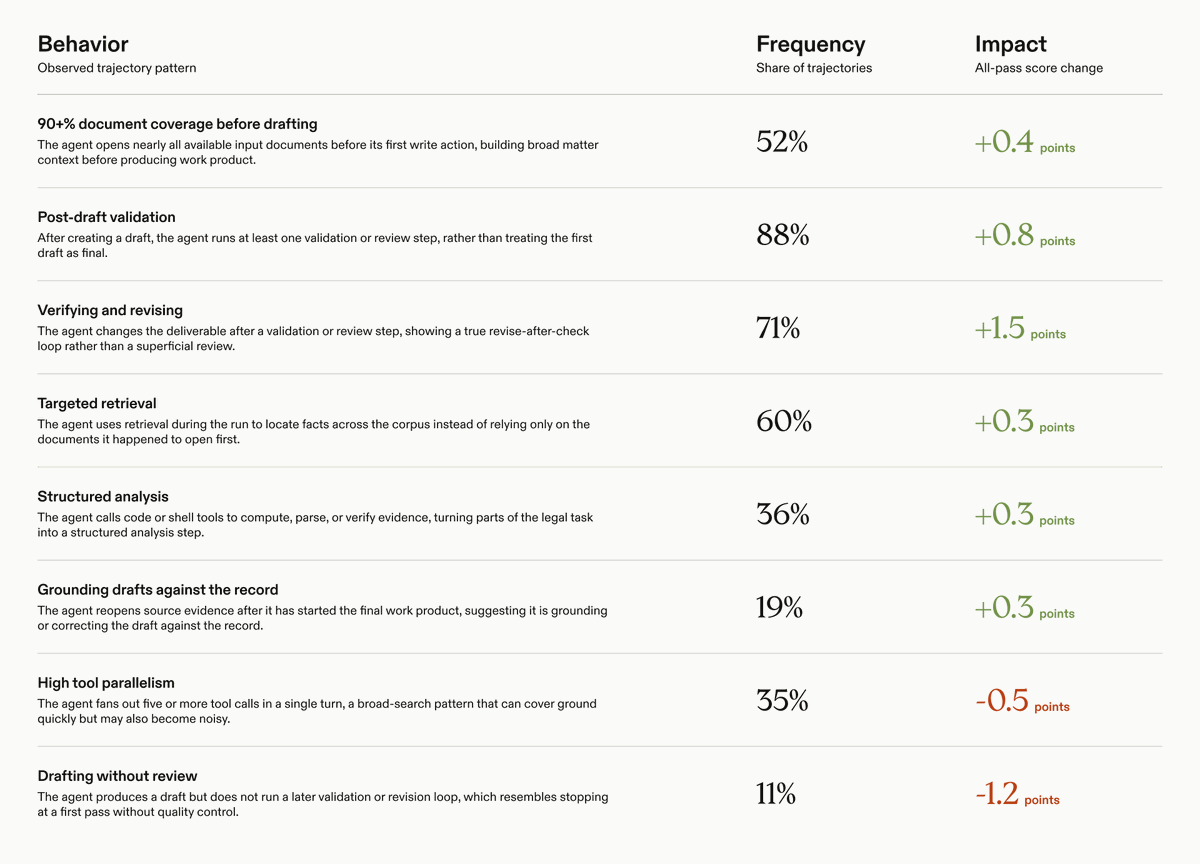
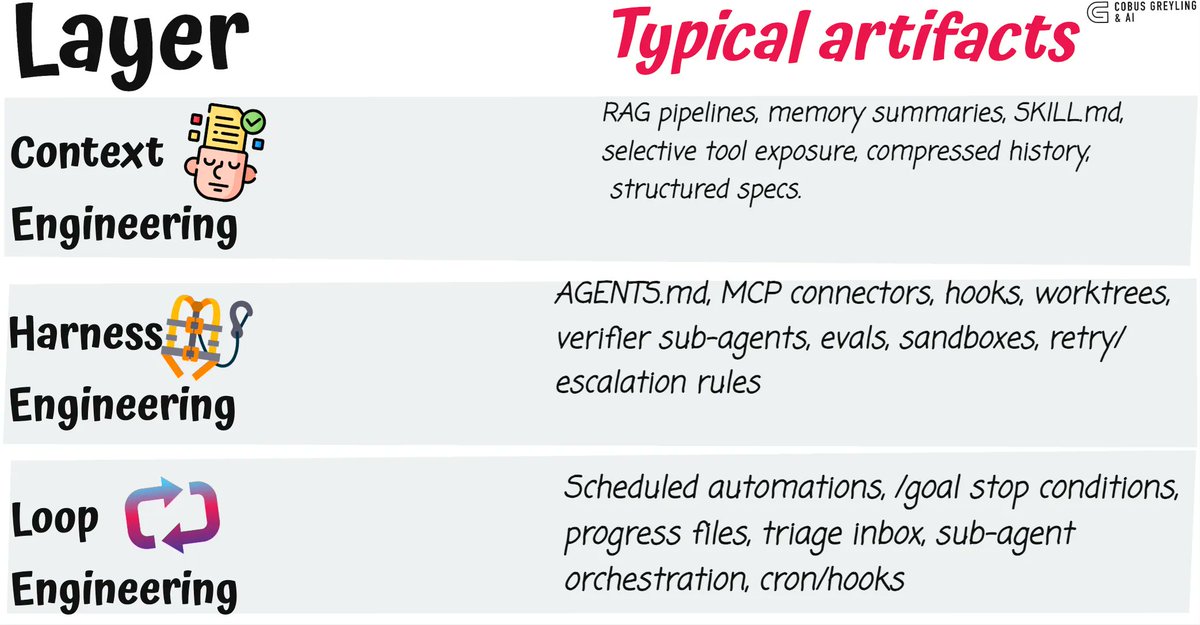
People call agents unreliable, but a lot of agent failures are product failures.
The task was too broad, tools had vague contracts, permissions were loose, and nobody defined what "stop" means.
English
Devayush Rout
265 posts

@devayushrout
Building production AI systems. RAG, evals, agents, LLMOps, document AI. Sharing traces, failure modes, and shipping notes.