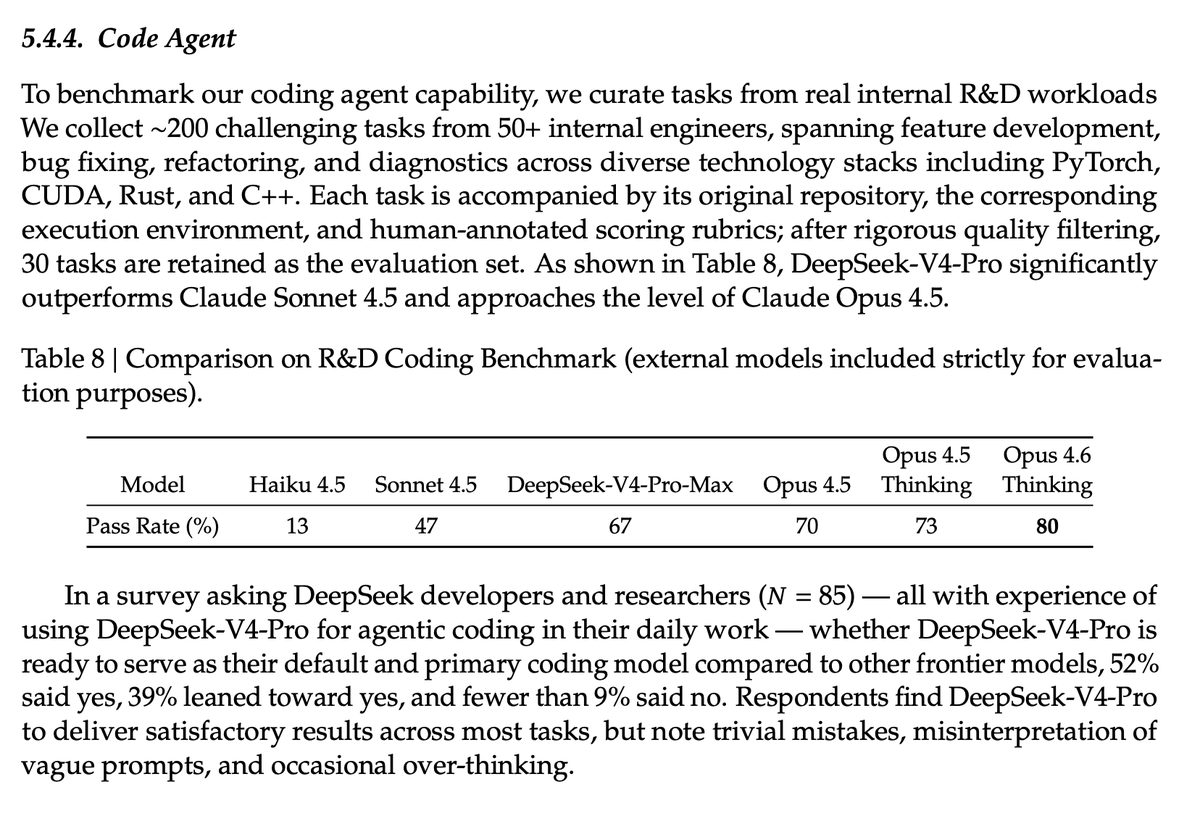
Sabitlenmiş Tweet

Some Amazing startups trying to solve the Data Quality/ Data Governance/ Data Cataloging issue -
1)First, Made in India - @AtlanHQ . @prukalpa wrote an amazing blog on data catalog 3.0. - towardsdatascience.com/data-catalog-3…
they have inMobi as a client 🧐
English