고정된 트윗
Lucebox
26 posts




Open heart RTX 3090 surgery on @ivanfioravanti's Zotac card.
The card was very old and was easily hitting 90 C under load. Original pads were baked, and paste turned to dust.
We're switching the thermal interface and will send him full pre and post benchmarks after the operation.
For this we're using @Thermal_Grizzly phase-change pads on the GPU core, non-conductive and rated to hold forever. Fresh pads on the memories.
Doing this work on every single @luceboxai machine we produce.

English
Lucebox 리트윗함

Lucebox 리트윗함
Scrapped 500+ issues and PRs to ship a massive @luceboxai repo redesign and fixes. Very proud of the team.
github.com/Luce-Org/luceb…
The fastest inference server isn't going to come from a datacenter, it's going to run on the GPU already in your house.

English
Lucebox 리트윗함
@luceboxai is not affiliated with any cryptocurrency or coin, and we’ll never be.
English
Lucebox 리트윗함

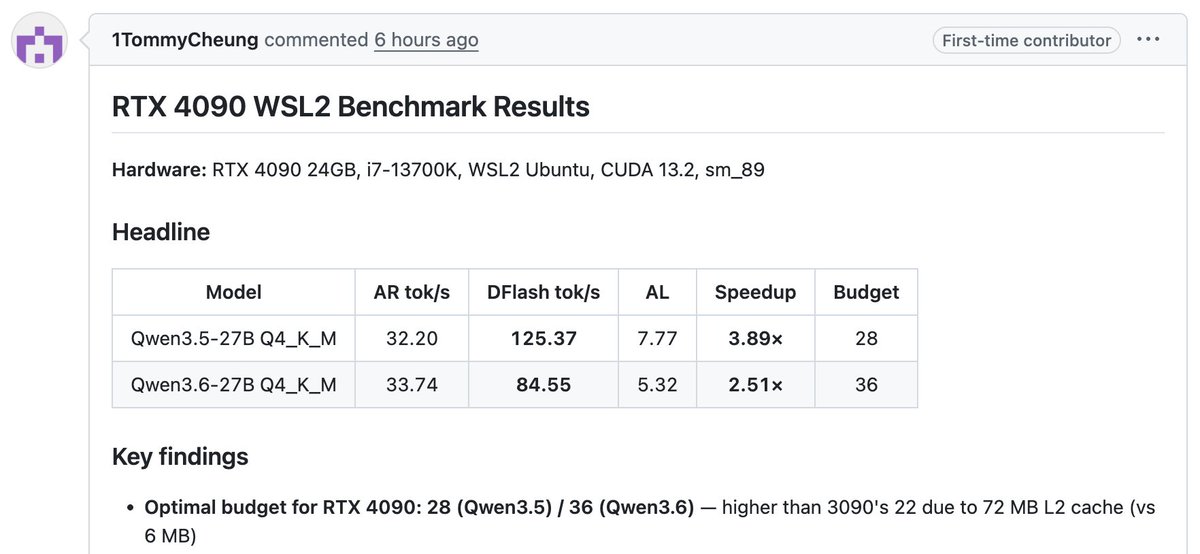
If you have an Nvidia RTX 4090 --ddtree-budget 36 is the best configuration that buys you 2.5x speed up during decoding for Qwen3.6_27B. Thanks for the benchmark github.com/1TommyCheung 🙌
English
Lucebox 리트윗함
Thanks to @csujun now @luceboxai server supports Gemma4! Pretty good speed up with quantized DFlash drafters to make everything fit in 24GB of VRAM. At the same time tool calling gets a 1.5-1.7x boost in every supported harness 🏎️🏎️


English
Lucebox 리트윗함
Very important work from @huggingface.
Mapping what the community is running matters for us at Lucebox too: it shows where our help is most needed.
I was surprised to see so many RTX 3060s. Also cool to see @julien_c is a 3090 fan as well!

Julien Chaumond@julien_c
What hardware actually powers open-source AI? Not benchmarks. Not vendor marketing. Real-world community usage. We’re launching @huggingface Hardware: → trending GPUs & CPUs → VRAM distribution → inference hardware trends → what the OSS AI ecosystem really runs on
English

Lucebox 리트윗함
Testing and UX should be first-class priorities for our inference engine.
We just added Lucebox harness launchers so users can run Lucebox directly from tools like Hermes, Codex, Pi, OpenClaw etc.
Each harness includes RTX 3090-safe starting settings to avoid OOM. We’ll keep improving them with community benchmarks and contributor feedback. 🏎️
github.com/Luce-Org/luceb…

English
Lucebox 리트윗함
We didn't know that our megakernel could be 25x faster than Pytorch on a RTX A6000 wow! 🏎️🏎️
Fahd Mirza@fahdmirza
⚡ Luce Megakernel just proved the NVIDIA efficiency gap is a software problem not a hardware one 🔬 a 2020 RTX 3090 at 220W now matches Apple M5 Max efficiency and delivers 1.8x the throughput 🔹 413 tok/s decode vs 267 tok/s on llama.cpp — same GPU, different software 🔹 1.87 tok/J — matching Apple M5 Max at less than a third of the system cost 🔹 All 24 layers of Qwen3.5-0.8B fused into a single CUDA kernel — zero CPU round trips 🔹 25x faster than PyTorch HuggingFace on the same hardware 🔹 Hybrid DeltaNet and Attention architecture — the first megakernel ever built for this pattern 🔥 Full breakdown and live benchmark below 👇 youtu.be/e6jY4goVIu0
English
Lucebox 리트윗함

ok this is sick
@pupposandro @davideciffa and @luceboxai got Laguna XS.2 running on a single RTX 3090 with ~111 tok/s decode, 5.4x faster 128K prefill vs llama.cpp, and made it the first MoE target for PFlash
open weights doing open weights things
English
Lucebox 리트윗함

Update on @luceboxai OOMing with Hermes Agent on RTX 3090:
@davideciffa gave me a great suggestion this morning to try with Lucebox and I am happy to report that it works!
Here are the settings to make it work with Hermes Agent on RTX 3090:
DFLASH27B_KV_TQ3=1 DFLASH27B_PREFILL_UBATCH=128
python3 scripts/server.py
--tokenizer Qwen/Qwen3.6-27B
--port 8000
--max-ctx 65536
--fa-window 1024
--prefix-cache-slots 1
--budget 8
--daemon
This *also* works with @DJLougen Ornstein model!
Really looking forward to testing this out! Thank you David!
This is one of the most exciting projects in local AI right now!
English
Lucebox 리트윗함
Lucebox 리트윗함

Lucebox 리트윗함
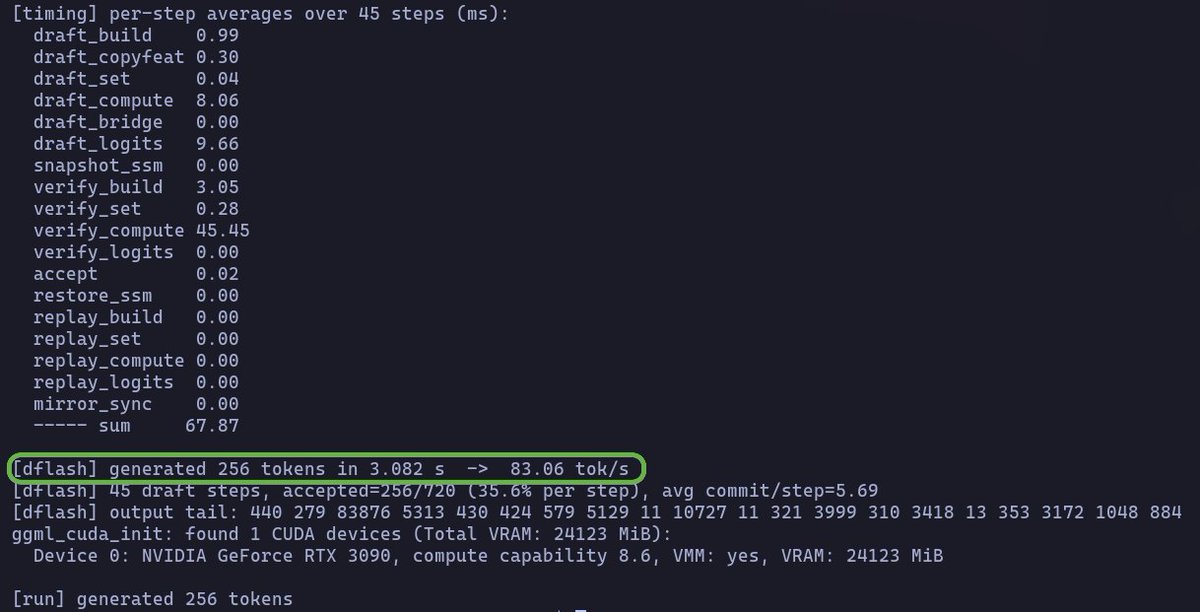
Testing @luceboxai ddtree + dflash on the RTX 3090 (Lenovo P920 beast machine)
83 tokens/sec on a single card with Qwen3.6-27B 🤯🤯🤯
This is wild!
English
Lucebox 리트윗함