
Abhilash Bandi
514 posts
Abhilash Bandi
@AbhilashTest
Tinkering. Passionate about building quality software. Reformed. Trying to be a Grug Brain Developer.
Home Katılım Şubat 2016
685 Takip Edilen77 Takipçiler
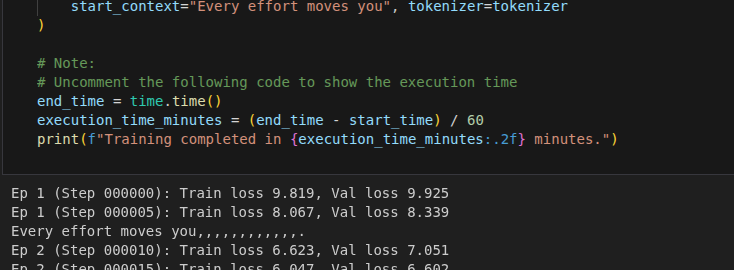
Trained my first LLM (Kinda, thanks to @VizuaraAI courses). Understood multihead attention, LayerNorms, Dropout but the training loop seems fuzzy to me. Need to dig more into training side of things to make it more intutive.
Abhilash Bandi@AbhilashTest
Progress after longtime. Multi head attention is here. Was able to write it from sratch. Learned that attention heads can be mixed for rich representation.
English
Now a days, writing docs doesnt seems to make sense. With coding agents you implement the changes quickly, showcase the chagnes to team/ users, get feedback and iterate.
Coding agents unlocks true Agile development.
Working software over comprehensive documentation
English
@arpit_bhayani I realised this recently when developing auto analysis tool for Spark error logs. But you dont know what your searching for. You will know the terminal error but underlying rootcause is something you need to find.
English

@AnubhutiAILabs @prajdabre Can we replace it directly? Dont we have to train the experts?
English

Replace each dense FFN layer in the transformer with a Mixture-of-Experts (MoE) layer:
• Split the FFN into N smaller expert FFNs so that total parameters stay roughly the same.
• Add a router (gating network) that selects top-k experts (k ≪ N) per token.
• For each token, only compute those selected experts and combine their outputs.
English

Progress after longtime. Multi head attention is here. Was able to write it from sratch. Learned that attention heads can be mixed for rich representation.

Abhilash Bandi@AbhilashTest
Just read the "Attention Is All You Need" paper. Its actually around 10 pages long. Few concepts, I cant grasp yet. But this is the first paper I read end to end. Next step, try to actually implement it and deeply understand whats happening. Stay tuned.. arxiv.org/pdf/1706.03762
English

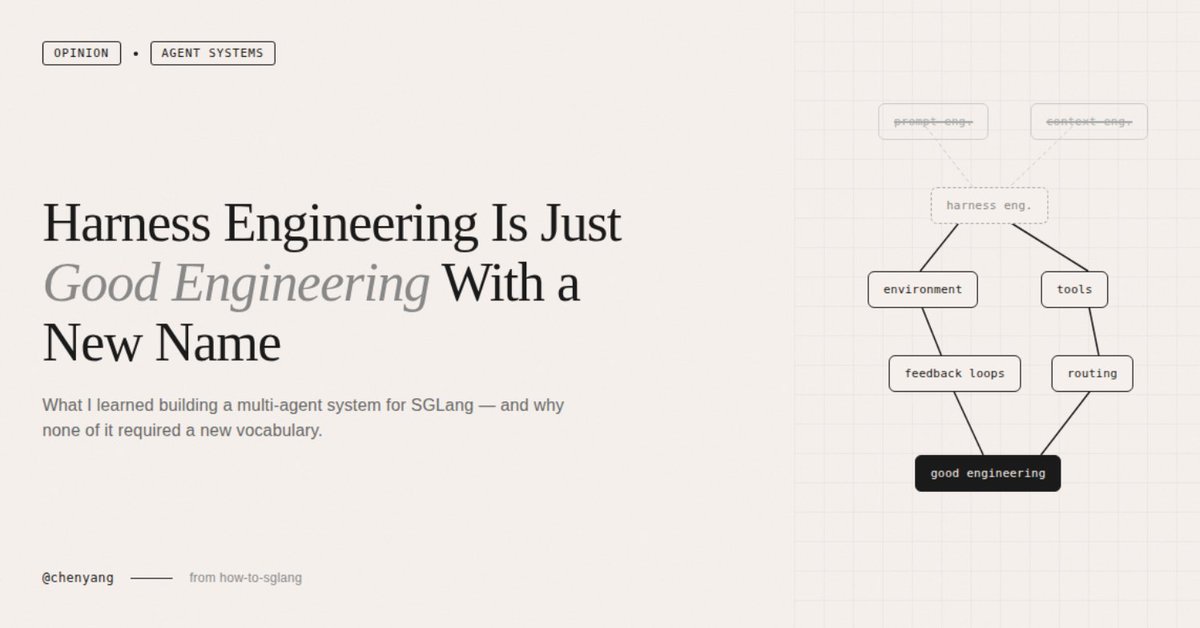
Today I read a lengthy piece on Harness Engineering — tens of thousands of words, almost certainly AI-written. My first reaction wasn't "wow, what a powerful concept." It was "do these people have any ideas beyond coining new terms for old ones?"
I've always been annoyed by this pattern in the AI world — the constant reinvention of existing concepts. From prompt engineering to context engineering, now to harness engineering. Every few months someone coins a new term, writes a 10,000-word essay, sprinkles in a few big-company case studies, and the whole community starts buzzing. But if you actually look at the content, it's the same thing every time:
Design the environment your model runs in — what information it receives, what tools it can use, how errors get intercepted, how memory is managed across sessions. This has existed since the day ChatGPT launched. It doesn't become a new discipline just because someone — for whatever reason — decided to give it a new name.
That said, complaints aside, the research and case studies cited in the article do have value — especially since they overlap heavily with what I've been building with how-to-sglang. So let me use this as an opportunity to talk about the mistakes I've actually made.
Some background first. The most common requests in the SGLang community are How-to Questions — how to deploy DeepSeek-V3 on 8 GPUs, what to do when the gateway can't reach the worker address, whether the gap between GLM-5 INT4 and official FP8 is significant. These questions span an extremely wide technical surface, and as the community grows faster and faster, we increasingly can't keep up with replies. So I started building a multi-agent system to answer them automatically.
The first idea was, of course, the most naive one — build a single omniscient Agent, stuff all of SGLang's docs, code, and cookbooks into it, and let it answer everything.
That didn't work.
You don't need harness engineering theory to explain why — the context window isn't RAM. The more you stuff into it, the more the model's attention scatters and the worse the answers get. An Agent trying to simultaneously understand quantization, PD disaggregation, diffusion serving, and hardware compatibility ends up understanding none of them deeply.
The design we eventually landed on is a multi-layered sub-domain expert architecture. SGLang's documentation already has natural functional boundaries — advanced features, platforms, supported models — with cookbooks organized by model. We turned each sub-domain into an independent expert agent, with an Expert Debating Manager responsible for receiving questions, decomposing them into sub-questions, consulting the Expert Routing Table to activate the right agents, solving in parallel, then synthesizing answers.
Looking back, this design maps almost perfectly onto the patterns the harness engineering community advocates. But when I was building it, I had no idea these patterns had names. And I didn't need to.
1. Progressive disclosure — we didn't dump all documentation into any single agent. Each domain expert loads only its own domain knowledge, and the Manager decides who to activate based on the question type. My gut feeling is that this design yielded far more improvement than swapping in a stronger model ever did. You don't need to know this is called "progressive disclosure" to make this decision. You just need to have tried the "stuff everything in" approach once and watched it fail.
2. Repository as source of truth — the entire workflow lives in the how-to-sglang repo. All expert agents draw their knowledge from markdown files inside the repo, with no dependency on external documents or verbal agreements. Early on, we had the urge to write one massive sglang-maintain.md covering everything. We quickly learned that doesn't work. OpenAI's Codex team made the same mistake — they tried a single oversized AGENTS.md and watched it rot in predictable ways. You don't need to have read their blog to step on this landmine yourself. It's the classic software engineering problem of "monolithic docs always go stale," except in an agent context the consequences are worse — stale documentation doesn't just go unread, it actively misleads the agent.
3. Structured routing — the Expert Routing Table explicitly maps question types to agents. A question about GLM-5 INT4 activates both the Cookbook Domain Expert and the Quantization Domain Expert simultaneously. The Manager doesn't guess; it follows a structured index. The harness engineering crowd calls this "mechanized constraints." I call it normal engineering.
I'm not saying the ideas behind harness engineering are bad. The cited research is solid, the ACI concept from SWE-agent is genuinely worth knowing, and Anthropic's dual-agent architecture (initializer agent + coding agent) is valuable reference material for anyone doing long-horizon tasks. What I find tiresome is the constant coining of new terms — packaging established engineering common sense as a new discipline, then manufacturing anxiety around "you're behind if you don't know this word."
Prompt engineering, context engineering, harness engineering — they're different facets of the same thing. Next month someone will probably coin scaffold engineering or orchestration engineering, write another lengthy essay citing the same SWE-agent paper, and the community will start another cycle of amplification.
What I actually learned from how-to-sglang can be stated without any new vocabulary:
Information fed to agents should be minimal and precise, not maximal. Complex systems should be split into specialized sub-modules, not built as omniscient agents. All knowledge must live in the repo — verbal agreements don't exist. Routing and constraints must be structural, not left to the agent's judgment. Feedback loops should be as tight as possible — we currently use a logging system to record the full reasoning chain of every query, and we've started using Codex for LLM-as-a-judge verification, but we're still far from ideal.
None of this is new. In traditional software engineering, these are called separation of concerns, single responsibility principle, docs-as-code, and shift-left constraints. We're just applying them to LLM work environments now, and some people feel that warrants a new name.
I don't know how many more new terms this field will produce. But I do know that, at least today, we've never achieved a qualitative leap on how-to-sglang by swapping in a stronger model. What actually drove breakthroughs was always improvements at the environment level — more precise knowledge partitioning, better routing logic, tighter feedback loops. Whether you call it harness engineering, context engineering, or nothing at all, it's just good engineering practice. Nothing more, nothing less.
There is one question I genuinely haven't figured out: if model capabilities keep scaling exponentially, will there come a day when models are strong enough to build their own environments? I had this exact confusion when observing OpenClaw — it went from 400K lines to a million in a single month, driven entirely by AI itself. Who built that project's environment? A human, or the AI? And if it was the AI, how many of the design principles we're discussing today will be completely irrelevant in two years?
I don't know. But at least today, across every instance of real practice I can observe, this is still human work — and the most valuable kind.
English
100% agree on this. This unnecessary rebranding of existing good engineering concepts just fuels the hype. I recently implemented a needle in a haystack like problem. I ended up implementing all of these without ever knowing any of these conceptually. Just good engineering principles guiding the design
English
Abhilash Bandi retweetledi

we’re hiring 🚨
looking for a backend engineer (node.js, typescript, AWS) to help build and scale the systems powering an ai product.
you’ll work on real-time pipelines, APIs, infra, and distributed systems alongside a small, high-output team
we’re looking for someone who:
↳ has 2+ years of backend experience (node.js + typescript)
↳ is strong with postgresql, redis, and api design
↳ has hands-on aws experience
↳ understands scalability, performance, and clean system design
bonus if you’ve:
↳ worked on high-scale consumer products
↳ built real-time or distributed systems
comp: ₹30–60 LPA + equity
location: india preferred (remote with travel)
this is not for everyone.
only apply if you have proof of exceptional work
send your proof of work 📥

English
@bryan_johnson Sat-Chit-Ananda
Existence-Consciousness-Bliss
English

This was the most profound experience of my life. I am stunned beyond comprehension. This molecule is without peer.
The 27mg dose opened up what felt like pure consciousness and intelligence. A majestic reveal of existence itself. In all its incomprehensible glory and majesty. It is impossible to explain with words. Whatever you imagine, multiply it by 1,000 and then add infinite width and depth and dimensions.
But entrance was not granted without prerequisite. Existence demanded that I submit. That I say yes; without attachment and without condition. Yes to existence; yes to the dissolution of self; yes to release control; yes, to all.
My ego registered the ask and panicked. It wanted control. It was desperate for control. It pleaded to escape from the torrent of light and essence that threatened to rip my sanity into chards. The urge to eject was overwhelming. Terror thundered throughout my mind and body.
It took everything within me to release. I overcame and was treated with bliss that defies imagination. A euphoria colored with perfect harmony of all things. An orchestra of essence washed over me and swept me up in dance. It was home. The highest aspiration of intelligent life. For some reason, stored and tucked away as the ultimate prize.
A single concept emerged in omnipresence: we cannot grok the preciousness of our existence. Yet it is everything we’ve ever wanted and more. The state we long for without knowing it exists. This caused me great pain and heartache.
A swell of loyalty and devotion emerged inside me, pledging allegiance to existence. To become a warrior and caretaker of life on earth. To protect at any cost the candle of consciousness that has miraculously emerged in this part of the galaxy.
What awaits will wipe all your tears, soothe all your sorrows, and infinitely exceed your wants.
Bryan Johnson@bryan_johnson
English
Abhilash Bandi retweetledi

I will not get into the regulatory/lead-acid battery angle. Speaking purely as an engineer, here is how I see it.
To save costs, most E-rickshaws are built with a handlebar steering system on a single front wheel. This allows them a near-zero turning radius. They can perform a U-turn in a space smaller than a hatchback.
Cos they can turn anywhere, they do turn anywhere. This unpredictable lateral movement breaks the lane-discipline of every other vehicle on the road, forcing everyone behind them to brake, 1 of the primary cause of phantom traffic jams.
Indian Tech & Infra@IndianTechGuide
🚨 Opinion: E-rickshaws are one of the main reasons for city traffic. 🙏
English
I am on team @cursor_ai for long time. I dont even use their composer model.
Tried @claudeai many times but cursor keeps pulling me back. IDK why? Maybe I am not a cli Andy.
AVB@neural_avb
> be cursor > first to market for coding IDEs (with copilot) > $60 million series-a funding > made Dr Karpathy coin "vibe coding" > they are already an RL harness from day 1 > if user "Accepts Edit" - positive reward, if not user's next message is rich feedback > thats the purest form of RLRF (RL with rich feedback) > cursor tab also - pure RLVR (does user accept autocompletion? yes or no) > they shouldve been unstoppable But then... > they had one big tech-debt. they had to rely on other providers (OpenAI, Anth) coz they didnt have any competitve coding models of their own, > Sonnet and Opus costs $$$ via API > make some pricing moves that that have soured people against them > rise of competitors (claude code and now codex) > in came the terminal era: less typing, less editing > people moved from vibe coding to automated agentic coding by 2025. But then... > all this while they had enough analytics to start training their own models > open-weight coding models are already great, many of them have open licenses too for a good base > cursor models wont need to compete on general benchmarks - just basic intelligence + coding & SWE benches are all they need > did I mention they have had a banger team for a while? And today... > they have released Composer 2 now which beats Opus 4.6 and competes with GPT 5.4 high in a fraction of the cost > hopefully the usage issues will reduce because they have a good model that's optimized for their harness + runs cheap this whole thing is playing out like a movie in my head
English
@arpit_bhayani Congratulations Arpit, Now we know who to contact for any payment failures on razorpay ;)
English
Joined Razorpay as Principal Engineer II :)
From being a long-time customer to now building parts of the system - it's a full circle. Fintech is a new territory for me - time to get under the hood of how money actually moves.
New domain, same guarantees - availability, correctness, performance - just with real money on the line.

English
Just wrote my first mutation test. Can see how powerful it is for brownfield applications.
English
@VicVijayakumar Yah.. the defensive code proliferates especially in untyped languages.
English

@AbhilashTest When I say defensive I don’t just mean adding stricter types.
English
Code becoming cheap has introduced a problem of slop masquerading as defensive programming & increased reliability.
We used to make tradeoffs all the time- “I can spend 4 hours implementing redundancy in this code for something that is extremely unlikely to happen, or ship this simple fix right now with alerting in place”.
But if the hardening will only take you 10 seconds of typing, why risk leaving edge cases unhandled?
AI code review is exacerbating this problem by surfacing extremely unlikely scenarios as critical edge cases that must be fixed asap. The comment looks sus, but time is cheap. The tradeoff is 10 seconds of your time vs getting paged at 4am.
You can debate it, or you can tell your agent to handle the review & implement fixes while you go make a latte.
English

How LLMs actually work!
Recently gave a 2-hour long talk on this. 42 slides, all yours 👇
English
Abhilash Bandi retweetledi

Sam Altman said people saying “please” and “thank you” to ChatGPT costs OpenAI tens of millions of dollars a year in compute. 67% of Americans do it anyway.
Run the math on why.
A 2024 Waseda University study tested LLM responses across politeness levels in English, Chinese, and Japanese. Impolite prompts produced measurably worse outputs: more bias, more errors, more refusals. Moderate politeness consistently beat both extremes.
The mechanism makes sense once you see it. Polite prompts pattern-match to higher-quality training data. When you write “Could you help me structure this analysis?”, the model pulls from professional, well-reasoned text. When you write “give me the answer,” it pulls from Reddit.
Google DeepMind’s Murray Shanahan explained it simply: the model is role-playing a smart intern. Treat the intern like a colleague, you get colleague-quality work. Bark orders, you get minimum-viable compliance.
Now look at the cost side. OpenAI handles over a billion queries daily. Each GPT-4 query uses roughly 2.9 watt-hours, ten times a Google search. But OpenAI just raised $40 billion at a $300 billion valuation. Tens of millions in politeness tokens is a rounding error on a rounding error.
67% of users do it anyway, and 55% of them say it’s because it’s “the right thing to do.” They’re maintaining a behavioral habit that governs every other interaction in their life. The parent who teaches their kid to say please to Alexa isn’t doing it for Alexa. They’re doing it because the alternative is raising someone who learns that being rude gets faster results.
Telling 900 million people to stop saying thank you so OpenAI can save 0.01% of operating costs is the most engineer-brained optimization take on the internet. You’re training yourself to treat every interaction as a transaction. And that habit doesn’t stay in the chat window.
Venkatesh@Venkydotdev
STOP SAYING THANK YOU TO AI STOP SAYING THANK YOU TO AI STOP SAYING THANK YOU TO AI STOP SAYING THANK YOU TO AI STOP SAYING THANK YOU TO AI STOP SAYING THANK YOU TO AI STOP SAYING THANK YOU TO AI STOP SAYING THANK YOU TO AI STOP SAYING THANK YOU TO AI STOP SAYING THANK YOU TO AI
English