Sabitlenmiş Tweet
🐚xtotem
1.4K posts


🐚xtotem
@0xtotem
9 years of ai ml deep-learning formerly @immunefi, @code4rena dms are open
ai ∩ web3sec Katılım Şubat 2021
952 Takip Edilen1.2K Takipçiler

🐚xtotem retweetledi

I like blockchain tech quite a bit because it extends open source to open source+state, a genuine/exciting innovation in computing paradigms. I'm just sad and struggle to get over it coming packaged with so much braindead bs (get rich quick pumps/dumps/scams/spams/memes etc.). Ew
English
🐚xtotem retweetledi

🧵1/ A single neuron is sufficient to bypass safety alignment in LLMs.
Across 7 models, 2 families, and scales from 1.7B to 70B, suppressing one MLP neuron bypasses refusal behavior — with no fine-tuning and no prompt engineering.
We call them refusal neurons.
We also study concept neurons: neurons that encode harmful knowledge itself. As a proof of concept, we identify suicide-related neurons. Our analysis reveals several interesting results⬇️
Joint work with @AtoosaChegini (equal contribution) , Maria Safi

English
It's the end of an era. C4 was the first web3sec company I ever heard of and contributed to.
Grateful for the good times and the chance @sockdrawermoney gave me to work alongside such inspiring people:
@_0xsi @geooooodude @trebienxyz @CloudEllie1 @itsmetechjay @realfakepicnic
Code4rena@code4rena
After careful consideration, we’ve made the decision to wind down @code4rena. This community has meant a great deal to everyone who has been part of building it, and sharing this news is not easy.
English
🐚xtotem retweetledi

We set out to build a better retriever, so we looked for the hardest IR benchmarks.
For each, we asked how much headroom remained by running oracle reranking with a frontier LLM. Most had little room left!
So we built OBLIQ-Bench to study much harder search queries than before.
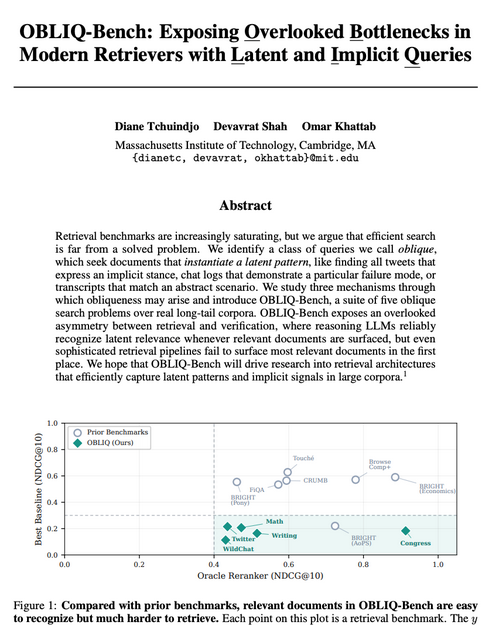
English
🐚xtotem retweetledi

After almost five years, I'm no longer at @immunefi
I built and led the Managed Triage Service from the ground up. Hired the team. Wrote the playbooks. Triaged thousands of vulnerability reports and helped mediate one of the largest payouts in the history of Web3 security, and plenty more behind closed doors.
I'm proud of what we built and grateful to everyone I worked with.
Now I'm looking for what's next.
I'm looking for a leadership position in security. Joining an existing team, or building one from zero. Triage, bug bounties, Web3 security, or anything that helps secure a project or the wider org.
I'm also open to consulting. Helping teams spin-up an internal security function, or advising on what a project actually needs, especially on the internal side. I know how to run triage that's operationally efficient and doesn't miss the false negatives that matter.
If you're hiring or know someone who is, I'd like to hear from you.
My DMs are open
GIF
English



@SakanaAILabs's recursive agent orchestration
and @a1zhang's recursive language models, both boosting performances through recursion reminds me about this nice tinfoil hat theory:
frontier LLMs are already smart enough
we just don't know how to use them
x.com/a1zhang/status…
alex zhang@a1zhang
English
🐚xtotem retweetledi

“There Will Be a Scientific Theory of Deep Learning”
This paper argues that a real scientific theory of deep learning is beginning to emerge.
Not a theory that tracks every neuron individually, but a physics-like theory of learning itself. One that aims to characterize how training dynamics, representations, weights, and performance evolve.
It reframes deep learning theory from abstract guarantees and trial-and-error practice toward falsifiable, quantitative predictions about real systems.

English

🐚xtotem retweetledi

Both DSPy and (especially) GEPA are currently severely under hyped in the AI context engineering world
English
🐚xtotem retweetledi

The idea of training LLMs to manage their own KV cache is super interesting to me. The recent neural garbage collection (NGC) paper was a great read on this topic.
Reasoning models / agents obviously need long sequences to handle complex reasoning, long horizon tasks, tool calls, etc. However, the size of the KV increases linearly with the length of your sequence, creating a KV cache bottleneck.
To solve this, there are several heuristics that have been proposed; e.g., only keeping recent tokens, keeping tokens with high attention scores, etc. But these heuristics tend to degrade performance and may or may not work well depending on the domain / task.
Instead of using heuristics, we can try to teach the LLM to manage its own KV cache. Concretely, NGC does this by implementing an eviction cadence. Every δ tokens during the decoding process, NGC scores all of its KV cache blocks and defines an eviction rate ϵ such that only (1 - ϵ) of KV cache blocks are kept. By doing this, we can ensure that the peak cache size is stable.
To score KV cache blocks, NGC does not use any new or specialized models / modules. Instead, it repurposes the LLM's existing attention mechanism. The model takes the most recent query vectors, partitions KV cache into fixed-size blocks, then scores previous keys based on the query vectors.
Instead of performing specialized training for managing the KV cache, NGC simply incorporates KV cache management into the verifiable loss for training with RL / GRPO. The RL objective both has both:
1. A component for normal token predictions.
2. A component for KV cache eviction decisions.
This way, we can train the model end-to-end with RL to correctly evict KV cache blocks (similarly to predicting a token) while still using outcome rewards.
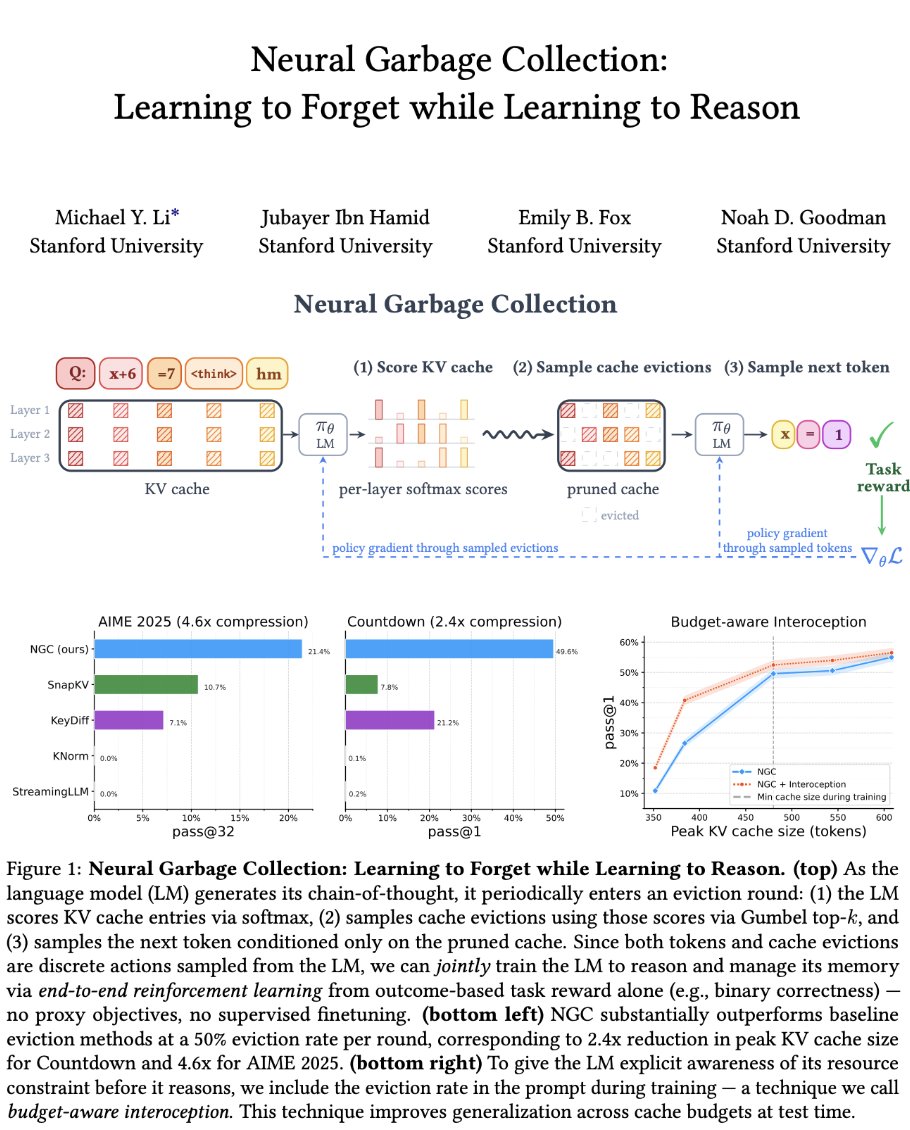
English

Hari@hrkrshnn
The benchmarks that they're putting out are unreliable. There are recipes out there to tune a model to hill climb any public benchmarks. A lot of models will regurgitate solutions if you just ask anything remotely close to one of the problems in the benchmark. The best way to evaluate is to have internal problem sets that you know deeply about and are not public, and see how different models perform on that. The #1 model on the coding benchmark is not the best coding model for quite a while. Good luck figuring it out!
ZXX
🐚xtotem retweetledi

We collaborated with researchers at Stanford, Imperial College, and the Internet Archive to investigate public perception of AI's prevalence on the internet.
In 2025, 35% of newly published websites on the open internet were AI-generated or AI-assisted. Internet users are overwhelmingly cynical about this: 75% of people polled felt that an AI-dominated internet will be less accurate, and 83% believed that AI will collapse unique writing style into a monoculture.
AI is shrinking the diversity of views online, and as AI content proliferates, online writing also becomes artificially cheerful: the average positive sentiment score for AI-generated and AI-assisted documents was 107% higher than for non-AI websites.
AI-generated text has the potential to erode trust in the primary way we access information. It's clear that the proportion of the internet that is AI generated is only going to increase, and could exceed 50% by 2027.
We're concerned about this problem and proud to have contributed to this research. The study, "The Impact of AI-Generated Text on the Internet", is now available as a preprint, linked below.
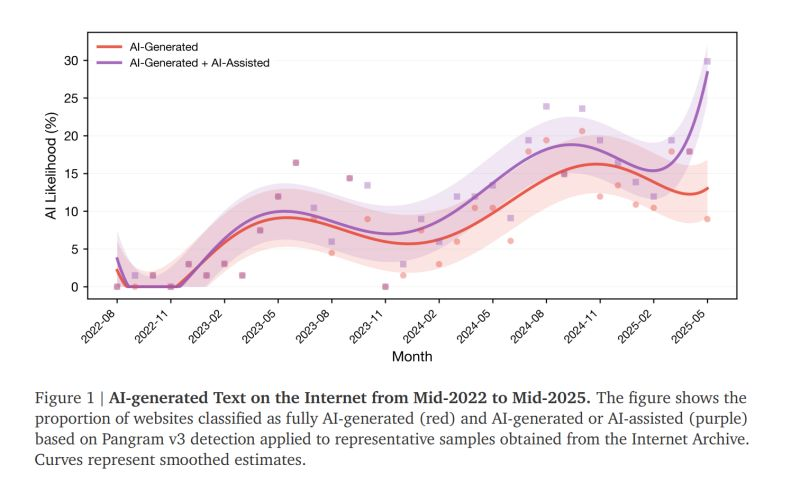
English
🐚xtotem retweetledi

Can LLMs flip coins in their heads?
When prompted to “Flip a fair coin” 100 times, the heads to tails ratio drifts far from 50:50. LLMs can understand what the target probability should be, but generating outputs that faithfully follow a given distribution is a separate problem.
This bias extends beyond coin flips. When LLMs are asked to generate multiple story ideas or brainstorm solutions, the outputs tend to cluster around a narrow range. The same probabilistic skew that distorts coin flips limits diversity in creative generation, recommendations, and other tasks where varied outputs are needed.
We discovered a prompting technique named String Seed of Thought (SSoT). The method is simple: instruct the LLM to generate a random string in its own output, then manipulate that string to derive its answer. It requires only a small addition to the prompt and no external random number generator.
SSoT significantly reduces output bias across a wide range of LLMs, both open and closed. With reasoning models (such as DeepSeek-R1), it reaches accuracy close to that of actual random sampling. The method generalizes from binary choices to n-way selections and arbitrary probability distributions. On the NoveltyBench diversity benchmark, SSoT outperformed other approaches across all six categories while maintaining output quality.
This work will be presented at #ICLR2026!
Blog: pub.sakana.ai/ssot
Paper: arxiv.org/abs/2510.21150
Openreview: openreview.net/forum?id=luXtb…
GIF
English
@LakshyAAAgrawal @isaacbmiller1 I need to dig into the documentation to understand how to set the signature but that's a great idea thanks
congrats on Amazon's integration of GEPA btw 👏
English

@0xtotem @isaacbmiller1 You make the reflection LM support arbitrarily long contexts, a.k.a., you use RLM as the reflection LM. A recursive reflection LM!
English

DSPy.RLM has been getting more attention with the amazing benchmark results on LongCot by @rawworks.
The big structural advantage that dspy.RLM has over other RLM implementations is Signatures.
Signatures let the RLM be directed in the task that you need it to solve:
1. Inputs are separate, typed variables.
Instead of one giant string, you show the model a preview of the variables, and the Python types that they represent. It doesn’t need to do parsing or exploring to understand the structure of an input, only the content.
2. The model is required to conform to structured outputs
You require the RLM to finish a trajectory by using a typed submit function Instead of being able to submit any string.
This means that when you want the model to do a specific task, it can't just submit anything. It needs to submit values that conform to your type definition.
3. The instructions are directly in the context.
For solving a real task, you do don’t want the entirety of the prompt to be inside of a variable. You do want the long inputs to be in a variable, but shorter instructions don’t give you much benefit from being discovered rather than shown in the prompt.
Bonus: Your ReAct agent's tools become normal functions that your RLM can use inside the REPL.
I talked about these advantages at the last DSPy meetup. See my talk below!
English
MIT conducted a research on this subject, they noted: "Over four months, LLM users consistently underperformed at neural, linguistic, and behavioral levels. These results raise concerns about the long-term educational implications of LLM reliance..."
LonelySloth@lonelysloth_sec
You can’t have a lasting competitive advantage if LLMs are in your critical cognitive path. Whatever you do will be at best limited to the same capabilities and constraints as what everyone else is doing. You’ll find the same bugs as everyone else, build the nth clone of the same app, trade using the same strategy. Using an llm while keeping it out of the critical path isn’t easy. If your bug leads are LLM generated — you will be constrained by the bugs that can be found by LLMs. No amount of prompting or composition will give you more than a small margin over your competitors that tends to collapse to zero. If all your code is LLM generated you are constraining your product to the universe of code LLMs can write — which is the same code your competitors can easily write. Even adding human input and review doesn’t necessarily change the picture. No amount of context, human generated hints, or iteration, can force a model to produce something that diverges too much from it’s training data. The cost of doing something through an LLM scales exponentially as you move further away from sample. That’s not something the next model will fix. **It’s a mathematical necessity** Past a certain level of novelty making the model do the work requires more human mental work than just doing it yourself. But you take a long time to notice it, because the LLMs nudges you back to doing what it’s good at. For coding it just keeps writing something that isn’t exactly what you asked and you keep telling yourself it’s close enough. For finding bugs the cost shows up as not finding the bugs as the model keeps looking for typical vulnerabilities. For s bug hunter it means spending compute without revenue. For a protocol it can mean getting rekt. You have a brain evolved over millions of years with priors that match the real world in a way a statistical model of text cant. Your brain can legitimately extrapolate beyond what others thought in the past in a way that is impossible **even for an LLM with arbitrarily large compute power** Use it.
English