Zihao Ye retweetledi

Zihao Ye
230 posts



This paper is the same as the DeepCrossAttention (DCA) method from more than a year ago: arxiv.org/abs/2502.06785. As far as I understood, here there is no innovation to be excited about, and yet surprisingly there is no citation and discussion about DCA! The level of redundancy in LLM research and then the hype on X is getting worse and worse! DeepCrossAttention is built based on the intuition that depth-wise cross-attention allows for richer interactions between layers at different depths. DCA further provides both empirical and theoretical results to support this approach.



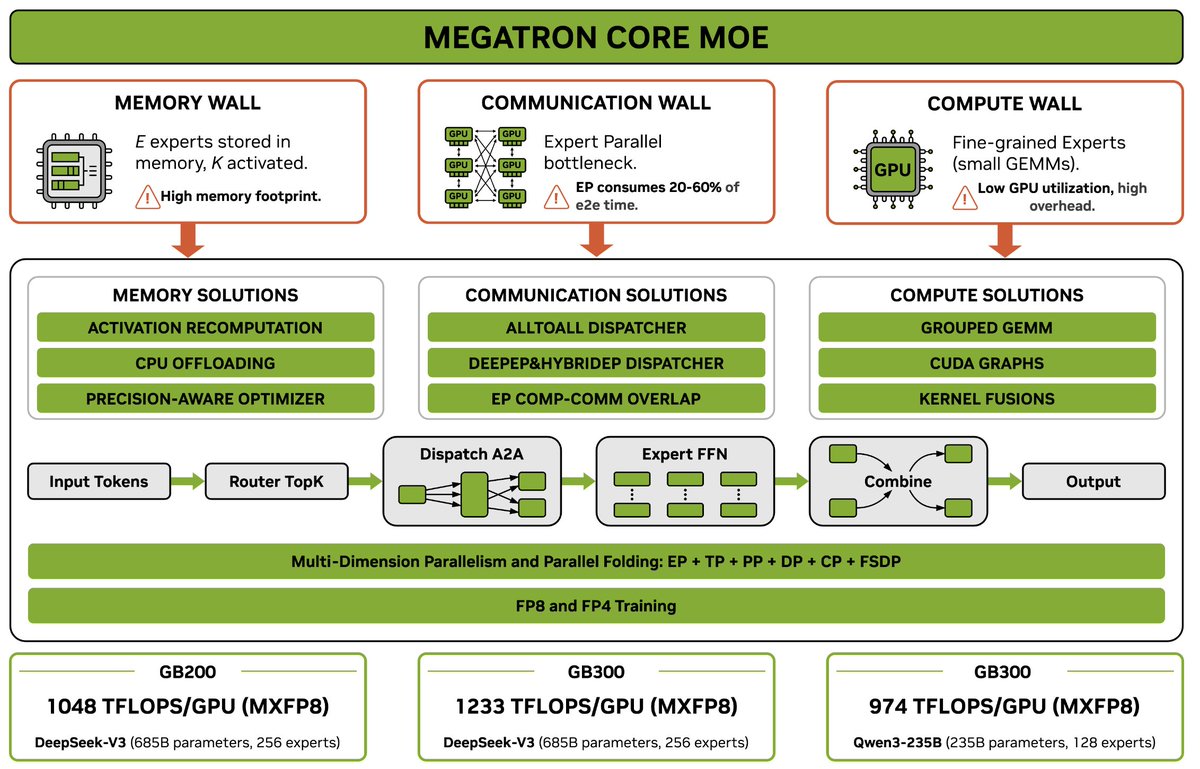






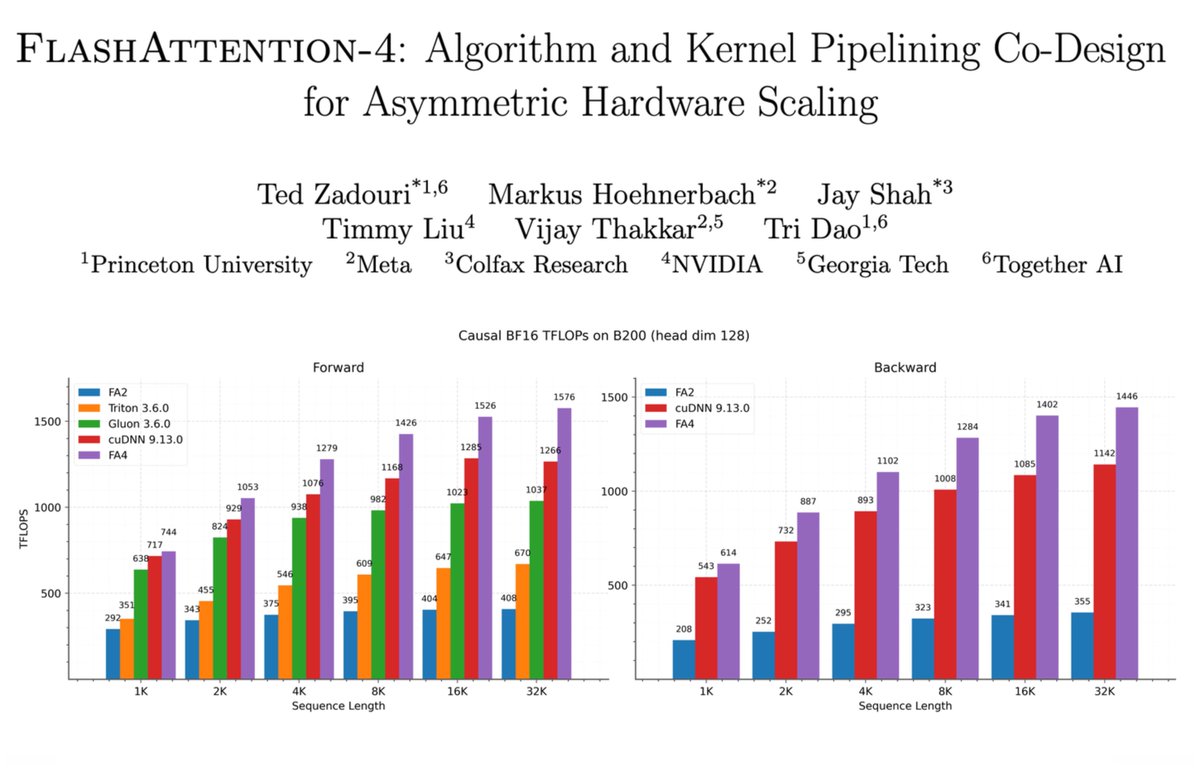
Exciting day for FlashAttention fans! If you haven't read the arxiv paper on FA4 you should! In tandem we have been working on bringing these same perf benefits to FlexAttention, see the blog for more details

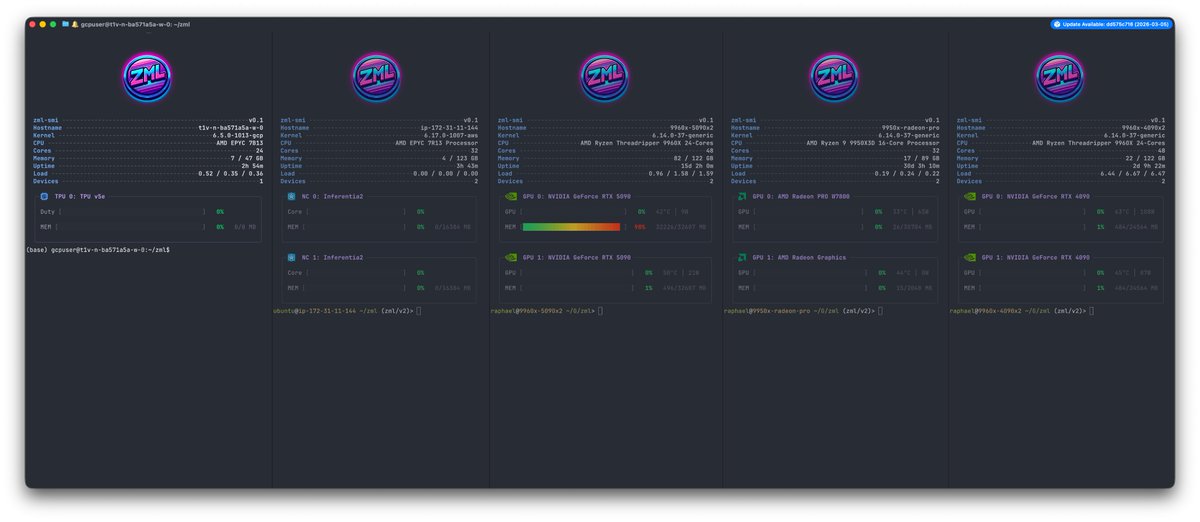
zml-smi