Sabitlenmiş Tweet

Apollo
3.6K posts

@0xApolloGL
Head of Intelligence | @0xGroomLake... opinions are my own.




ICE and Border Patrol are significantly less white than America at large. Border Patrol is majority Latino!




Cuadra por cuadra... tardará un poco, pero quedará hermoso.

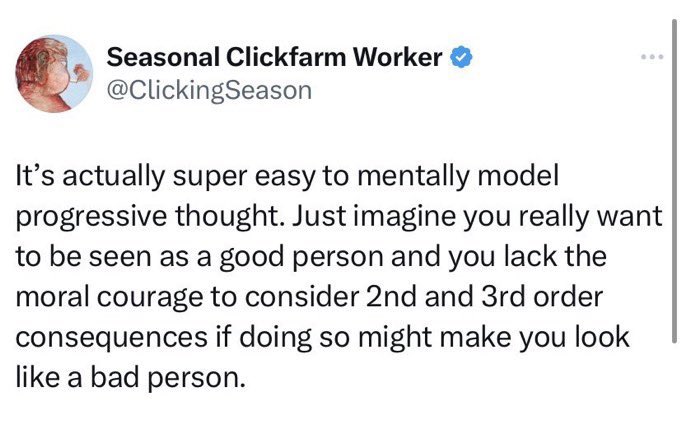
@edwest After a decade in the public sector I still find this one of the most replicable observations ever made.

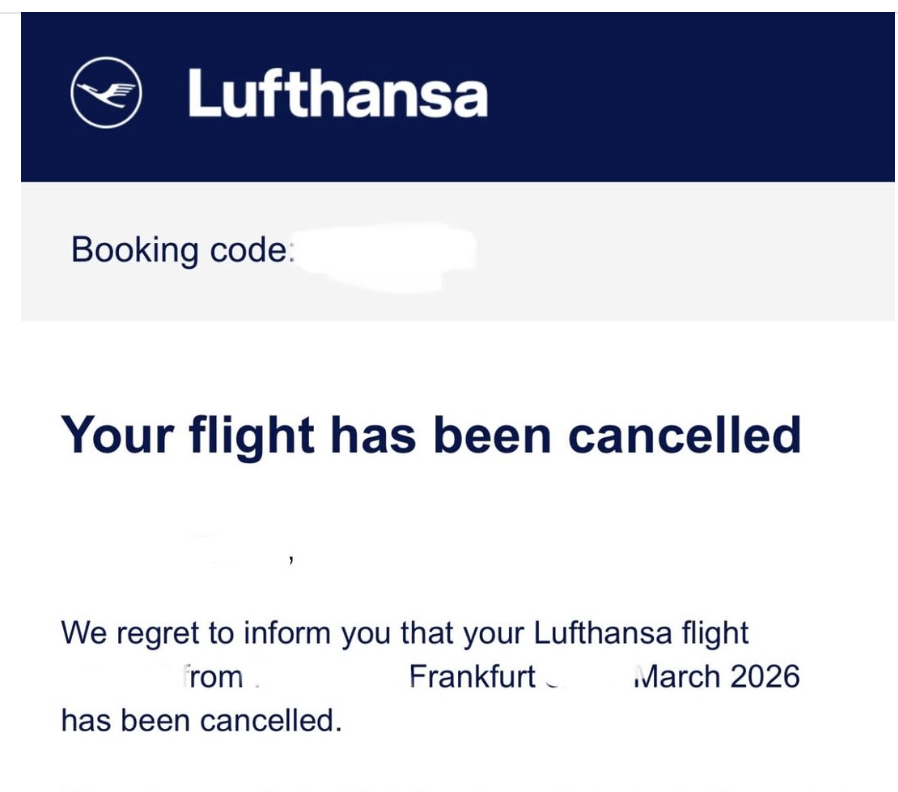
@lufthansa @0xRacist so you hate jewish people?








If someone argues that a former promiscuous woman is "damaged goods" and questions whether a Christian young man should marry her, remember Rahab. She was a Canaanite prostitute but became a mother in the lineage of Jesus. God redeemed her, cleansed her, and Salmon married her.


Isofix killed the 3 child family





PSA: If you have multiple macbooks that support RDMA, you can cluster them using @exolabs and run 30B+ models at 70 tok/s over thunderbolt5. tensor parallelism on consumer hardware is a solved problem. you are renting GPUs that are worse than the laptop on your couch. 2X M4 Max(64GB each) running mlx-community/Qwen3-30B-A3B-4bit @ 70 TPS

🚨 BREAKING: Tencent has killed the “next-token” paradigm. Tencent and Tsinghua has released CALM (Continuous Autoregressive Language Models), and it completely disrupts the next-token paradigm. LLMs currently waste massive amounts of compute predicting discrete, single tokens through a huge vocabulary softmax layer. It’s slow and scales poorly. CALM bypasses the vocabulary entirely. It uses a high-fidelity autoencoder to compress chunks of text into a single continuous vector with 99.9% reconstruction accuracy. The model now predicts the “next vector” in a continuous space. The numbers are actually insane: - Each generative step now carries 4× the semantic bandwidth. - Training compute is reduced by 44%. - The softmax bottleneck is completely removed. We’re literally watching language models evolve from typing discrete symbols to streaming continuous thoughts. This changes the entire trajectory of AI.