Sabitlenmiş Tweet
1i
248 posts



the entry ticket will keep falling
the capabilities will keep growing
bide your time, then buy cheap second hand (most enterprise/prosumer is -75% after 4-5 years). gets you 50~80% there in perf for 20~50% of the cost. thinkpads are the typical example for laptops.
silicon doesn't age, perfs stay good as new to the last day. just get good at servicing parts (cleaning with air duster + isopropyl alcohol, changing fans, repasting, etc).
i've mostly been freeloading on cheap enterprise refurbs since 2016 when discovering that trick. cuts your bill in half compared to new customer SKUs. no regrets, you just get better hardware (and skills) in the process.
English

@1i__is I live on the cloud but I long for dedicated hardware and open source LLMs..
English
this is the way
and it's only going to get better as GB capacity increases and models reqs decrease.
on-prems/MSP self-hosted is still how most SMBs want to operate for their most important data. big clouds are a no-no for mission-critical flows.
this is only the beginning!
Dee@dee_hw
On-Premise Business AI Center After my posts on the 2-GPU and 4-GPU builds, people reached out asking how to build an 8-GPU box for their businesses. Why? - Protect their IP - Protect customer data - Save on inference costs - Train their own models Here's how to build one: 🧵
English
@WhitepaperGrey they tried a bit with Windows Home Server (2007-2009) but that failed hard. you come with this when Apple is on the iPhone… FWIW Gates left in 2008. bad times at MS.
they should've tried in 2000. back then i had two PCs with one file serving, proxy, etc and it was glorious.
GIF
English
@1i__is Should have been a railway all along to sell consumers their own server farms. Microsoft and so many others never saw it coming.
English
been saying it for decades:
everyone should have a home server to perform whatever their needs are
now it includes GPUs for AI
(+ 3D/video processing for gaming etc.)
it's a neat way to get great private performance while thinning clients footprint (heat/noise & total bill).
the tiny corp@__tinygrad__
@APompliano We need stacks of GPUs in every house, not really big stacks of GPUs controlled by companies who are trying to extract value from us.
English
this is exactly what drives me too
i want to congratulate but above all **thank** you for making it this way.
it's like hope with substance, real-world proof that it can be done, and well.
it really makes a difference when i have doubts, second-guess it all.
like a good reality-check "i'm not hallucinating, so and so did it, are doing it, rn!"
and it's positively raw energy when i lock in. i get that from you and the few others who actually ship, write, share, sell, teach… whatever they call success. examples to follow are worth a millions words.
i wish you the absolute best (and to your family!), sincerely, you deserve it.
---
as for your beef with Ahmad, i won't be part of that but it's obvious there's too much divergence between you two (in style, goals, values…)
how to say… i'd never put you both on the roster haha.
it's ok too. if we all take good care of *our own* world (people, places, and things we love and know first-hand), then "the" world is a much better place and we don't even need to all get along for that.
have a great one
and KISS your 6000s for me 🤓🤖
English
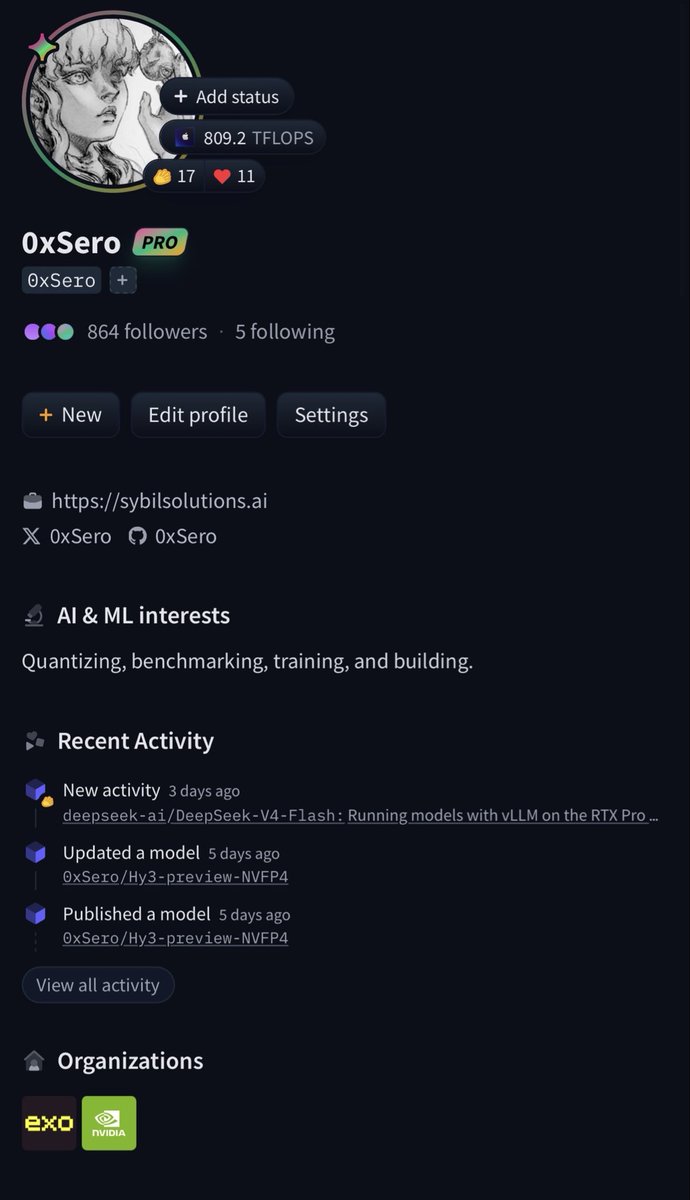

3 months ago I blocked this guy and he made such a scene about it that to this day people still ask me why.
The reason I did so is because despite him hyping me up, he’d constantly be writing about how I’m a larper.
Now my “larping” has resulted in:
- Meeting folks at Nvidia
- Meeting folks at OpenAI
- Working with Factory
- Teaching 1000s of people
100+ GitHub repos:
- day 0 deepseek-v4-flash on sm120
- best performance on Framework
- REAP-MLX + REAP-Strix
- VLLM-STUDIO nearly 1k stars
- GLM-4.6/4.7 on a MacBook
- Qwen-3.5-plus for 8x 3090s
- Parchi
- AI-data-extraction 1k stars
- First working turboquant on vLLM
4 months ago:
- Interned at a large AI company
- Produced 15+ models with 100k monthly downloads
- Created a discord server and taught nearly 1000 people for free (still doing it)
6 months ago:
- Released the first REAP quants
- Sponsored by Anthropic running Claude code Warsaw with 500+ attendees
- Trained nanochat at home
12 months ago:
- Built my first rag self hosting on a MacBook funny enough
- Spending 5-10k a month in tokens on random product buildings
18 months ago:
- Taught a 200 person course (for free) how to use AI for coding
24 months ago:
- Applied research for the Ethereum foundation on ZK proofs
- Built Rosetta Node a solidity <> English translator built on OpenAI
English

@1i__is haha deal 🤝 czech food + AI conversations is a dangerous combo.
English
As we keep growing, I want to better understand this little AI corner.
Where in the world are you building from? 🌍
English
if you know Rust, sure.
but it would be much harder for me to maintain code in Rust than in Python or Go for instance. the memory mgmt overhead is way too much for most trivial problems, there's a place for all levels of abstraction. Python and many languages like JS have C/C++ bindings under the hood, so fast enough.
i'm a big believer that the "best" language is the one *you* know that fits the job.
and that for most apps, unless you're hyperscaling or something, if your code is well-designed you will not notice the difference on modern hardware.
i don't see how LLMs make any difference except for vibe code, throwaways, things you need in passing but don't intend to maintain.
the worst would be using LLMs to write Rust because it's fast without any idea what the code does. i think the growth of the developer matters more at the end of the day for the app than choosing this or that tech/stack.
English

For the vast majority of software that people are writing, i don't see many excuses to use anything other than Rust.
wavefnx@wavefnx
Thought this was a joke 1mil lines Bun commit re-writing Bun in Rust They learned Bun is now officially the good side of history
English
@chimpansky well if we ever visit 🇨🇿,
i know who I'd gladly take out for a great dinner and a chat! :)
English
yeah the energy is awesome. haven't seen this since 1999 (literally), the early web era (and I was still a teen so this is much bigger to me).
AI has unleashed me, seals removed! i feel empowered enough to take on dream projects, problems i've been thinking for 10 or 20 years… with tech that was sci-fi 5 minutes ago… it's so cool and so inspiring.
English
@1i__is 🙏 this is honestly one of the coolest parts of this whole AI wave.
people aren’t just building products. some are genuinely trying to build a different life through it.
English
@Snixtp 24 tok/s each is really awesome at that concurrency!
this ties back to a chat i've had earlier about a hypothetical shared b300 node, but your numbers seem to hint at more Blackwell or Qwen optimizations than paper suggests
so many things to test!
x.com/i/status/20548…
Adam Louly@LoulyAdam
So to give you a detailed and very close number i'd have to dig into the architecture more, see how much kv per token holds and weights, I'll make a general rule of how to approach that, and you can refine it if you dig more into the model specs. So the amount of concurrent users relies heavily on how much memory you have left for kv cache, so you'd need to compute how much memory we're allocating for fixed stuff and how much left for kv for example if we're lets say kimi for example fp8, to make math easy let's do 1T x fp8 = 1TB will be allocated for the weights. for int4 or nvfp4 it would be 520GB activation workspace you'd need like 20-30gb, this is usually relies on your max prefill batch possible you just multiply batch tokens x hidden dim x fp8 or fp16 activation x number of intermediate tensors. keep like 2% for cuda overhead, another 4% for safety margins and you're left with like 1.2TB of memory for KV example with MHA, MLA is much much more efficient maybe less than 10% of this number for MHA compute kv per token =2 x n layers x num heads x d_model x fp8 = 1mb (for easy math). now you can get a sense of how many concurrent users if you have 1.2 tb left for 128k context its like 128GB per user so you'll be able to serve 10 concurrent users 1m you'll be able to serve a single user. with MLA ratio is 10x give or take so 100 users with 128k users and 10 users with 1m context. keep in mind that this is the laziest calculation, I just rounded everything up for easy math, depends on SLAs you could serve way more than this, but maybe with slower TBT.
English

@LoulyAdam @MainzOnX thank you sooo much for this detailed answer! this really helps a lot!
i'm gonna study this deeper :D
English

So to give you a detailed and very close number i'd have to dig into the architecture more, see how much kv per token holds and weights, I'll make a general rule of how to approach that, and you can refine it if you dig more into the model specs.
So the amount of concurrent users relies heavily on how much memory you have left for kv cache, so you'd need to compute how much memory we're allocating for fixed stuff and how much left for kv
for example if we're
lets say kimi for example fp8, to make math easy let's do 1T x fp8 = 1TB will be allocated for the weights.
for int4 or nvfp4 it would be 520GB
activation workspace you'd need like 20-30gb, this is usually relies on your max prefill batch possible you just multiply batch tokens x hidden dim x fp8 or fp16 activation x number of intermediate tensors.
keep like 2% for cuda overhead, another 4% for safety margins and you're left with like 1.2TB of memory for KV
example with MHA, MLA is much much more efficient maybe less than 10% of this number for MHA
compute kv per token =2 x n layers x num heads x d_model x fp8 = 1mb (for easy math).
now you can get a sense of how many concurrent users if you have 1.2 tb left
for 128k context its like 128GB per user so you'll be able to serve 10 concurrent users
1m you'll be able to serve a single user.
with MLA ratio is 10x give or take so 100 users with 128k users and 10 users with 1m context.
keep in mind that this is the laziest calculation, I just rounded everything up for easy math, depends on SLAs you could serve way more than this, but maybe with slower TBT.
English

If you had access to a gb300 server rack right now what are you building with it? Would you know where to start?
English
yeah of course :)
for now it's really just a thought experiment. but i may turn it into a real experiment with rentals first to test the waters, a PoC. maybe this year or 27.
the big LLM case would be something like Kimi K2.6 in FP8 (both weights and kv) at max context (256k).
Or even DeepSeek V4-Pro (FP8, weights 1.6T, 49B active, up to 1m ctx lol)
(HF links below)
workload would be partially decided by performance i guess.
if people can hammer it 24/7 with lots of agents then cool.
but at the baseline it's typical "manual" LLM usage, with as much batching as possible for things that can wait.
the goal is to minimize idling as usual, and it may influence what kind of workload and crowd to spec such a project for.
there are so many variables left to test, so the guesstimate has to be very fuzzy, that's my problem :D i'm fishing for expertise tbh, if only to learn the problem.
lots of experiments needed to optimize. and with a tiny userbase, it won't be smooth 24/7. a bit more scale would surely help make UX really better. but baby steps, right? :D
#model-downloads" target="_blank" rel="nofollow noopener">huggingface.co/deepseek-ai/De…
#2-model-summary" target="_blank" rel="nofollow noopener">huggingface.co/moonshotai/Kim…
English
It would not be informal if I were to just answer from the get go :)) many things contribute to that, I’d want to know the size of the model how many active
Moe params, weights dtype we’re using, kv cache dtype, which serving optimizations we’re having, workload type etc… before I can give a guess (and it still won’t be a perfect guess)
English


@LoulyAdam @MainzOnX Right? :D
Also, given your exp with inference, I can't resist to ask:
I'd be super interested in your ballpark/napkin/informed guesses for the kind of concurrent userbase you can serve with such an 8x node. I've no idea personally…
English
thanks for asking!
i've replied in the main (quoted) thread. the gist is:
100%. You learn to code for the thinking.
- Code is notation for thought.
- AI is a lever: it applies force in whatever direction you choose.
So our job is to choose well and learn so we can choose better next time.
Vibe coding feels productive but often isn't: absorption without growth. The bottleneck was always cognition, not typing. It still is. Understanding compounds; AI can't shortcut that. If you outsource the thinking, you stop upskilling.
Learn to code because it makes you a better thinker. The tool just amplifies *you!* : )
English
ai can write code, but you still need to know what good looks like, where it’s likely wrong, and how to debug when the happy path breaks.
Interested what are your thoughts @1i__is @henrytdowling @PalmsBurnt @DanielSmidstrup
Chimpansky@chimpansky
be honest: if AI writes most of the code now, is learning to code still worth it? • yes, fundamentals still matter • only enough to direct AI • no, product thinking matters more • I never really learned curious how people actually think about this long term. P.S. my real answer is hidden somewhere in the image, can you find it? 👀 vote or drop your take below. 👇
English
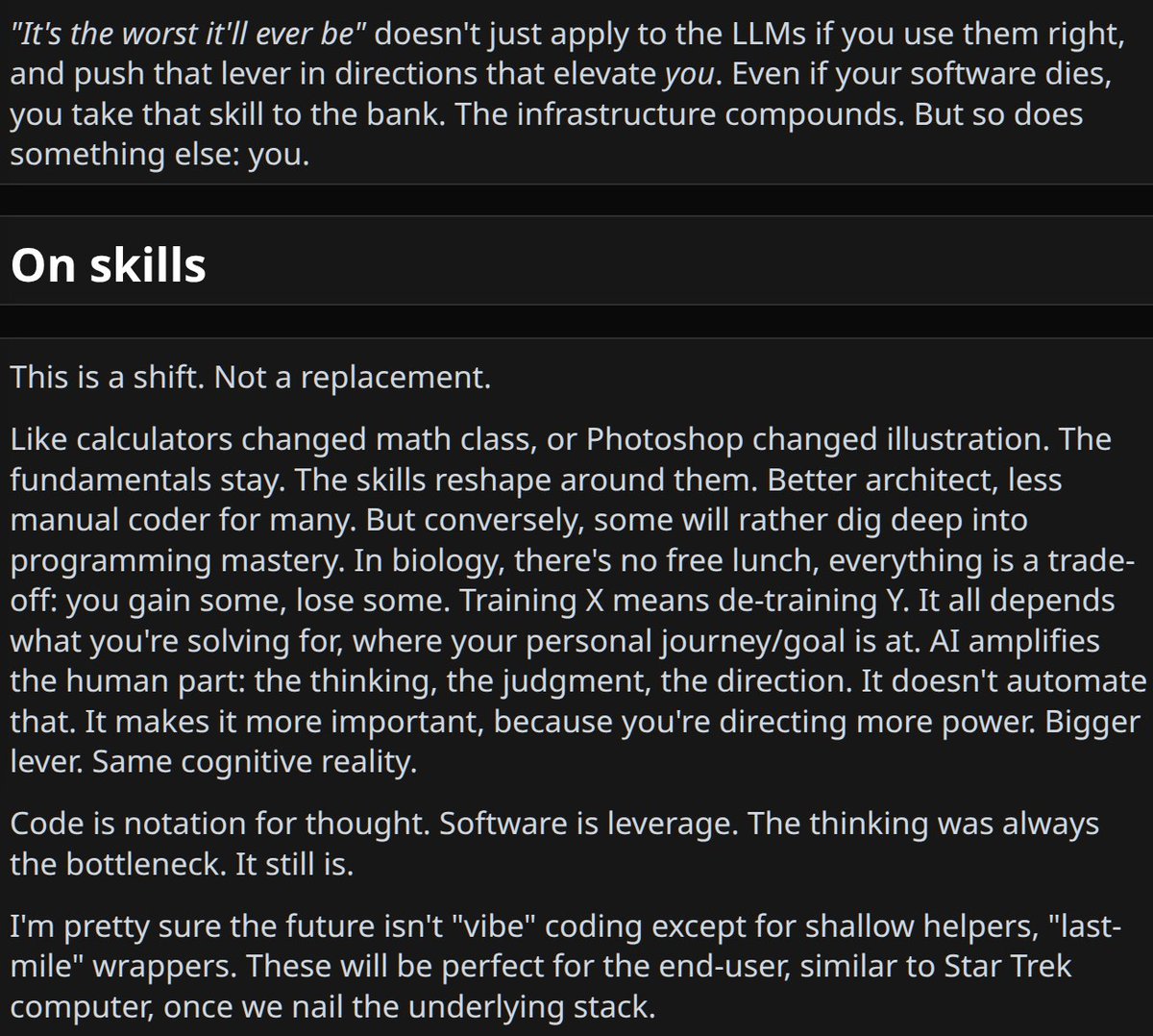
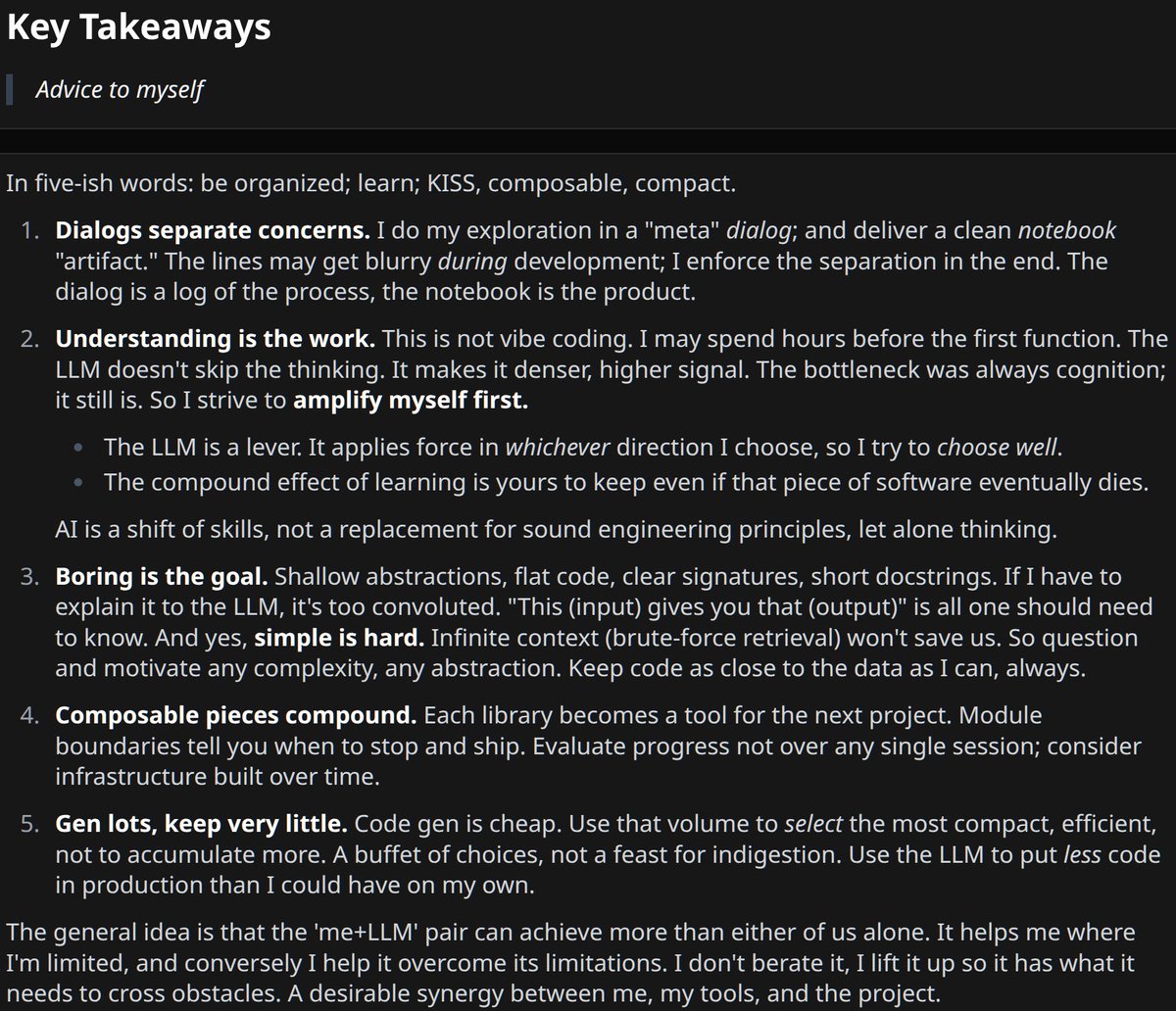
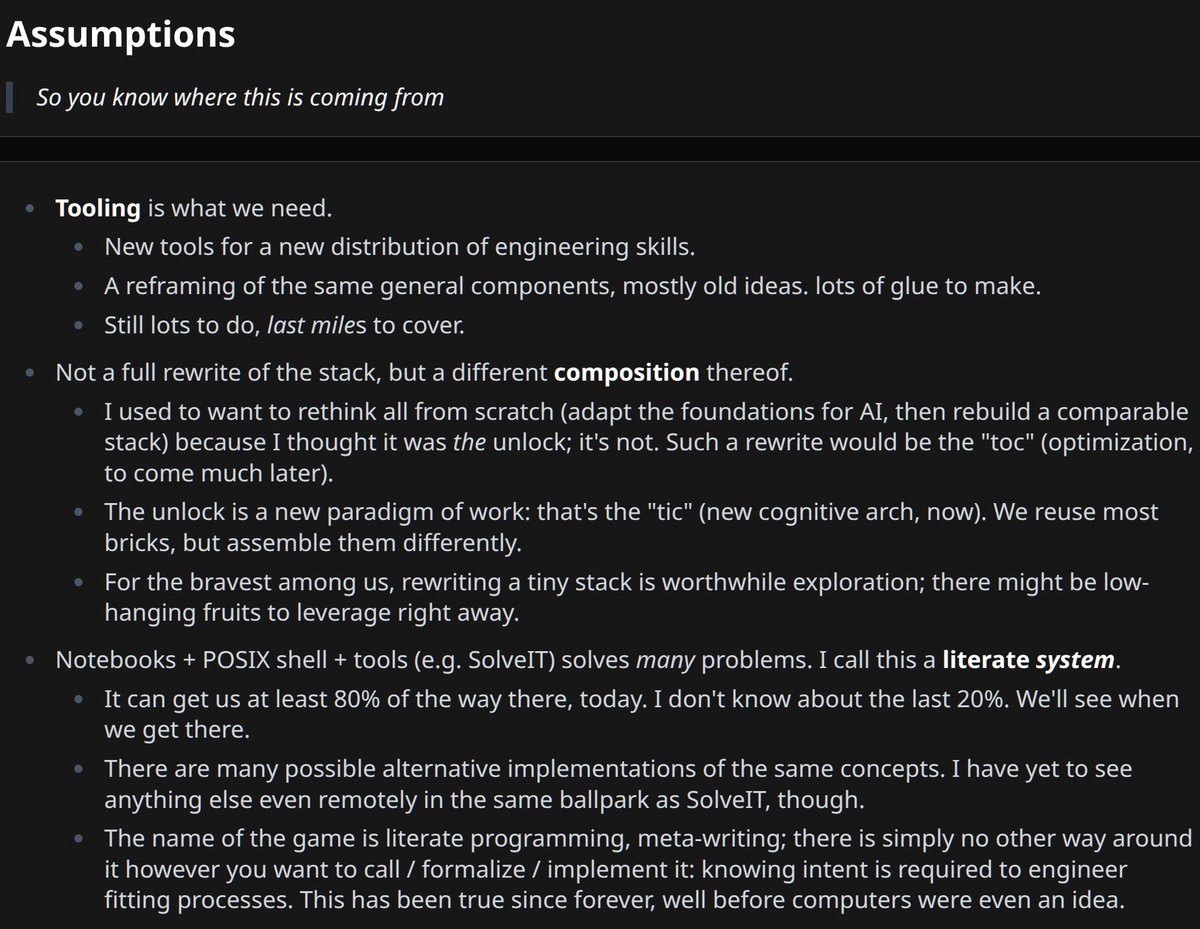
i think that fundamentals matter forever, knowing reality is "evergreen" lol. some things just don't change.
i wrote about this a few months ago, haven't published it (felt long, needed work). but it does answer in full how i see this.
the gist is you can level up with the LLM (thus will have to, because others will) including in programming. but there's also a "last mile" kinda wordpress-easy future for many more people (which is cool, lower barrier of entry).
some ideas i like:
> The bottleneck was always cognition; it still is. So I strive to amplify myself first.
> The LLM is a lever. It applies force in whichever direction I choose. So choose well.
> AI is a shift of skills, not a replacement for sound engineering principles, let alone thinking.
Pics with excerpts relevant to this discussion.
+ link for those who want to read it in full.
(last sections below "What is beauty" are more general about AI; above is about how I use notebooks more specifically)
#what-is-beauty_10" target="_blank" rel="nofollow noopener">share.solve.it.com/d/8d5d18c6213f…

English
be honest: if AI writes most of the code now, is learning to code still worth it?
• yes, fundamentals still matter
• only enough to direct AI
• no, product thinking matters more
• I never really learned
curious how people actually think about this long term.
P.S. my real answer is hidden somewhere in the image, can you find it? 👀
vote or drop your take below. 👇

English
yes, that space in-between, exactly, and i believe that's one way through the bottleneck you describe. being in the field with experienced people is how we've always trained the best craftsmen.
in software world tho, the field is more like SSH + comms, so remote people can team up.
job profiles do change fast before/after disruption by tech. there's so much i see already that will become the basics. yet most people are still very fuzzy about most of it (i'll plead guilty to that, the full-stack AI vertical is very big, and its layers aren't converging/streamlining yet. it's the far west).
whatever model we'll use is, i agree, of little concern in the big picture (even if progress stopped now, which it won't).
English
really appreciate the huge reply. honestly the apprenticeship/guild part resonates with me more than most conversations around AI right now.
a lot of people are acting like access to models is the bottleneck, but i increasingly think the bottleneck is judgment, taste, and learning from people who’ve actually deployed things in messy real environments.
forums/social feeds are great for discovery, but terrible for transmitting deep operational knowledge. schools are often too slow and abstract. there’s probably space for something in between.
English
