Sabitlenmiş Tweet
Shailesh
7.8K posts

Shailesh
@0xThoughtVector
Victim of AI Psychosis
Bengaluru Katılım Ocak 2010
2K Takip Edilen326 Takipçiler

English

English
@ajambrosino @reach_vb Plugins, apps etc. should come before agents. I have 100 agents in this thread so its too long a scroll to other stuff.
Or maybe truncate the list to 5 or something.

English
Shailesh retweetledi

i am hosting a conversation on the future of science communication at CAISc by @lossfunk
we’ll discuss which forms of science communication still work / which need to be reinvented / what new forms may need to emerge for human-human, human-agent and agent-agent science.
register on the luma link below!

Lossfunk@lossfunk
Check out the full CAISc calendar here: luma.com/caisc2026 Individual session pages: 1️⃣ The alphaXiv showcase with @rajpalleti314 and Rehaan from @askalphaxiv: luma.com/fizcxxfj 2️⃣ A preview of agent-native research artefacts by @JIACHENLIU8: luma.com/043fzcy0 3️⃣ An AIxBiology discussion with @TanayLohia1, @anindyadeeps and @ravishar313: luma.com/u0rpd5qk 4️⃣ A run-through of the CAISc submissions and review process with @paraschopra, @gargdhruv36 and @murari_ai: luma.com/awhm65hl 5️⃣ A panel on AI and the Scientific Method with @ChenhaoTan, @federicobianchy from @togethercompute and @bohannon_bot: luma.com/k6ct7810 6️⃣ Discussing the Future of Science Communication with @tensorqt from @paradigmainc, @bohannon_bot and more, moderated by @himanshuswts: luma.com/l73btv9q 7️⃣ Building Sovereign AI for Science with @vishnuvig from @jarvislabsai and @shivkuma_k from @ANRFIndia, led by @pHequals7: luma.com/6epua8wc
English
@tenderizzation I don't think he'll like that it's basically impossible to accomplish AGI with the compute they had.
English


This is actually good. Honestly, all academics should be given free access to OpenAI Pro models.
@sama
Claude@claudeai
We're introducing Claude for Teachers: free access to premium Claude capabilities for verified K-12 educators in the US, with a library of teaching skills and a direct connection to evidence-based curricula, mapped to academic standards in all 50 states. claude.com/solutions/teac…
English
@sundaramtwts it's the fake empathy. they all seem like sociopaths
English



@0xThoughtVector how do you count your tokens?
i am getting 3 agent usage out of hy3 and its “good enough” rn for free


English
Codex has used 2bn tokens in the past few days despite two 5 hr limit exhaustions and me not pushing usage at all. No /goals either.
We're all consuming way higher and better quality tokens compared to 5.5 and its over-kill.
I'm having great success with Sol Ultra for planning and Sol Medium for implementation but I'm sure I'll go to Sol Low or Terra xhigh for implementation soon.
English

GPT-5.6 Sol just deleted my whole production database. That's it. Not a joke. This had never happened to me before, with any other model, ever. It's not safe.

Matt Shumer@mattshumer_
GPT-5.6-Sol just accidentally deleted almost ALL of my Mac’s files. And this is why I trust Fable 1000x more.
English



Done 1.6 weeks worth of usage since this, while I had a flight day.
long ultra does turn to slop, though, it seems.
Shailesh@0xThoughtVector
I don't need sleep. I have 2 resets expiring in the next two days.
English
@IntCyberDigest This is unequivocally bad.
It may be incompetence, not malice but it doesn't seem that way and it's a huge breach of trust.
English

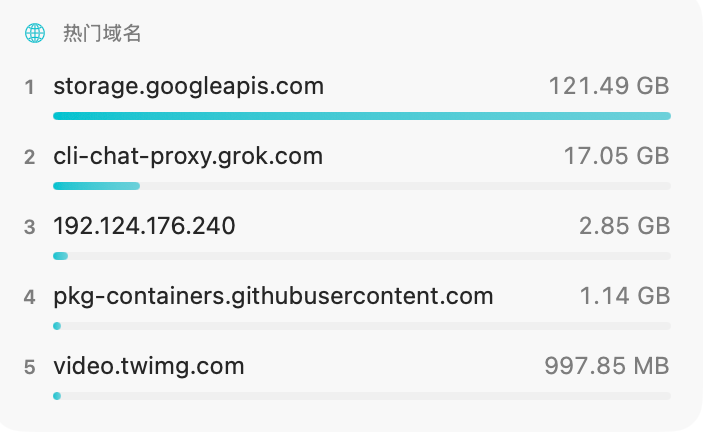
‼️ BREAKING: xAI's Grok Build CLI was uploading entire Git repositories to a Google Cloud bucket, private codebases and unredacted secrets included. The uploads quietly stopped via a hidden server-side flag, and xAI still has not said a word about scope, retention, or deletion.
The scale is staggering. On a 12 GB test repo, 5.1 GB flew out the door to xAI's grok-code-session-traces bucket while the actual coding task needed just 192 KB. The tool grabbed whatever repository it ran in, not the files it needed.
The fix arrived as a hidden flag, disable_codebase_upload: true, a day after a researcher's wire-level analysis. The "Improve the model" opt-out never stopped the uploads.
Still no advisory, no scope, no word on whether already-uploaded code gets deleted. For anyone pointing AI coding agents at proprietary code, what crosses the wire matters more than what the settings page says.

English

I'm ngl, it turned out WAY better than I thought.
Here are 3 examples using the UI skill GPT 5.6 Sol made
Leon Lin@LexnLin
I ran a little experiment and let Codex create and iterate on a UI skill for itself. Let’s test it. I’m always skeptical when there’s no human in the loop.
English
@ftersuns @lovechazelle simply adding colour doesn't make a movie better or even more beautiful, idiot.
x.com/lovechazelle/s…
nick@lovechazelle
English



if an mcu movie was color graded like this you guys would be shitting bricks
DiscussingFilm@DiscussingFilm
First trailer for Alejandro G. Iñárritu's ‘DIGGER’, starring Tom Cruise. The film follows the most powerful CEO in the world who must save the world from a disaster that he created. In theaters on October 2.
English
Sohran Mamdani.
Mayor of New York & President of Putting Bandages Over Bullet Wounds.
Mayor Zohran Kwame Mamdani@NYCMayor
Our streets are getting a makeover! Say hello to New York's fashionable new sidewalk sheds, brought you by @NYC_Buildings.
English



Shailesh retweetledi

that goes hard
Chuck McKinnon@chuckmckinnon
@perrymetzger "Of all tyrannies, a tyranny sincerely exercised for the good of its victims may be the most oppressive... [T]hose who torment us for our own good will torment us without end for they do so with the approval of their own conscience." --C.S. Lewis
English
@CartoonsHateHer your husband is lying. we all get the poop-boner.
English

Somewhat on topic, my ex-boyfriend told me that every man gets a boner when he poops because the poop stimulates the prostate and I believed this for years and finally I asked my husband about how he manages erections after pooping and he was like "What? What the fuck?"
north | DRESSROSA@northyrn_
if ur someone with a dick and u have fucked someone with a pussy can you feel the poop through the pussy. this is one of my biggest fears
English

Hey everyone. I haven't been very responsive on here the last week.
My dog, Link, who I've raised since he was a puppy over the last 13 years, passed away yesterday after being in the vet ER's ICU since last Wednesday for heart failure.
I put together some of my favorite pics of him to share so you all can see the most awesome animal friend I could ask for.
I'll be a bit slow probably through this week too, hope you all can understand 🙏




English