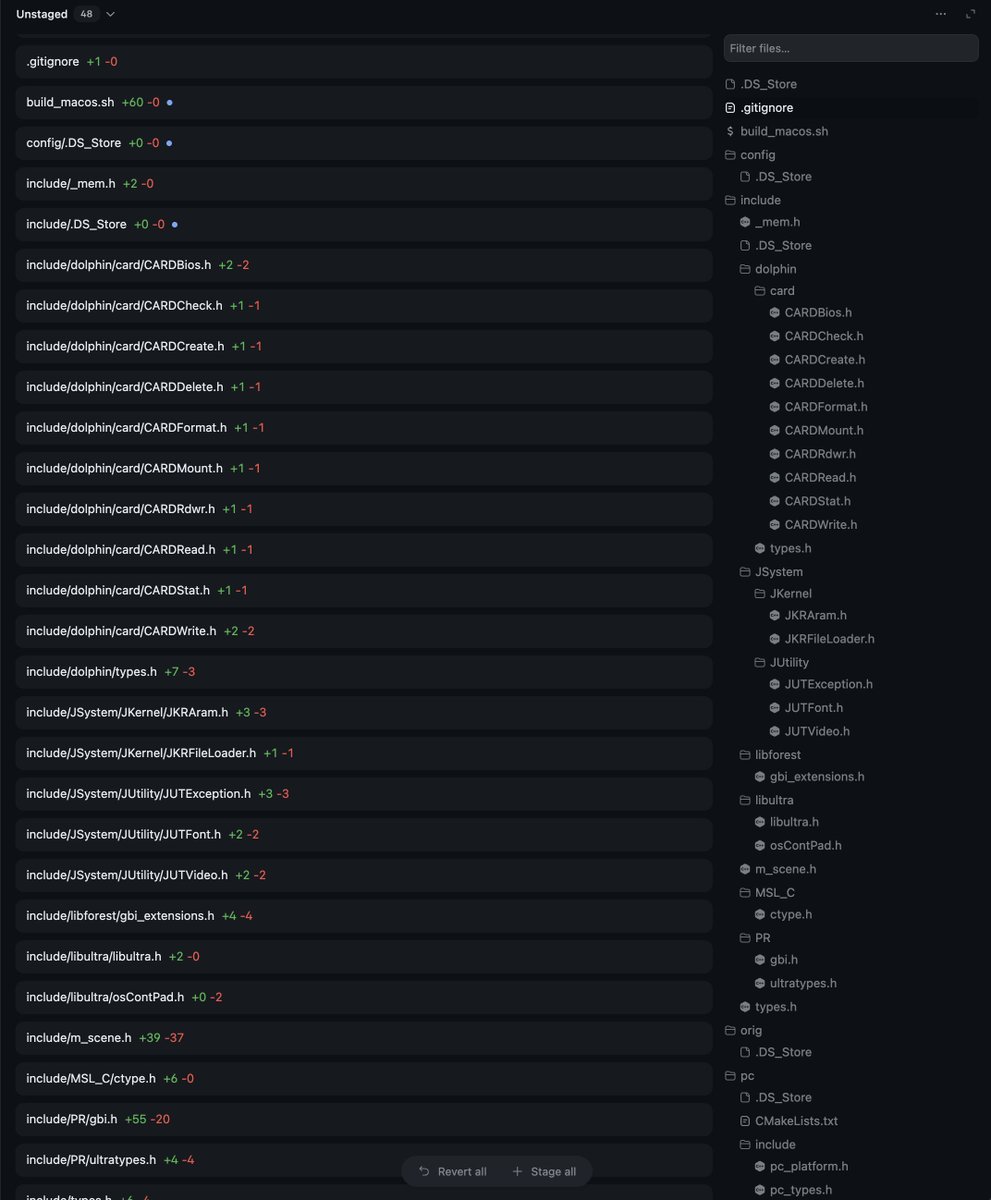

Introducing Storage Buckets on Hugging Face 🧑🚀 The first new repo type on the Hub in 4 years: S3-like object storage, mutable, non-versioned, built on Xet deduplication. - Starting at $8/TB/mo. That's 3x cheaper than S3. You (and your coding agents) need somewhere to dump checkpoints, logs, and artifacts. Now they have a home.









X Support it completely broken I lost my account and email was changed Looking at this automation, it just checks your email to verify you as an account owner. The verification done before using your passport or government ID is not used Worse is no human will verify your identity This is what you get after paying X Premium Plus, the most expensive plan @X will just take your money and run





